形状模板与广义相机
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
本文提出了一种由多台摄像机观测到的三维形状与二维关键点非刚性匹配的新方法。3D形状与观察到的2D关键点的非刚性配准,即模板形状(SfT),已经广泛研究使用单个图像,但SfT与来自多相机的信息联合为扩展已知用例的范围开辟了新的方向,例如医学成像中的3D形状配准和手持相机的配准,仅举几例。我们用广义摄像机模型来表示这种多摄像机设置;因此,观察任何变形物体的任何透视或正射影相机集合都可以被注册。对于这种SfT,我们提出了多种方法:第一种方法,对应的关键点位于来自空间中已知3D点的方向矢量上;第二种方法,对应的关键点位于来自空间中未知3D点的方向矢量上,但在某些局部参考帧中具有已知的方向;第三种方法,除了对应之外,成像对象的轮廓也是已知的。总之,这些形成了通用相机的SfT问题的第一组解决方案。广义相机的SfT背后的关键思想是通过估计变形形状来提高重建精度,同时利用变形物体的多个视图之间的相互约束的附加信息。基于对应的方法用凸规划求解,而基于轮廓的方法是对凸解结果的迭代改进。我们在许多合成数据和实际数据上证明了我们提出的方法的准确性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
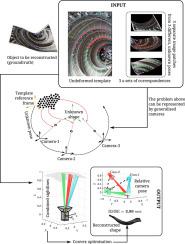
Shape-from-template with generalised camera
This article presents a new method for non-rigidly registering a 3D shape to 2D keypoints observed by a constellation of multiple cameras. Non-rigid registration of a 3D shape to observed 2D keypoints, i.e., Shape-from-Template (SfT), has been widely studied using single images, but SfT with information from multiple-cameras jointly opens new directions for extending the scope of known use-cases such as 3D shape registration in medical imaging and registration from hand-held cameras, to name a few. We represent such multi-camera setup with the generalised camera model; therefore any collection of perspective or orthographic cameras observing any deforming object can be registered. We propose multiple approaches for such SfT: the first approach where the corresponded keypoints lie on a direction vector from a known 3D point in space, the second approach where the corresponded keypoints lie on a direction vector from an unknown 3D point in space but with known orientation w.r.t some local reference frame, and a third approach where, apart from correspondences, the silhouette of the imaged object is also known. Together, these form the first set of solutions to the SfT problem with generalised cameras. The key idea behind SfT with generalised camera is the improved reconstruction accuracy from estimating deformed shape while utilising the additional information from the mutual constraints between multiple views of a deformed object. The correspondence-based approaches are solved with convex programming while the silhouette-based approach is an iterative refinement of the results from the convex solutions. We demonstrate the accuracy of our proposed methods on many synthetic and real data1.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


