Necip Oğuz Şerbetci, Stefan Blüher, Paul Gellert, Ulf Leser
{"title":"解释护理需求评估调查:对本地和全球最先进的可解释人工智能方法进行定性和定量评估。","authors":"Necip Oğuz Şerbetci, Stefan Blüher, Paul Gellert, Ulf Leser","doi":"10.1093/jamiaopen/ooaf064","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>With extended life expectancy, the number of people in need of care has been growing. To optimally support them, it is important to know the patterns and conditions of their daily life that influence the need for support, and thus, the classification of the care need. In this study, we aim to utilize a large corpus consisting of care benefits applications to do an explorative analysis of factors affecting care need to support the tedious work of experts gathering reliable criteria for a care need assessment.</p><p><strong>Materials and methods: </strong>We compare state-of-the-art methods from explainable artificial intelligence (XAI) as means to extract such patterns from over 72 000 German care benefits applications. We train transformer models to predict assessment results as decided by a Medical Service Unit from accompanying text notes. To understand the key factors for care need assessment and its constituent modules (such as mobility and self-therapy), we apply feature attribution methods to extract the key phrases for each prediction. These local explanations are then aggregated into global insights to derive key phrases for different modules and severity of care need over the dataset.</p><p><strong>Results: </strong>Our experiments show that transformers-based models perform slightly better than traditional bag-of-words baselines in predicting care need. We find that the bag-of-words baseline also provides useful care-relevant phrases, whereas phrases obtained through transformer explanations better balance rare and common phrases, such as diagnoses mentioned only once, and are better in assigning the correct assessment module.</p><p><strong>Discussion: </strong>Even though XAI results can become unwieldy, they let us get an understanding of thousands of documents with no extra annotations other than existing assessment outcomes.</p><p><strong>Conclusion: </strong>This work provides a systematic application and comparison of both traditional and state-of-the-art deep learning based XAI approaches to extract insights from a large corpus of text. Both traditional and deep learning approaches provide useful phrases, and we recommend using both to explore and understand large text corpora better. We will make our code available at https://github.com/oguzserbetci/explainer.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 4","pages":"ooaf064"},"PeriodicalIF":3.4000,"publicationDate":"2025-07-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12307913/pdf/","citationCount":"0","resultStr":"{\"title\":\"Explaining care need assessment surveys: qualitative and quantitative evaluation of state-of-the-art local and global explainable artificial intelligence methods.\",\"authors\":\"Necip Oğuz Şerbetci, Stefan Blüher, Paul Gellert, Ulf Leser\",\"doi\":\"10.1093/jamiaopen/ooaf064\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>With extended life expectancy, the number of people in need of care has been growing. To optimally support them, it is important to know the patterns and conditions of their daily life that influence the need for support, and thus, the classification of the care need. In this study, we aim to utilize a large corpus consisting of care benefits applications to do an explorative analysis of factors affecting care need to support the tedious work of experts gathering reliable criteria for a care need assessment.</p><p><strong>Materials and methods: </strong>We compare state-of-the-art methods from explainable artificial intelligence (XAI) as means to extract such patterns from over 72 000 German care benefits applications. We train transformer models to predict assessment results as decided by a Medical Service Unit from accompanying text notes. To understand the key factors for care need assessment and its constituent modules (such as mobility and self-therapy), we apply feature attribution methods to extract the key phrases for each prediction. These local explanations are then aggregated into global insights to derive key phrases for different modules and severity of care need over the dataset.</p><p><strong>Results: </strong>Our experiments show that transformers-based models perform slightly better than traditional bag-of-words baselines in predicting care need. We find that the bag-of-words baseline also provides useful care-relevant phrases, whereas phrases obtained through transformer explanations better balance rare and common phrases, such as diagnoses mentioned only once, and are better in assigning the correct assessment module.</p><p><strong>Discussion: </strong>Even though XAI results can become unwieldy, they let us get an understanding of thousands of documents with no extra annotations other than existing assessment outcomes.</p><p><strong>Conclusion: </strong>This work provides a systematic application and comparison of both traditional and state-of-the-art deep learning based XAI approaches to extract insights from a large corpus of text. Both traditional and deep learning approaches provide useful phrases, and we recommend using both to explore and understand large text corpora better. We will make our code available at https://github.com/oguzserbetci/explainer.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"8 4\",\"pages\":\"ooaf064\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2025-07-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12307913/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooaf064\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/8/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf064","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Explaining care need assessment surveys: qualitative and quantitative evaluation of state-of-the-art local and global explainable artificial intelligence methods.
Objective: With extended life expectancy, the number of people in need of care has been growing. To optimally support them, it is important to know the patterns and conditions of their daily life that influence the need for support, and thus, the classification of the care need. In this study, we aim to utilize a large corpus consisting of care benefits applications to do an explorative analysis of factors affecting care need to support the tedious work of experts gathering reliable criteria for a care need assessment.
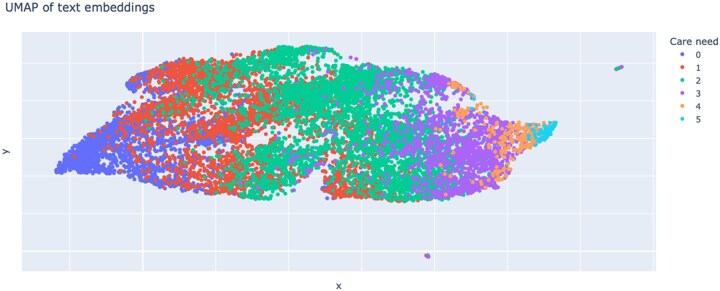
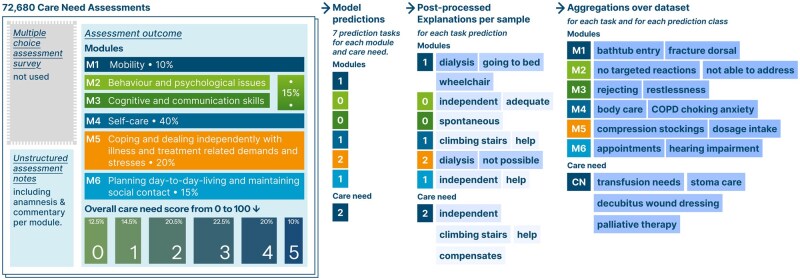
Materials and methods: We compare state-of-the-art methods from explainable artificial intelligence (XAI) as means to extract such patterns from over 72 000 German care benefits applications. We train transformer models to predict assessment results as decided by a Medical Service Unit from accompanying text notes. To understand the key factors for care need assessment and its constituent modules (such as mobility and self-therapy), we apply feature attribution methods to extract the key phrases for each prediction. These local explanations are then aggregated into global insights to derive key phrases for different modules and severity of care need over the dataset.
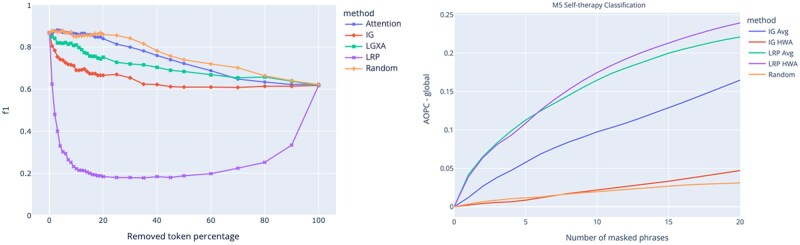
Results: Our experiments show that transformers-based models perform slightly better than traditional bag-of-words baselines in predicting care need. We find that the bag-of-words baseline also provides useful care-relevant phrases, whereas phrases obtained through transformer explanations better balance rare and common phrases, such as diagnoses mentioned only once, and are better in assigning the correct assessment module.
Discussion: Even though XAI results can become unwieldy, they let us get an understanding of thousands of documents with no extra annotations other than existing assessment outcomes.
Conclusion: This work provides a systematic application and comparison of both traditional and state-of-the-art deep learning based XAI approaches to extract insights from a large corpus of text. Both traditional and deep learning approaches provide useful phrases, and we recommend using both to explore and understand large text corpora better. We will make our code available at https://github.com/oguzserbetci/explainer.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


