用于整体手术场景理解的逐像素识别。
IF 11.8
1区 医学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
本文介绍了前列腺切除术的整体和多粒度手术场景理解(GraSP)数据集,这是一个规划基准,将手术场景理解建模为具有不同粒度级别的互补任务的层次结构。我们的方法包括长期任务,如手术阶段和步骤识别,以及短期任务,包括手术器械分割和原子视觉动作检测。为了利用我们提出的基准,我们引入了动作、阶段、步骤和仪器分割(TAPIS)模型的变形器,这是一种将全局视频特征提取器与仪器分割模型的局部区域建议相结合的通用架构,以解决我们的基准的多粒度问题。通过在GraSP和其他基准测试上进行广泛的实验,我们展示了TAPIS在不同任务中的多功能性和最先进的性能。这项工作代表了内窥镜视觉的基础一步,为未来的整体手术场景理解研究提供了一个新的框架。本文章由计算机程序翻译,如有差异,请以英文原文为准。
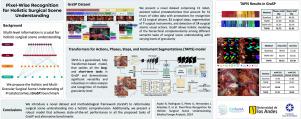
Pixel-wise recognition for holistic surgical scene understanding
This paper presents the Holistic and Multi-Granular Surgical Scene Understanding of Prostatectomies (GraSP) dataset, a curated benchmark that models surgical scene understanding as a hierarchy of complementary tasks with varying levels of granularity. Our approach encompasses long-term tasks, such as surgical phase and step recognition, and short-term tasks, including surgical instrument segmentation and atomic visual actions detection. To exploit our proposed benchmark, we introduce the Transformers for Actions, Phases, Steps, and Instrument Segmentation (TAPIS) model, a general architecture that combines a global video feature extractor with localized region proposals from an instrument segmentation model to tackle the multi-granularity of our benchmark. We demonstrate TAPIS’s versatility and state-of-the-art performance across different tasks through extensive experimentation on GraSP and alternative benchmarks. This work represents a foundational step forward in Endoscopic Vision, offering a novel framework for future research towards holistic surgical scene understanding.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Medical image analysis
工程技术-工程:生物医学
CiteScore
22.10
自引率
6.40%
发文量
309
审稿时长
6.6 months
期刊介绍:
Medical Image Analysis serves as a platform for sharing new research findings in the realm of medical and biological image analysis, with a focus on applications of computer vision, virtual reality, and robotics to biomedical imaging challenges. The journal prioritizes the publication of high-quality, original papers contributing to the fundamental science of processing, analyzing, and utilizing medical and biological images. It welcomes approaches utilizing biomedical image datasets across all spatial scales, from molecular/cellular imaging to tissue/organ imaging.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


