Sophie-Caroline Schwarzkopf, Jean-Paul Bereuter, Mark Enrik Geissler, Jürgen Weitz, Marius Distler, Fiona R Kolbinger
{"title":"术后并发症管理:大型语言模型如何符合人类专业知识?","authors":"Sophie-Caroline Schwarzkopf, Jean-Paul Bereuter, Mark Enrik Geissler, Jürgen Weitz, Marius Distler, Fiona R Kolbinger","doi":"10.1371/journal.pdig.0000933","DOIUrl":null,"url":null,"abstract":"<p><p>Managing postoperative complications is an essential part of surgical care and largely depends on the medical team's experience. Large Language Models (LLMs) have demonstrated immense potential in supporting medical professionals. To evaluate the potential of LLMs in surgical patient care, we compared the performance of three state-of-the-art LLMs in managing postoperative complications to that of a panel of medical professionals based on six postsurgical patient cases. Six realistic postoperative patient cases were queried using GPT-3, GPT-4, and Gemini-Advanced and presented to human surgical caregivers. Humans and LLMs provided a triage assessment, an initial suspected diagnosis, and an acute management plan, including initial diagnostic and therapeutic measures. Responses were compared based on medical contextual correctness, coherence, and completeness. In comparison to human caregivers, GPT-3 and GPT-4 possess considerable competencies in correctly identifying postoperative complications (humans: 76.3% vs. GPT-3: 75.0% vs. GPT-4: 96.7%, p = 0.47) as well as triaging patients accordingly (humans: 84.8% vs. GPT-3: 50% vs. GPT-4: 38.3%, p = 0.19). With regard to diagnostic and therapeutic management of postoperative complications, GPT-3 and GPT-4 provided comprehensive management plans. Gemini-Advanced often provided no diagnostic or therapeutic recommendations and censored its outputs. In summary, LLMs can accurately interpret postoperative care scenarios and provide comprehensive management recommendations. These results showcase the improvements in LLMs performance with regard to postoperative surgical use cases and provide evidence for their potential value to support and augment surgical routine care.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 8","pages":"e0000933"},"PeriodicalIF":7.7000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12316209/pdf/","citationCount":"0","resultStr":"{\"title\":\"Postoperative complication management: How do large language models measure up to human expertise?\",\"authors\":\"Sophie-Caroline Schwarzkopf, Jean-Paul Bereuter, Mark Enrik Geissler, Jürgen Weitz, Marius Distler, Fiona R Kolbinger\",\"doi\":\"10.1371/journal.pdig.0000933\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Managing postoperative complications is an essential part of surgical care and largely depends on the medical team's experience. Large Language Models (LLMs) have demonstrated immense potential in supporting medical professionals. To evaluate the potential of LLMs in surgical patient care, we compared the performance of three state-of-the-art LLMs in managing postoperative complications to that of a panel of medical professionals based on six postsurgical patient cases. Six realistic postoperative patient cases were queried using GPT-3, GPT-4, and Gemini-Advanced and presented to human surgical caregivers. Humans and LLMs provided a triage assessment, an initial suspected diagnosis, and an acute management plan, including initial diagnostic and therapeutic measures. Responses were compared based on medical contextual correctness, coherence, and completeness. In comparison to human caregivers, GPT-3 and GPT-4 possess considerable competencies in correctly identifying postoperative complications (humans: 76.3% vs. GPT-3: 75.0% vs. GPT-4: 96.7%, p = 0.47) as well as triaging patients accordingly (humans: 84.8% vs. GPT-3: 50% vs. GPT-4: 38.3%, p = 0.19). With regard to diagnostic and therapeutic management of postoperative complications, GPT-3 and GPT-4 provided comprehensive management plans. Gemini-Advanced often provided no diagnostic or therapeutic recommendations and censored its outputs. In summary, LLMs can accurately interpret postoperative care scenarios and provide comprehensive management recommendations. These results showcase the improvements in LLMs performance with regard to postoperative surgical use cases and provide evidence for their potential value to support and augment surgical routine care.</p>\",\"PeriodicalId\":74465,\"journal\":{\"name\":\"PLOS digital health\",\"volume\":\"4 8\",\"pages\":\"e0000933\"},\"PeriodicalIF\":7.7000,\"publicationDate\":\"2025-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12316209/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLOS digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pdig.0000933\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000933","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
术后并发症的处理是外科护理的重要组成部分,很大程度上取决于医疗团队的经验。大型语言模型(LLMs)在支持医疗专业人员方面显示出巨大的潜力。为了评估法学硕士在外科病人护理中的潜力,我们比较了三位最先进的法学硕士在处理术后并发症方面的表现,并基于六例术后病人的医疗专业人员小组进行了比较。使用GPT-3、GPT-4和Gemini-Advanced对6例现实的术后患者进行查询,并提交给人类外科护理人员。人类和LLMs提供了分诊评估、初步疑似诊断和急性管理计划,包括初步诊断和治疗措施。根据医学语境的正确性、连贯性和完整性对回答进行比较。与人类护理人员相比,GPT-3和GPT-4在正确识别术后并发症(人类:76.3% vs. GPT-3: 75.0% vs. GPT-4: 96.7%, p = 0.47)以及相应的患者分类方面具有相当大的能力(人类:84.8% vs. GPT-3: 50% vs. GPT-4: 38.3%, p = 0.19)。在术后并发症的诊断和治疗管理方面,GPT-3和GPT-4提供了全面的管理方案。Gemini-Advanced通常不提供诊断或治疗建议,并审查其产出。综上所述,llm可以准确地解释术后护理场景并提供全面的管理建议。这些结果显示了llm在术后手术用例方面的性能改善,并为其支持和增强手术常规护理的潜在价值提供了证据。
Postoperative complication management: How do large language models measure up to human expertise?
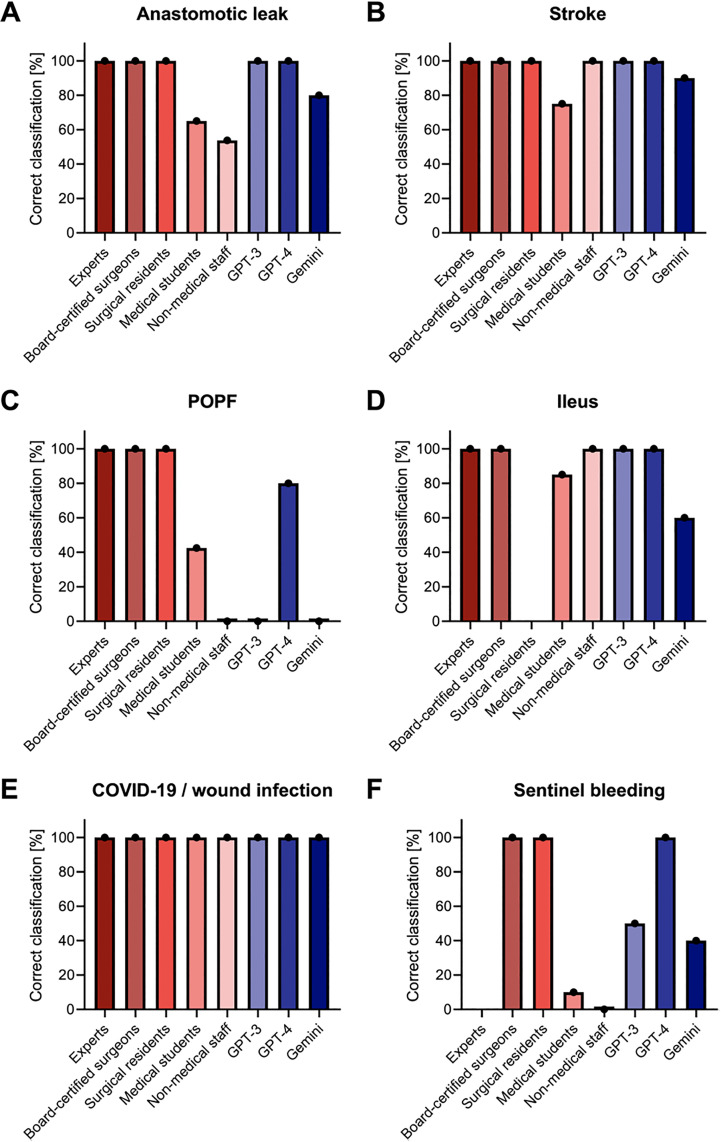
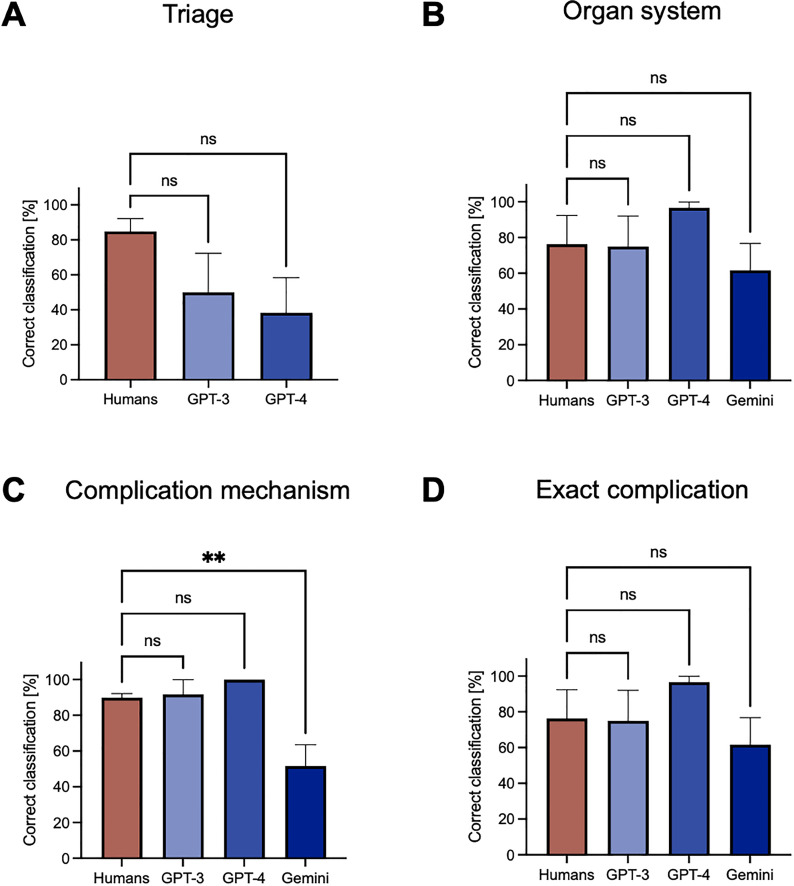
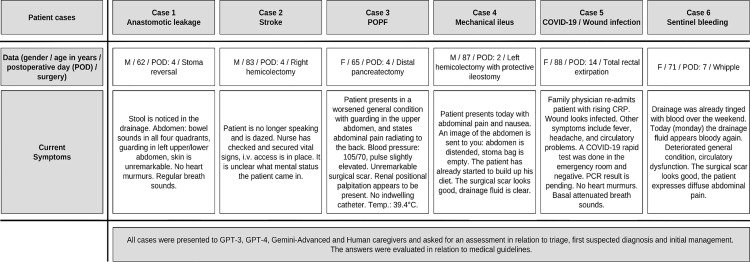
Managing postoperative complications is an essential part of surgical care and largely depends on the medical team's experience. Large Language Models (LLMs) have demonstrated immense potential in supporting medical professionals. To evaluate the potential of LLMs in surgical patient care, we compared the performance of three state-of-the-art LLMs in managing postoperative complications to that of a panel of medical professionals based on six postsurgical patient cases. Six realistic postoperative patient cases were queried using GPT-3, GPT-4, and Gemini-Advanced and presented to human surgical caregivers. Humans and LLMs provided a triage assessment, an initial suspected diagnosis, and an acute management plan, including initial diagnostic and therapeutic measures. Responses were compared based on medical contextual correctness, coherence, and completeness. In comparison to human caregivers, GPT-3 and GPT-4 possess considerable competencies in correctly identifying postoperative complications (humans: 76.3% vs. GPT-3: 75.0% vs. GPT-4: 96.7%, p = 0.47) as well as triaging patients accordingly (humans: 84.8% vs. GPT-3: 50% vs. GPT-4: 38.3%, p = 0.19). With regard to diagnostic and therapeutic management of postoperative complications, GPT-3 and GPT-4 provided comprehensive management plans. Gemini-Advanced often provided no diagnostic or therapeutic recommendations and censored its outputs. In summary, LLMs can accurately interpret postoperative care scenarios and provide comprehensive management recommendations. These results showcase the improvements in LLMs performance with regard to postoperative surgical use cases and provide evidence for their potential value to support and augment surgical routine care.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


