{"title":"基因组学中的标记化和深度学习架构:全面回顾。","authors":"Conrad Testagrose, Christina Boucher","doi":"10.1016/j.csbj.2025.07.038","DOIUrl":null,"url":null,"abstract":"<p><p>The development of modern DNA sequencing technologies has resulted in the rapid growth of genomic data. Alongside the collection of this data, there is an increasing need for the development of modern computational tools leveraging this data for tasks including but not limited to antimicrobial resistance and gene annotation. Current deep learning architectures and tokenization techniques have been explored for the extraction of meaningful underlying information contained within this sequencing data. We aim to survey current and foundational literature surrounding the area of deep learning architectures and tokenization techniques in the field of genomics. Our survey of the literature outlines that significant work remains in developing efficient tokenization techniques that can capture or model underlying motifs within DNA sequences. While deep learning models have become more efficient, many current tokenization methods either reduce scalability through naive sequence representation, incorrectly model motifs or are borrowed directly from NLP tasks for use with biological sequences. Current and future model architectures should seek to implement and support more advanced, and biologically relevant, tokenization techniques to more effectively model the underlying information in biological sequencing data.</p>","PeriodicalId":10715,"journal":{"name":"Computational and structural biotechnology journal","volume":"27 ","pages":"3547-3555"},"PeriodicalIF":4.1000,"publicationDate":"2025-07-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12356405/pdf/","citationCount":"0","resultStr":"{\"title\":\"Tokenization and deep learning architectures in genomics: A comprehensive review.\",\"authors\":\"Conrad Testagrose, Christina Boucher\",\"doi\":\"10.1016/j.csbj.2025.07.038\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The development of modern DNA sequencing technologies has resulted in the rapid growth of genomic data. Alongside the collection of this data, there is an increasing need for the development of modern computational tools leveraging this data for tasks including but not limited to antimicrobial resistance and gene annotation. Current deep learning architectures and tokenization techniques have been explored for the extraction of meaningful underlying information contained within this sequencing data. We aim to survey current and foundational literature surrounding the area of deep learning architectures and tokenization techniques in the field of genomics. Our survey of the literature outlines that significant work remains in developing efficient tokenization techniques that can capture or model underlying motifs within DNA sequences. While deep learning models have become more efficient, many current tokenization methods either reduce scalability through naive sequence representation, incorrectly model motifs or are borrowed directly from NLP tasks for use with biological sequences. Current and future model architectures should seek to implement and support more advanced, and biologically relevant, tokenization techniques to more effectively model the underlying information in biological sequencing data.</p>\",\"PeriodicalId\":10715,\"journal\":{\"name\":\"Computational and structural biotechnology journal\",\"volume\":\"27 \",\"pages\":\"3547-3555\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2025-07-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12356405/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational and structural biotechnology journal\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1016/j.csbj.2025.07.038\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and structural biotechnology journal","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1016/j.csbj.2025.07.038","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
Tokenization and deep learning architectures in genomics: A comprehensive review.
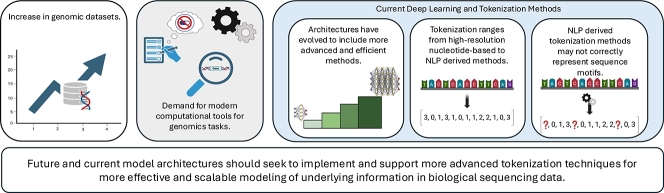
The development of modern DNA sequencing technologies has resulted in the rapid growth of genomic data. Alongside the collection of this data, there is an increasing need for the development of modern computational tools leveraging this data for tasks including but not limited to antimicrobial resistance and gene annotation. Current deep learning architectures and tokenization techniques have been explored for the extraction of meaningful underlying information contained within this sequencing data. We aim to survey current and foundational literature surrounding the area of deep learning architectures and tokenization techniques in the field of genomics. Our survey of the literature outlines that significant work remains in developing efficient tokenization techniques that can capture or model underlying motifs within DNA sequences. While deep learning models have become more efficient, many current tokenization methods either reduce scalability through naive sequence representation, incorrectly model motifs or are borrowed directly from NLP tasks for use with biological sequences. Current and future model architectures should seek to implement and support more advanced, and biologically relevant, tokenization techniques to more effectively model the underlying information in biological sequencing data.
期刊介绍:
Computational and Structural Biotechnology Journal (CSBJ) is an online gold open access journal publishing research articles and reviews after full peer review. All articles are published, without barriers to access, immediately upon acceptance. The journal places a strong emphasis on functional and mechanistic understanding of how molecular components in a biological process work together through the application of computational methods. Structural data may provide such insights, but they are not a pre-requisite for publication in the journal. Specific areas of interest include, but are not limited to:
Structure and function of proteins, nucleic acids and other macromolecules
Structure and function of multi-component complexes
Protein folding, processing and degradation
Enzymology
Computational and structural studies of plant systems
Microbial Informatics
Genomics
Proteomics
Metabolomics
Algorithms and Hypothesis in Bioinformatics
Mathematical and Theoretical Biology
Computational Chemistry and Drug Discovery
Microscopy and Molecular Imaging
Nanotechnology
Systems and Synthetic Biology

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


