Ying-Chieh Han, Jane Shearer, Chunlong Mu, Donna M Slater, Suzanne C Tough, Gavin E Duggan
{"title":"机器学习技术在基于代谢组学的早产预测中的比较分析。","authors":"Ying-Chieh Han, Jane Shearer, Chunlong Mu, Donna M Slater, Suzanne C Tough, Gavin E Duggan","doi":"10.1016/j.csbj.2025.07.010","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Machine learning (ML), with advancements in algorithms and computations, is seeing an increased presence in life science research. This study investigated several ML models' efficacy in predicting preterm birth using untargeted metabolomics from serum collected during the third trimester of gestation.</p><p><strong>Methods: </strong>Samples from 48 preterm and 102 term delivery mothers from the All Our Families Cohort (Calgary, AB) were examined. Four ML algorithms: Partial Least Squares Discriminant Analysis (PLS-DA), linear logistic regression, artificial neural networks (ANN), Extreme Gradient Boosting (XGBoost) - with and without bootstrap resampling were used to examine the small-scale clinical dataset for both model performance and metabolite interpretation.</p><p><strong>Results: </strong>Model performance was evaluated based on confusion matrices, area under the receiver operating characteristic (AUROC) curve analysis, and feature importance rankings. Linear models such as PLS-DA and logistic regression demonstrated moderate classification performance (AUROC ≈ 0.60), whereas non-linear approaches, including ANN and XGBoost, exhibited marginal improvements. Among all models, XGBoost combined with bootstrap resampling achieved the highest performance, yielding an AUROC of 0.85 (95 % CI: 0.57-0.99, p < 0.001), indicating a significant improvement in classification accuracy. Metabolite importance, derived from Shapley Additive Explanations (SHAP), consistently identified acylcarnitines and amino acid derivatives as principal discriminative features. Pathway analysis revealed disruptions to tyrosine metabolism as well as phenylalanine, tyrosine and tryptophan biosynthesis to be associated with preterm delivery.</p><p><strong>Conclusions: </strong>Our results highlight the complexity of metabolomics-based modelling for preterm birth and support an iterative, model-driven approach for optimizing predictive accuracy in small-scale clinical datasets.</p>","PeriodicalId":10715,"journal":{"name":"Computational and structural biotechnology journal","volume":"27 ","pages":"3240-3250"},"PeriodicalIF":4.1000,"publicationDate":"2025-07-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12312043/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparative analysis of machine learning techniques in metabolomic-based preterm birth prediction.\",\"authors\":\"Ying-Chieh Han, Jane Shearer, Chunlong Mu, Donna M Slater, Suzanne C Tough, Gavin E Duggan\",\"doi\":\"10.1016/j.csbj.2025.07.010\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Machine learning (ML), with advancements in algorithms and computations, is seeing an increased presence in life science research. This study investigated several ML models' efficacy in predicting preterm birth using untargeted metabolomics from serum collected during the third trimester of gestation.</p><p><strong>Methods: </strong>Samples from 48 preterm and 102 term delivery mothers from the All Our Families Cohort (Calgary, AB) were examined. Four ML algorithms: Partial Least Squares Discriminant Analysis (PLS-DA), linear logistic regression, artificial neural networks (ANN), Extreme Gradient Boosting (XGBoost) - with and without bootstrap resampling were used to examine the small-scale clinical dataset for both model performance and metabolite interpretation.</p><p><strong>Results: </strong>Model performance was evaluated based on confusion matrices, area under the receiver operating characteristic (AUROC) curve analysis, and feature importance rankings. Linear models such as PLS-DA and logistic regression demonstrated moderate classification performance (AUROC ≈ 0.60), whereas non-linear approaches, including ANN and XGBoost, exhibited marginal improvements. Among all models, XGBoost combined with bootstrap resampling achieved the highest performance, yielding an AUROC of 0.85 (95 % CI: 0.57-0.99, p < 0.001), indicating a significant improvement in classification accuracy. Metabolite importance, derived from Shapley Additive Explanations (SHAP), consistently identified acylcarnitines and amino acid derivatives as principal discriminative features. Pathway analysis revealed disruptions to tyrosine metabolism as well as phenylalanine, tyrosine and tryptophan biosynthesis to be associated with preterm delivery.</p><p><strong>Conclusions: </strong>Our results highlight the complexity of metabolomics-based modelling for preterm birth and support an iterative, model-driven approach for optimizing predictive accuracy in small-scale clinical datasets.</p>\",\"PeriodicalId\":10715,\"journal\":{\"name\":\"Computational and structural biotechnology journal\",\"volume\":\"27 \",\"pages\":\"3240-3250\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2025-07-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12312043/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational and structural biotechnology journal\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1016/j.csbj.2025.07.010\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and structural biotechnology journal","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1016/j.csbj.2025.07.010","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
背景:随着算法和计算的进步,机器学习(ML)在生命科学研究中的应用越来越多。本研究利用妊娠晚期收集的血清非靶向代谢组学研究了几种ML模型在预测早产方面的有效性。方法:对来自All Our Families队列(Calgary, AB)的48名早产儿和102名足月分娩母亲的样本进行了检查。四种机器学习算法:偏最小二乘判别分析(PLS-DA)、线性逻辑回归、人工神经网络(ANN)、极端梯度增强(XGBoost)——带和不带自举重采样,用于检查小规模临床数据集的模型性能和代谢物解释。结果:基于混淆矩阵、接收者工作特征(AUROC)曲线下面积分析和特征重要性排名来评估模型的性能。线性模型如PLS-DA和逻辑回归表现出中等的分类性能(AUROC≈0.60),而非线性方法,包括ANN和XGBoost,表现出边际改进。在所有模型中,XGBoost结合bootstrap重采样获得了最高的性能,AUROC为0.85(95 % CI: 0.57-0.99, p )。结论:我们的研究结果突出了基于代谢组学的早产建模的复杂性,并支持迭代的、模型驱动的方法来优化小规模临床数据集的预测准确性。
Comparative analysis of machine learning techniques in metabolomic-based preterm birth prediction.
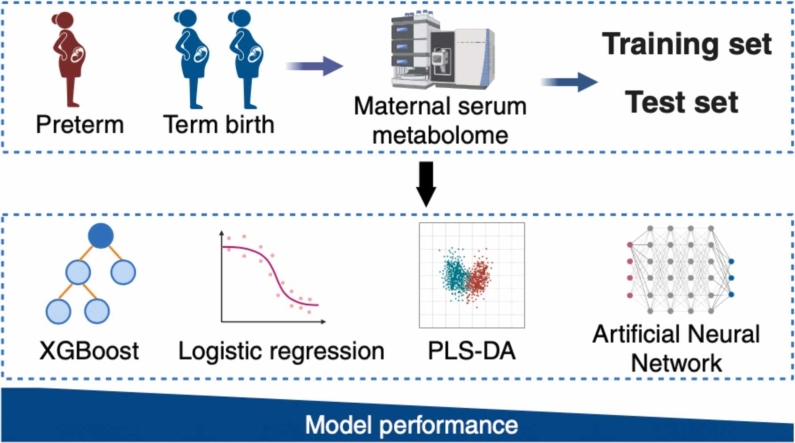
Background: Machine learning (ML), with advancements in algorithms and computations, is seeing an increased presence in life science research. This study investigated several ML models' efficacy in predicting preterm birth using untargeted metabolomics from serum collected during the third trimester of gestation.
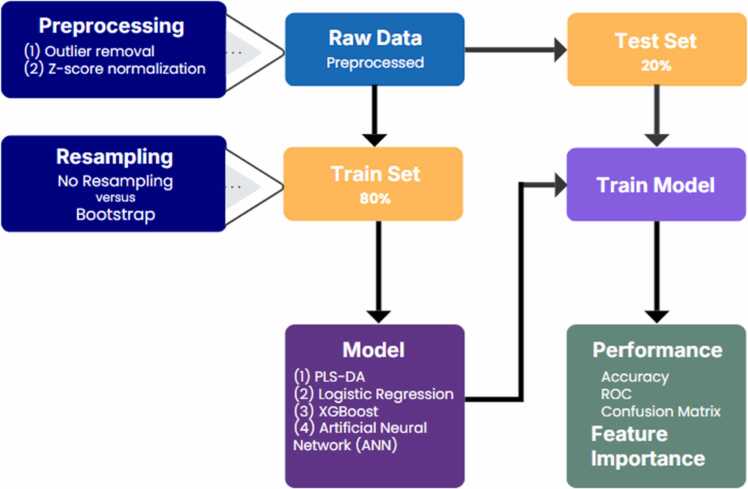
Methods: Samples from 48 preterm and 102 term delivery mothers from the All Our Families Cohort (Calgary, AB) were examined. Four ML algorithms: Partial Least Squares Discriminant Analysis (PLS-DA), linear logistic regression, artificial neural networks (ANN), Extreme Gradient Boosting (XGBoost) - with and without bootstrap resampling were used to examine the small-scale clinical dataset for both model performance and metabolite interpretation.
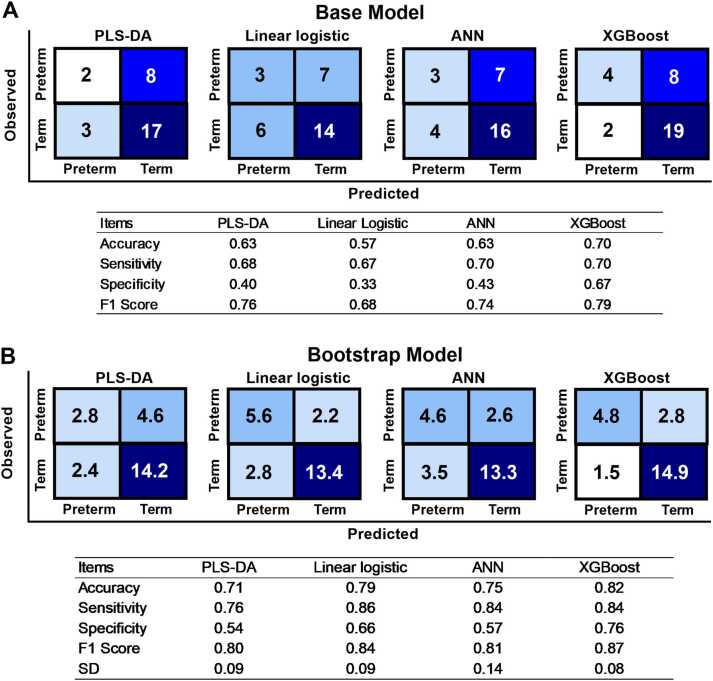
Results: Model performance was evaluated based on confusion matrices, area under the receiver operating characteristic (AUROC) curve analysis, and feature importance rankings. Linear models such as PLS-DA and logistic regression demonstrated moderate classification performance (AUROC ≈ 0.60), whereas non-linear approaches, including ANN and XGBoost, exhibited marginal improvements. Among all models, XGBoost combined with bootstrap resampling achieved the highest performance, yielding an AUROC of 0.85 (95 % CI: 0.57-0.99, p < 0.001), indicating a significant improvement in classification accuracy. Metabolite importance, derived from Shapley Additive Explanations (SHAP), consistently identified acylcarnitines and amino acid derivatives as principal discriminative features. Pathway analysis revealed disruptions to tyrosine metabolism as well as phenylalanine, tyrosine and tryptophan biosynthesis to be associated with preterm delivery.
Conclusions: Our results highlight the complexity of metabolomics-based modelling for preterm birth and support an iterative, model-driven approach for optimizing predictive accuracy in small-scale clinical datasets.
期刊介绍:
Computational and Structural Biotechnology Journal (CSBJ) is an online gold open access journal publishing research articles and reviews after full peer review. All articles are published, without barriers to access, immediately upon acceptance. The journal places a strong emphasis on functional and mechanistic understanding of how molecular components in a biological process work together through the application of computational methods. Structural data may provide such insights, but they are not a pre-requisite for publication in the journal. Specific areas of interest include, but are not limited to:
Structure and function of proteins, nucleic acids and other macromolecules
Structure and function of multi-component complexes
Protein folding, processing and degradation
Enzymology
Computational and structural studies of plant systems
Microbial Informatics
Genomics
Proteomics
Metabolomics
Algorithms and Hypothesis in Bioinformatics
Mathematical and Theoretical Biology
Computational Chemistry and Drug Discovery
Microscopy and Molecular Imaging
Nanotechnology
Systems and Synthetic Biology

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


