肿瘤大语言模型(LLMs)的开发和评估:范围综述。
摘要
大型语言模型(llm)是人工智能(AI)的一个重要发展,它在各种文本分析和生成任务的性能方面不断展示出开创性的改进。在肿瘤学方面,法学硕士应用的系统研究是有限的。我们的范围审查探讨了法学硕士在肿瘤学中的应用,以确定(1)与癌症/肿瘤类型相关的法学硕士应用的性质,(2)法学硕士所解决的癌症护理阶段,(3)在这些应用中使用了哪些法学硕士,(4)使用的数据集的来源和预处理,(5)用于优化法学硕士性能的技术,(6)评估方法。(7)这些法学硕士应用程序的作者指出的共同限制,并研究其在研究和实践中的影响。图书馆员协助检索了以下数据库:美国计算机协会(ACM)、Embase、Engineering Village、IEEE explore、Medline、Scopus、SPIE和Web of Science,检索截止日期为2024年1月12日。本次检索的预印本如果在2024年2月29日之前发表/接受,则被视为预印本。从最初的14863篇文章中,最终纳入了60篇。我们的研究结果表明,法学硕士大多在不同的肿瘤学相关应用中进行评估。基于生成式预训练变压器(GPT)的法学模型应用最为广泛。在提供或暗示癌症治疗阶段的研究子集中,治疗和诊断是包括最多的阶段。用于开发和评价的数据从患者健康记录、综合患者记录、研究和专业协会出版物扩展到社交媒体。在一些研究中,即时设计和工程作为数据预处理步骤进行。临床医生、培训生、研究人员和患者是应用程序针对的各种用户。在为肿瘤学方面开发llm的17%的研究中,通常通过预训练和微调进行域适应,并导致性能提高。法学硕士的性能评估包括使用标准的、经过验证的、非标准化的和/或定制的性能指标,考虑到各种结构,而不是准确性。六个主要主题出现了局限性,包括概括性/适用性,样本量,偏见和主观性以及评估指标的局限性。这篇综述强调,法学硕士,特定于肿瘤学方面,不如通用法学硕士常见。应用领域是异构的,使用了不同的数据源,针对不同的用户,导致了不同的评估方法。尽管法学硕士在肿瘤学中的应用多种多样,但未来的研究需要解决这些应用的有限泛化性,减少偏见和主观性,以及评估方法的标准化。法学硕士在肿瘤学领域的未来应用应该包括开发专门针对肿瘤学的法学硕士,以缓解知识差距,并扩展到迄今为止尚未考虑的肿瘤学培训和实践的各个领域。
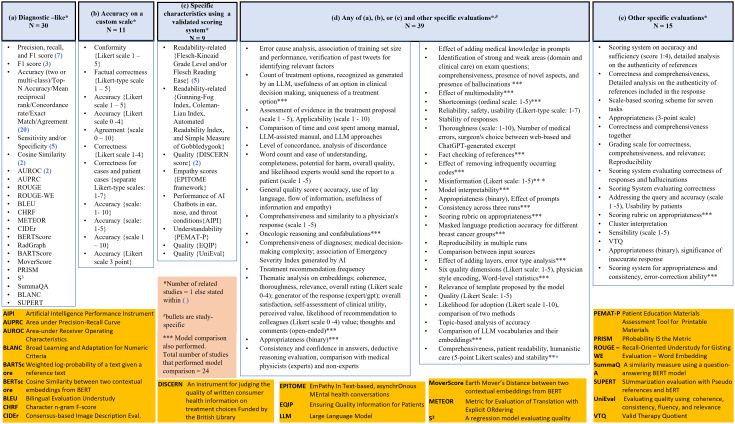
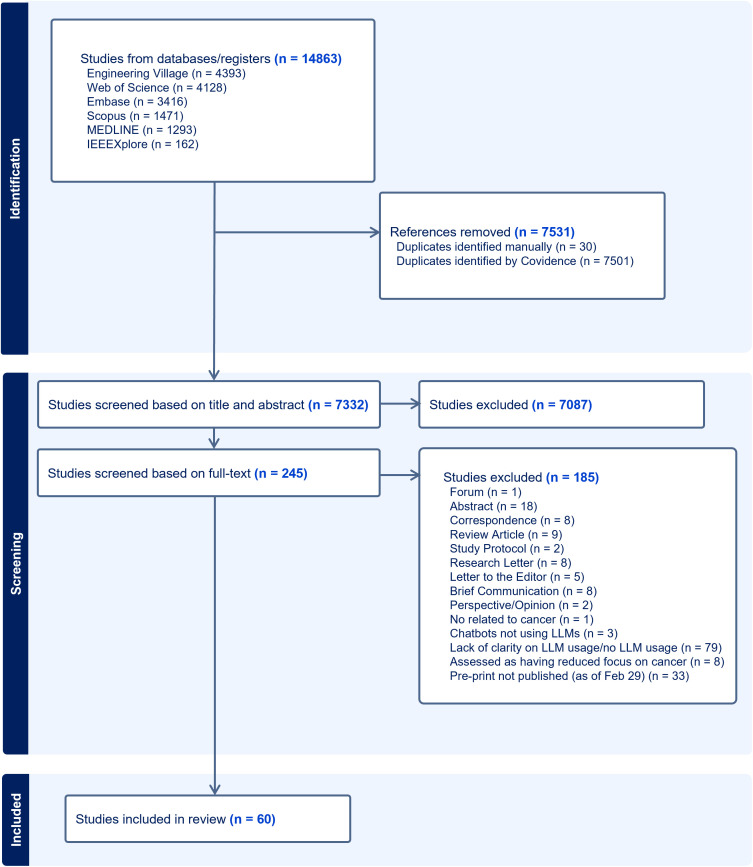
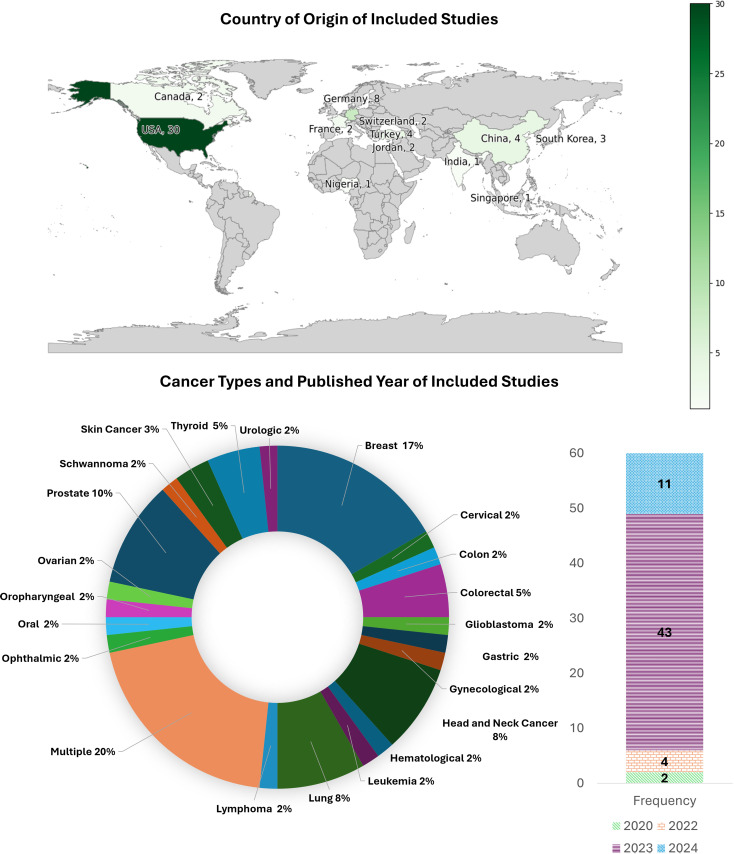
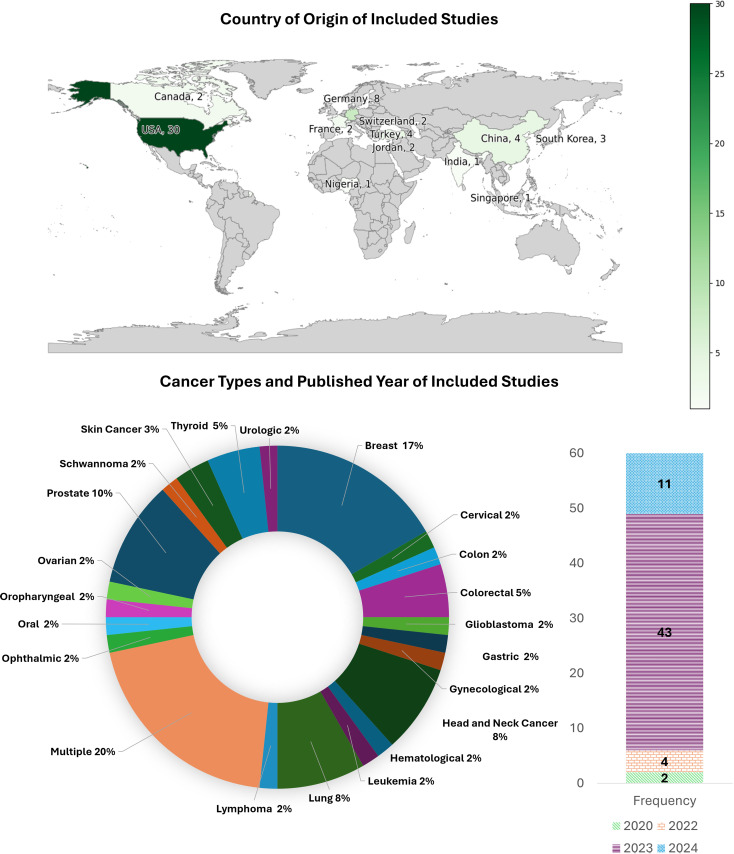
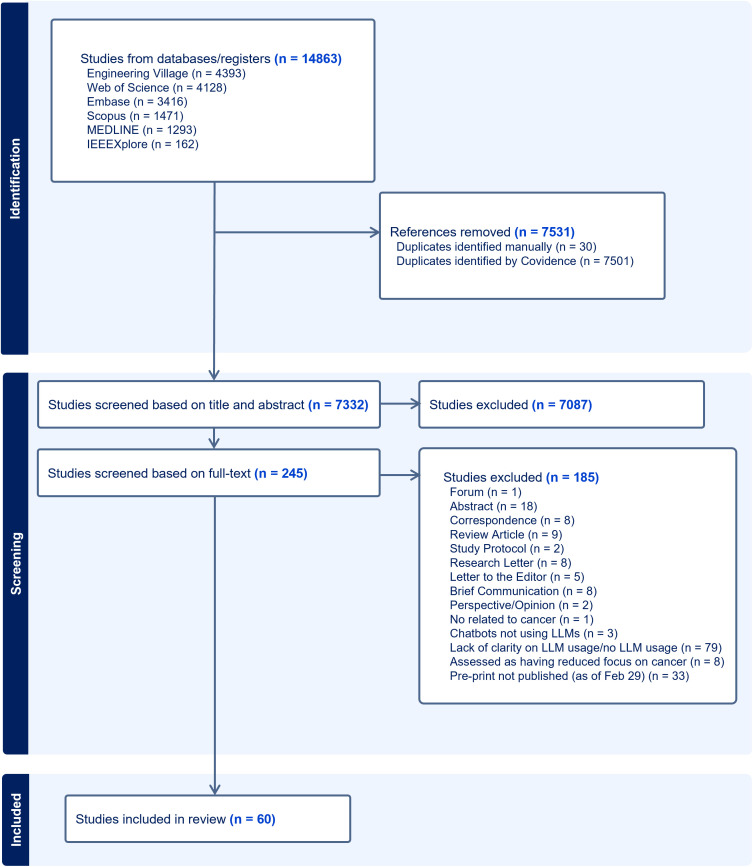
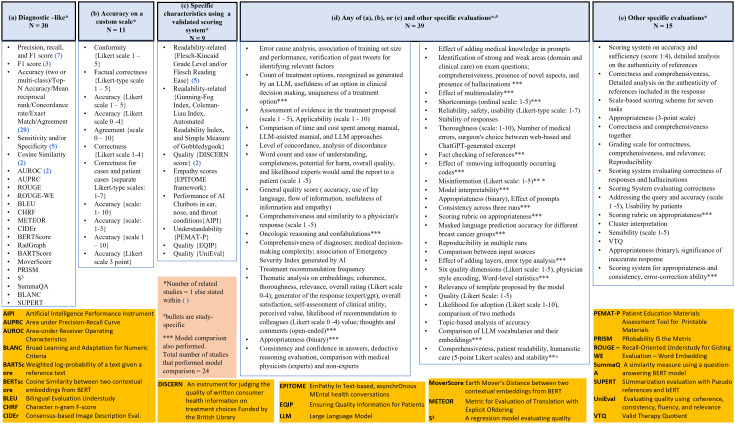
Large language models (LLMs), a significant development in artificial intelligence (AI), are continuing to demonstrate seminal improvement in performance for various text analysis and generation tasks. There are limited systematic studies on LLM applications that were developed/evaluated in relevance to oncology. Our scoping review explores applications of LLMs in oncology to determine (1) the nature of LLM applications relevant to a cancer/tumor type, (2) the phases of cancer care addressed by the LLMs, (3) which LLMs were used in these applications, (4) the sources and pre-processing of datasets used, (5) the techniques used to optimize the performance of LLMs, (6) the methods of evaluation, and (7) the common limitations noted by the authors of these LLM applications and to study their implications in research and practice. A librarian-assisted search was performed across the following databases: Association for Computing Machinery (ACM), Embase, Engineering Village, IEEE Xplore, Medline, Scopus, SPIE and Web of Science till Jan 12, 2024. Pre-prints from this search were considered if they were published/accepted by Feb 29, 2024. From the initial search of 14863 articles, 60 were finally included. Our results demonstrated that LLMs were mostly evaluated across a diverse set of oncology-related applications. Generative pre-trained transformer (GPT)-based LLMs were mostly used. In the subset of studies where the phase(s) of cancer care was/were provided or implied, treatment and diagnosis were the most included phases. Data for development and evaluation extended from patient health records, synthetic patient records, research and professional society publications to social media. Prompt-designing and engineering were performed as data pre-processing steps in several studies. Clinicians, trainees, researchers, and patients were among the variety of users targeted by the applications. In the17% studies that developed LLMs for oncological aspects, domain adaptation through pre-training and fine-tuning were often performed and resulted in performance improvement. The evaluation of an LLM's performance involved usage of both standard, validated, non-standardized, and/or customized performance measures considering a variety of constructs, other than accuracy. Six primary themes emerged as limitations including limitation of generalizability/applicability, sample size, bias and subjectivity, and evaluation metrics. This review highlights that LLMs, specific to oncological aspects, are less common than general-purpose LLMs. The application areas were heterogeneous, used diverse data sources, were directed towards a variety of users, and resulted in variety of evaluation methods. Despite the diversity of LLM applications in oncology, future research needs to address the limited generalizability of these applications, mitigation of bias and subjectivity, and standardization of evaluation methodologies. Future applications of LLMs in oncology should include developing oncology-specific LLMs that can mitigate knowledge gaps and extend to diverse areas of oncology training and practice not considered so far.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


