Elina Väyrynen, Otso Tirkkonen, Henna Tiensuu, Jaakko Suutala, Vuokko Anttonen, Marja-Liisa Laitala, Katri Kukkola, Saujanya Karki
{"title":"基于过采样技术的有限数据场景下机器学习算法的开发与验证,用于预测当前和未来的恢复性治疗需求。","authors":"Elina Väyrynen, Otso Tirkkonen, Henna Tiensuu, Jaakko Suutala, Vuokko Anttonen, Marja-Liisa Laitala, Katri Kukkola, Saujanya Karki","doi":"10.2196/75117","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Untreated dental caries is the most common health condition worldwide. Therefore, new strategies need to be developed to reduce the manifestations of dental caries.</p><p><strong>Objective: </strong>This study aimed to develop and test a machine learning (ML) algorithm for detecting present and predicting future carious lesions in the adolescent population using a set of easy-to-collect predictive variables. In addition, this study aimed to deal with an imbalanced and small dataset using an oversampling method.</p><p><strong>Methods: </strong>This population-based study was conducted among secondary schoolchildren, aged between 13 and 17 years, from the northern parts of Finland in 2022. After meeting the inclusion criteria, a total of 218 participants were included in this study. The inclusion criteria consisted of participants having completed a web-based risk assessment questionnaire and having undergone a clinical examination at public health care services. Dental caries (International Caries Detection and Assessment System [ICDAS] scores of 4, 5, and 6; ie, ICDAS 4-6) and active initial caries (ICDAS 2+, 3+) were considered as outcomes. Several predictors, such as behavioral and dietary habits, were included. An extreme gradient boosting model was developed, tested, and assessed for its predictive performance. A 4-fold cross-validation was performed using the nested resampling technique. The random oversampling examples method and the k-nearest neighbors classifiers were used for all 4 folds. The mean (SD) performance of all the folds was computed.</p><p><strong>Results: </strong>Dental caries (ICDAS 2+,3+,4-6) were prevalent in 65.6% (143/218) of the participants. The mean area under the curve was 0.77 (SD 0.04) and the mean F<sub>1</sub>-score was 0.82 (SD 0.06) for the extreme gradient boosting model. Similarly, the mean area under the curve and mean F<sub>1</sub>-scores after oversampling were 0.74 (SD 0.05) and 0.79 (SD 0.04), respectively. The Shapley additive explanation values were calculated for all 4 folds to assess feature importance, revealing that previous dental fillings were the feature most strongly associated with the need for restorative treatment.</p><p><strong>Conclusions: </strong>On the basis of the performance metrics, the ML algorithm developed and tested in this study can be considered good. The ML algorithm could serve as a cost-effective screening tool for dental professionals to identify the risk of future restorative treatment needs. However, future studies with longitudinal cohorts and longitudinal data, along with external validation for generalizability, are needed to validate our model.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":" ","pages":"e75117"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12426571/pdf/","citationCount":"0","resultStr":"{\"title\":\"A Machine Learning Algorithm With an Oversampling Technique in Limited Data Scenarios for the Prediction of Present and Future Restorative Treatment Need: Development and Validation Study.\",\"authors\":\"Elina Väyrynen, Otso Tirkkonen, Henna Tiensuu, Jaakko Suutala, Vuokko Anttonen, Marja-Liisa Laitala, Katri Kukkola, Saujanya Karki\",\"doi\":\"10.2196/75117\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Untreated dental caries is the most common health condition worldwide. Therefore, new strategies need to be developed to reduce the manifestations of dental caries.</p><p><strong>Objective: </strong>This study aimed to develop and test a machine learning (ML) algorithm for detecting present and predicting future carious lesions in the adolescent population using a set of easy-to-collect predictive variables. In addition, this study aimed to deal with an imbalanced and small dataset using an oversampling method.</p><p><strong>Methods: </strong>This population-based study was conducted among secondary schoolchildren, aged between 13 and 17 years, from the northern parts of Finland in 2022. After meeting the inclusion criteria, a total of 218 participants were included in this study. The inclusion criteria consisted of participants having completed a web-based risk assessment questionnaire and having undergone a clinical examination at public health care services. Dental caries (International Caries Detection and Assessment System [ICDAS] scores of 4, 5, and 6; ie, ICDAS 4-6) and active initial caries (ICDAS 2+, 3+) were considered as outcomes. Several predictors, such as behavioral and dietary habits, were included. An extreme gradient boosting model was developed, tested, and assessed for its predictive performance. A 4-fold cross-validation was performed using the nested resampling technique. The random oversampling examples method and the k-nearest neighbors classifiers were used for all 4 folds. The mean (SD) performance of all the folds was computed.</p><p><strong>Results: </strong>Dental caries (ICDAS 2+,3+,4-6) were prevalent in 65.6% (143/218) of the participants. The mean area under the curve was 0.77 (SD 0.04) and the mean F<sub>1</sub>-score was 0.82 (SD 0.06) for the extreme gradient boosting model. Similarly, the mean area under the curve and mean F<sub>1</sub>-scores after oversampling were 0.74 (SD 0.05) and 0.79 (SD 0.04), respectively. The Shapley additive explanation values were calculated for all 4 folds to assess feature importance, revealing that previous dental fillings were the feature most strongly associated with the need for restorative treatment.</p><p><strong>Conclusions: </strong>On the basis of the performance metrics, the ML algorithm developed and tested in this study can be considered good. The ML algorithm could serve as a cost-effective screening tool for dental professionals to identify the risk of future restorative treatment needs. However, future studies with longitudinal cohorts and longitudinal data, along with external validation for generalizability, are needed to validate our model.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\" \",\"pages\":\"e75117\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-08-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12426571/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/75117\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/75117","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
A Machine Learning Algorithm With an Oversampling Technique in Limited Data Scenarios for the Prediction of Present and Future Restorative Treatment Need: Development and Validation Study.
Background: Untreated dental caries is the most common health condition worldwide. Therefore, new strategies need to be developed to reduce the manifestations of dental caries.
Objective: This study aimed to develop and test a machine learning (ML) algorithm for detecting present and predicting future carious lesions in the adolescent population using a set of easy-to-collect predictive variables. In addition, this study aimed to deal with an imbalanced and small dataset using an oversampling method.
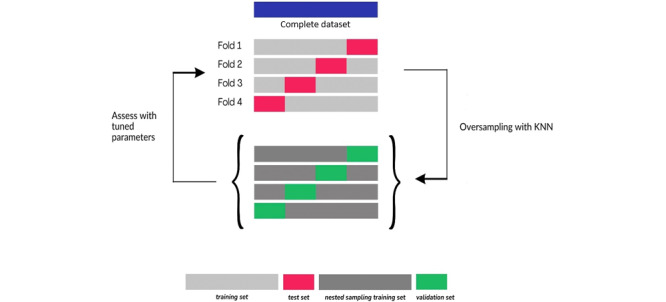
Methods: This population-based study was conducted among secondary schoolchildren, aged between 13 and 17 years, from the northern parts of Finland in 2022. After meeting the inclusion criteria, a total of 218 participants were included in this study. The inclusion criteria consisted of participants having completed a web-based risk assessment questionnaire and having undergone a clinical examination at public health care services. Dental caries (International Caries Detection and Assessment System [ICDAS] scores of 4, 5, and 6; ie, ICDAS 4-6) and active initial caries (ICDAS 2+, 3+) were considered as outcomes. Several predictors, such as behavioral and dietary habits, were included. An extreme gradient boosting model was developed, tested, and assessed for its predictive performance. A 4-fold cross-validation was performed using the nested resampling technique. The random oversampling examples method and the k-nearest neighbors classifiers were used for all 4 folds. The mean (SD) performance of all the folds was computed.
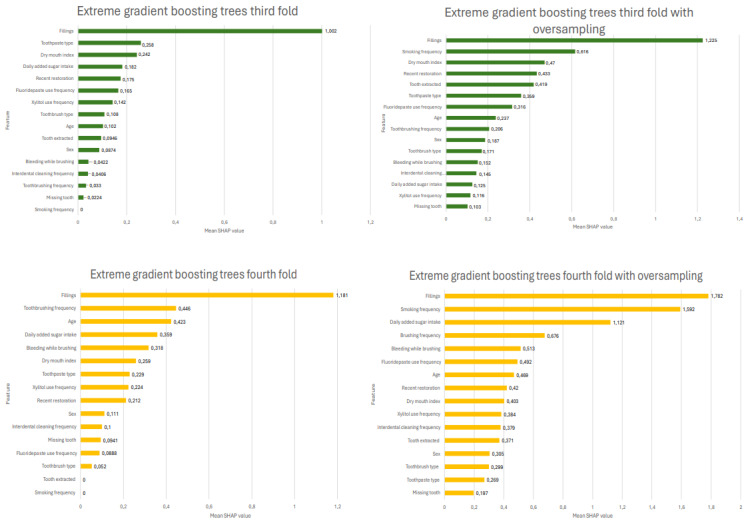
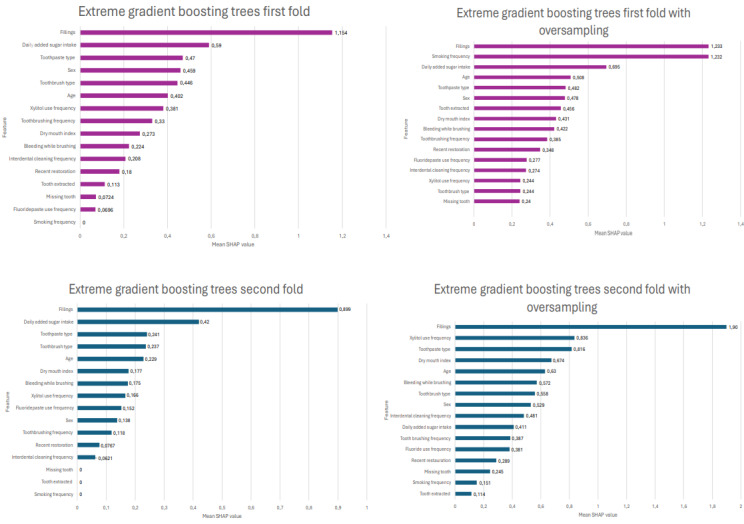
Results: Dental caries (ICDAS 2+,3+,4-6) were prevalent in 65.6% (143/218) of the participants. The mean area under the curve was 0.77 (SD 0.04) and the mean F1-score was 0.82 (SD 0.06) for the extreme gradient boosting model. Similarly, the mean area under the curve and mean F1-scores after oversampling were 0.74 (SD 0.05) and 0.79 (SD 0.04), respectively. The Shapley additive explanation values were calculated for all 4 folds to assess feature importance, revealing that previous dental fillings were the feature most strongly associated with the need for restorative treatment.
Conclusions: On the basis of the performance metrics, the ML algorithm developed and tested in this study can be considered good. The ML algorithm could serve as a cost-effective screening tool for dental professionals to identify the risk of future restorative treatment needs. However, future studies with longitudinal cohorts and longitudinal data, along with external validation for generalizability, are needed to validate our model.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


