Samson Mataraso, Shreya D'Souza, David Seong, Eloïse Berson, Camilo Espinosa, Nima Aghaeepour
{"title":"电子健康记录基础模型预训练策略的基准测试。","authors":"Samson Mataraso, Shreya D'Souza, David Seong, Eloïse Berson, Camilo Espinosa, Nima Aghaeepour","doi":"10.1093/jamiaopen/ooaf090","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Our objective is to compare different pre-training strategies for electronic health record (EHR) foundation models.</p><p><strong>Materials and methods: </strong>We evaluated three approaches using a transformer-based architecture: baseline (no pre-training), self-supervised pre-training with masked language modeling, and supervised pre-training. The models were assessed on their ability to predict both major adverse cardiac events and mortality occurring within 12 months. The pre-training cohort was 405 679 patients prescribed antihypertensives and the fine tuning cohort was 5525 patients who received doxorubicin.</p><p><strong>Results: </strong>Task-specific supervised pre-training achieved superior performance (AUROC 0.70, AUPRC 0.23), outperforming both self-supervised pre-training and the baseline. However, when the model was evaluated on the task of 12-month mortality prediction, the self-supervised model performed best.</p><p><strong>Discussion: </strong>While supervised pre-training excels when aligned with downstream tasks, self-supervised approaches offer more generalized utility.</p><p><strong>Conclusion: </strong>Pre-training strategy selection should consider intended applications, data availability, and transferability requirements.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 4","pages":"ooaf090"},"PeriodicalIF":3.4000,"publicationDate":"2025-08-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12349770/pdf/","citationCount":"0","resultStr":"{\"title\":\"Benchmarking of pre-training strategies for electronic health record foundation models.\",\"authors\":\"Samson Mataraso, Shreya D'Souza, David Seong, Eloïse Berson, Camilo Espinosa, Nima Aghaeepour\",\"doi\":\"10.1093/jamiaopen/ooaf090\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Our objective is to compare different pre-training strategies for electronic health record (EHR) foundation models.</p><p><strong>Materials and methods: </strong>We evaluated three approaches using a transformer-based architecture: baseline (no pre-training), self-supervised pre-training with masked language modeling, and supervised pre-training. The models were assessed on their ability to predict both major adverse cardiac events and mortality occurring within 12 months. The pre-training cohort was 405 679 patients prescribed antihypertensives and the fine tuning cohort was 5525 patients who received doxorubicin.</p><p><strong>Results: </strong>Task-specific supervised pre-training achieved superior performance (AUROC 0.70, AUPRC 0.23), outperforming both self-supervised pre-training and the baseline. However, when the model was evaluated on the task of 12-month mortality prediction, the self-supervised model performed best.</p><p><strong>Discussion: </strong>While supervised pre-training excels when aligned with downstream tasks, self-supervised approaches offer more generalized utility.</p><p><strong>Conclusion: </strong>Pre-training strategy selection should consider intended applications, data availability, and transferability requirements.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"8 4\",\"pages\":\"ooaf090\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2025-08-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12349770/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooaf090\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf090","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Benchmarking of pre-training strategies for electronic health record foundation models.
Objective: Our objective is to compare different pre-training strategies for electronic health record (EHR) foundation models.
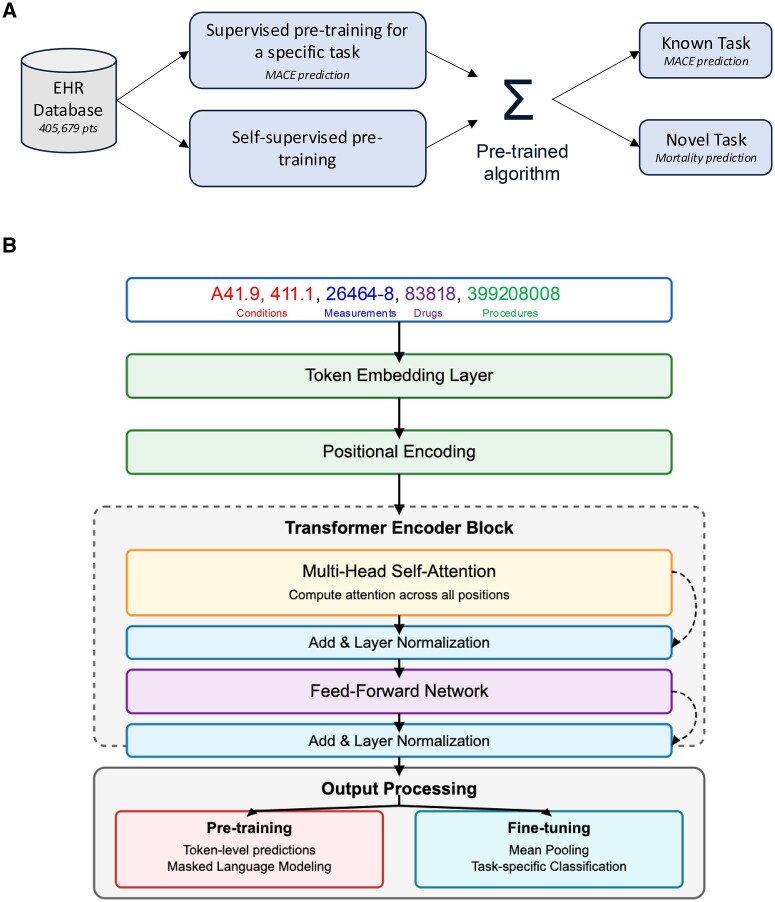
Materials and methods: We evaluated three approaches using a transformer-based architecture: baseline (no pre-training), self-supervised pre-training with masked language modeling, and supervised pre-training. The models were assessed on their ability to predict both major adverse cardiac events and mortality occurring within 12 months. The pre-training cohort was 405 679 patients prescribed antihypertensives and the fine tuning cohort was 5525 patients who received doxorubicin.
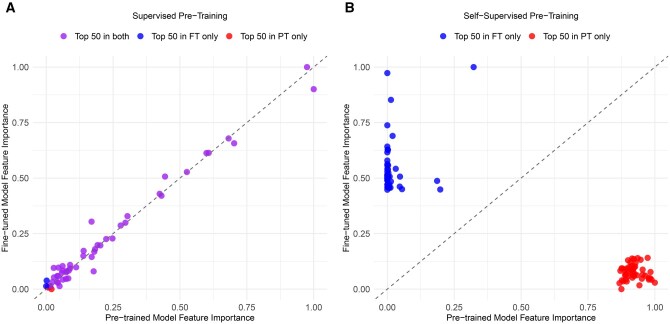
Results: Task-specific supervised pre-training achieved superior performance (AUROC 0.70, AUPRC 0.23), outperforming both self-supervised pre-training and the baseline. However, when the model was evaluated on the task of 12-month mortality prediction, the self-supervised model performed best.
Discussion: While supervised pre-training excels when aligned with downstream tasks, self-supervised approaches offer more generalized utility.
Conclusion: Pre-training strategy selection should consider intended applications, data availability, and transferability requirements.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


