{"title":"ScaleSC:一个超高速和可扩展的单细胞RNA-seq数据分析管道,由GPU驱动。","authors":"Wenxing Hu, Haotian Zhang, Yu H Sun, Shaolong Cao, Jake Gagnon, Yuka Moroishi, Yirui Chen, Zhengyu Ouyang, Baohong Zhang","doi":"10.1093/bioadv/vbaf167","DOIUrl":null,"url":null,"abstract":"<p><strong>Summary: </strong>The rise of large-scale single-cell RNA-seq data has introduced challenges in data processing due to its slow speed. Leveraging advancements in Graphics Processing Unit (GPU) computing ecosystems, such as <i>CuPy</i> and Compute Unified Device Architecture (CUDA), building on <i>Scanpy</i> and <i>Rapids-singlecell</i> package, we developed <i>ScaleSC</i>, a GPU-accelerated solution for large-scale single-cell data processing. <i>ScaleSC</i> delivers over a 20× speedup through GPU computing and significantly improves scalability, handling datasets of 10-20 million cells with over 1000 batches by overcoming the memory bottleneck on a single A100 card, which far surpasses <i>Rapids-singlecell'</i>s capacity of processing only 1 million cells without multi-GPU support. We also resolved discrepancies between GPU and Central Processing Unit (CPU) algorithm implementations to ensure consistency. In addition to core optimizations, we developed novel tools for marker gene identification and cluster merging with GPU-optimized implementations seamlessly integrated. <i>ScaleSC</i> shares a similar syntax with <i>Scanpy</i>, which helps lower the learning curve for users already familiar with <i>Scanpy</i> workflows.</p><p><strong>Availability and implementation: </strong>The <i>ScaleSC</i> package (https://github.com/interactivereport/ScaleSC) promises significant benefits for the single-cell RNA-seq computational community.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf167"},"PeriodicalIF":2.8000,"publicationDate":"2025-07-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12321287/pdf/","citationCount":"0","resultStr":"{\"title\":\"<i>ScaleSC</i>: a superfast and scalable single-cell RNA-seq data analysis pipeline powered by GPU.\",\"authors\":\"Wenxing Hu, Haotian Zhang, Yu H Sun, Shaolong Cao, Jake Gagnon, Yuka Moroishi, Yirui Chen, Zhengyu Ouyang, Baohong Zhang\",\"doi\":\"10.1093/bioadv/vbaf167\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Summary: </strong>The rise of large-scale single-cell RNA-seq data has introduced challenges in data processing due to its slow speed. Leveraging advancements in Graphics Processing Unit (GPU) computing ecosystems, such as <i>CuPy</i> and Compute Unified Device Architecture (CUDA), building on <i>Scanpy</i> and <i>Rapids-singlecell</i> package, we developed <i>ScaleSC</i>, a GPU-accelerated solution for large-scale single-cell data processing. <i>ScaleSC</i> delivers over a 20× speedup through GPU computing and significantly improves scalability, handling datasets of 10-20 million cells with over 1000 batches by overcoming the memory bottleneck on a single A100 card, which far surpasses <i>Rapids-singlecell'</i>s capacity of processing only 1 million cells without multi-GPU support. We also resolved discrepancies between GPU and Central Processing Unit (CPU) algorithm implementations to ensure consistency. In addition to core optimizations, we developed novel tools for marker gene identification and cluster merging with GPU-optimized implementations seamlessly integrated. <i>ScaleSC</i> shares a similar syntax with <i>Scanpy</i>, which helps lower the learning curve for users already familiar with <i>Scanpy</i> workflows.</p><p><strong>Availability and implementation: </strong>The <i>ScaleSC</i> package (https://github.com/interactivereport/ScaleSC) promises significant benefits for the single-cell RNA-seq computational community.</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"5 1\",\"pages\":\"vbaf167\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-07-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12321287/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbaf167\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf167","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
ScaleSC: a superfast and scalable single-cell RNA-seq data analysis pipeline powered by GPU.
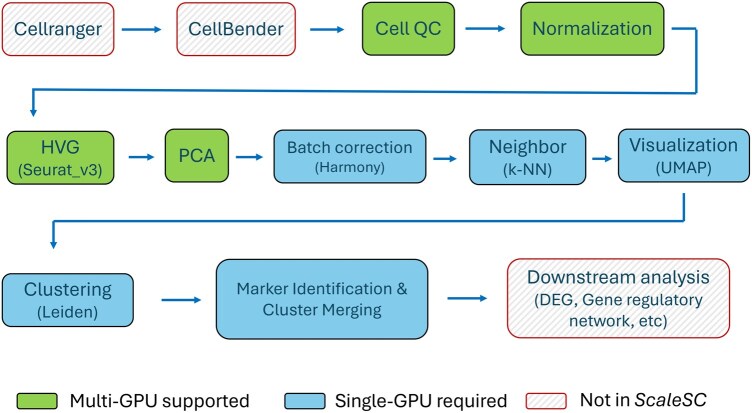
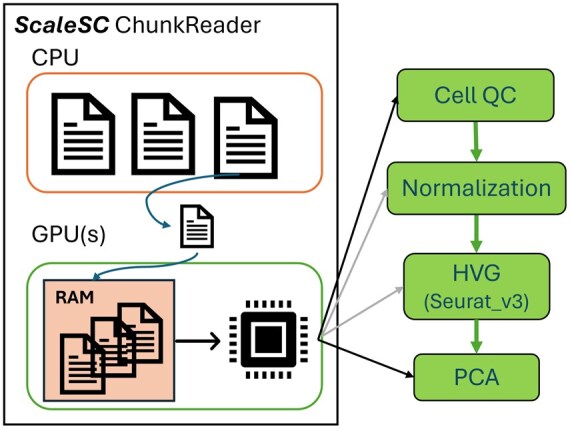
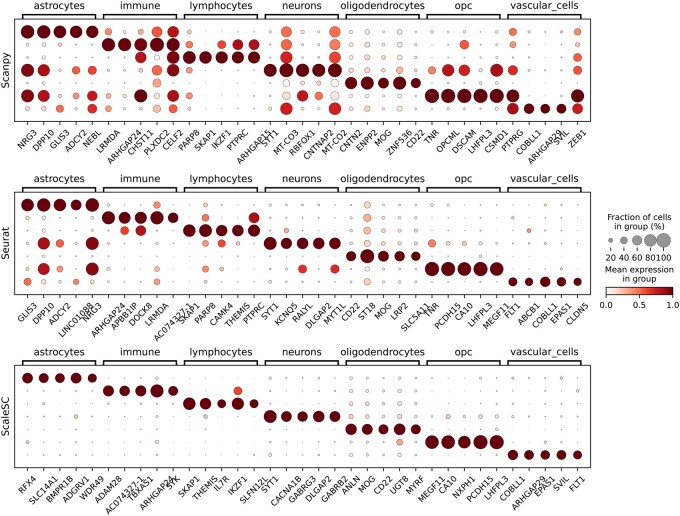
Summary: The rise of large-scale single-cell RNA-seq data has introduced challenges in data processing due to its slow speed. Leveraging advancements in Graphics Processing Unit (GPU) computing ecosystems, such as CuPy and Compute Unified Device Architecture (CUDA), building on Scanpy and Rapids-singlecell package, we developed ScaleSC, a GPU-accelerated solution for large-scale single-cell data processing. ScaleSC delivers over a 20× speedup through GPU computing and significantly improves scalability, handling datasets of 10-20 million cells with over 1000 batches by overcoming the memory bottleneck on a single A100 card, which far surpasses Rapids-singlecell's capacity of processing only 1 million cells without multi-GPU support. We also resolved discrepancies between GPU and Central Processing Unit (CPU) algorithm implementations to ensure consistency. In addition to core optimizations, we developed novel tools for marker gene identification and cluster merging with GPU-optimized implementations seamlessly integrated. ScaleSC shares a similar syntax with Scanpy, which helps lower the learning curve for users already familiar with Scanpy workflows.
Availability and implementation: The ScaleSC package (https://github.com/interactivereport/ScaleSC) promises significant benefits for the single-cell RNA-seq computational community.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


