Jay DeYoung, Stephanie C Martinez, Iain J Marshall, Byron C Wallace
{"title":"多文档摘要模型能合成吗?","authors":"Jay DeYoung, Stephanie C Martinez, Iain J Marshall, Byron C Wallace","doi":"10.1162/tacl_a_00687","DOIUrl":null,"url":null,"abstract":"<p><p>Multi-document summarization entails producing concise synopses of collections of inputs. For some applications, the synopsis should accurately <i>synthesize</i> inputs with respect to a key aspect, e.g., a synopsis of film reviews written about a particular movie should reflect the average critic consensus. As a more consequential example, narrative summaries that accompany biomedical <i>systematic reviews</i> of clinical trial results should accurately summarize the potentially conflicting results from individual trials. In this paper we ask: To what extent do modern multi-document summarization models implicitly perform this sort of synthesis? We run experiments over opinion and evidence synthesis datasets using a suite of summarization models, from fine-tuned transformers to GPT-4. We find that existing models partially perform synthesis, but imperfectly: Even the best performing models are over-sensitive to changes in input ordering and under-sensitive to changes in input compositions (e.g., ratio of positive to negative reviews). We propose a simple, general, effective method for improving model synthesis capabilities by generating an explicitly diverse set of candidate outputs, and then selecting from these the string best aligned with the expected aggregate measure for the inputs, or <i>abstaining</i> when the model produces no good candidate.</p>","PeriodicalId":33559,"journal":{"name":"Transactions of the Association for Computational Linguistics","volume":"12 ","pages":"1043-1062"},"PeriodicalIF":4.2000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12308705/pdf/","citationCount":"0","resultStr":"{\"title\":\"Do Multi-Document Summarization Models <i>Synthesize</i>?\",\"authors\":\"Jay DeYoung, Stephanie C Martinez, Iain J Marshall, Byron C Wallace\",\"doi\":\"10.1162/tacl_a_00687\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Multi-document summarization entails producing concise synopses of collections of inputs. For some applications, the synopsis should accurately <i>synthesize</i> inputs with respect to a key aspect, e.g., a synopsis of film reviews written about a particular movie should reflect the average critic consensus. As a more consequential example, narrative summaries that accompany biomedical <i>systematic reviews</i> of clinical trial results should accurately summarize the potentially conflicting results from individual trials. In this paper we ask: To what extent do modern multi-document summarization models implicitly perform this sort of synthesis? We run experiments over opinion and evidence synthesis datasets using a suite of summarization models, from fine-tuned transformers to GPT-4. We find that existing models partially perform synthesis, but imperfectly: Even the best performing models are over-sensitive to changes in input ordering and under-sensitive to changes in input compositions (e.g., ratio of positive to negative reviews). We propose a simple, general, effective method for improving model synthesis capabilities by generating an explicitly diverse set of candidate outputs, and then selecting from these the string best aligned with the expected aggregate measure for the inputs, or <i>abstaining</i> when the model produces no good candidate.</p>\",\"PeriodicalId\":33559,\"journal\":{\"name\":\"Transactions of the Association for Computational Linguistics\",\"volume\":\"12 \",\"pages\":\"1043-1062\"},\"PeriodicalIF\":4.2000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12308705/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Transactions of the Association for Computational Linguistics\",\"FirstCategoryId\":\"98\",\"ListUrlMain\":\"https://doi.org/10.1162/tacl_a_00687\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/9/4 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Transactions of the Association for Computational Linguistics","FirstCategoryId":"98","ListUrlMain":"https://doi.org/10.1162/tacl_a_00687","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/4 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Do Multi-Document Summarization Models Synthesize?
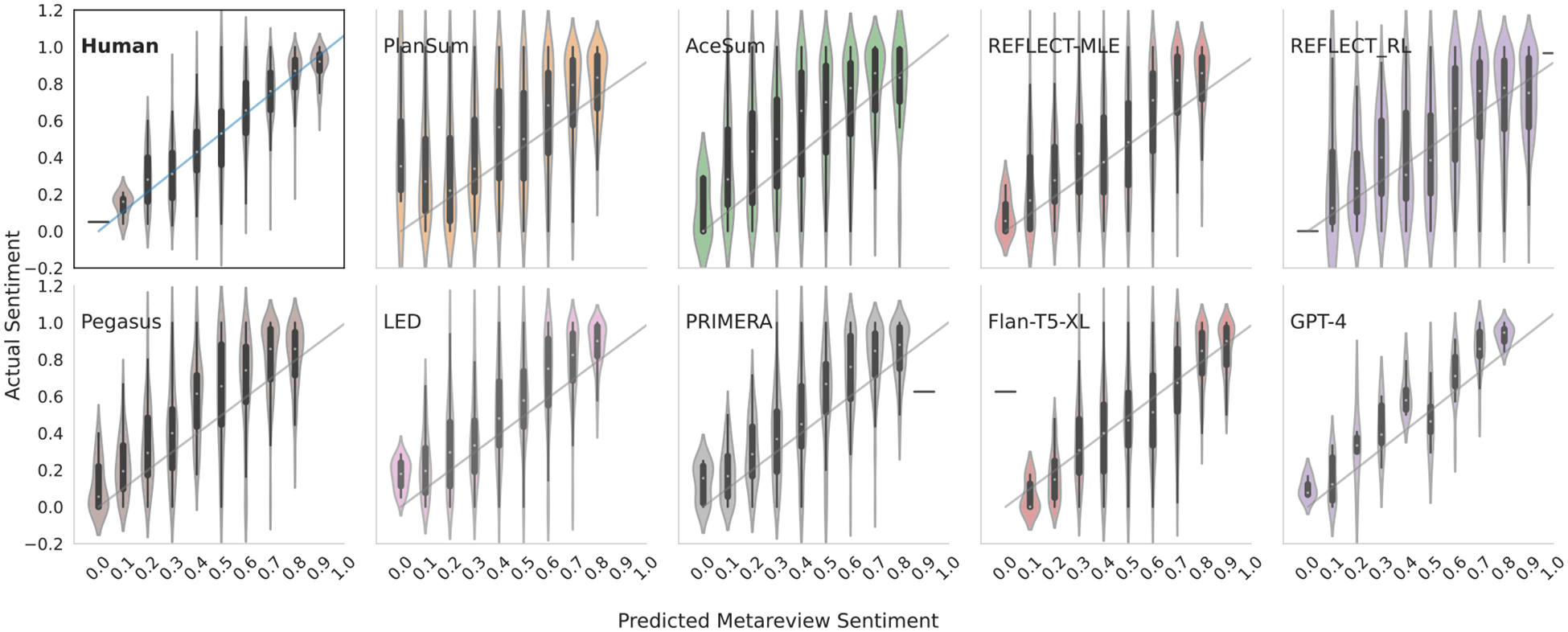
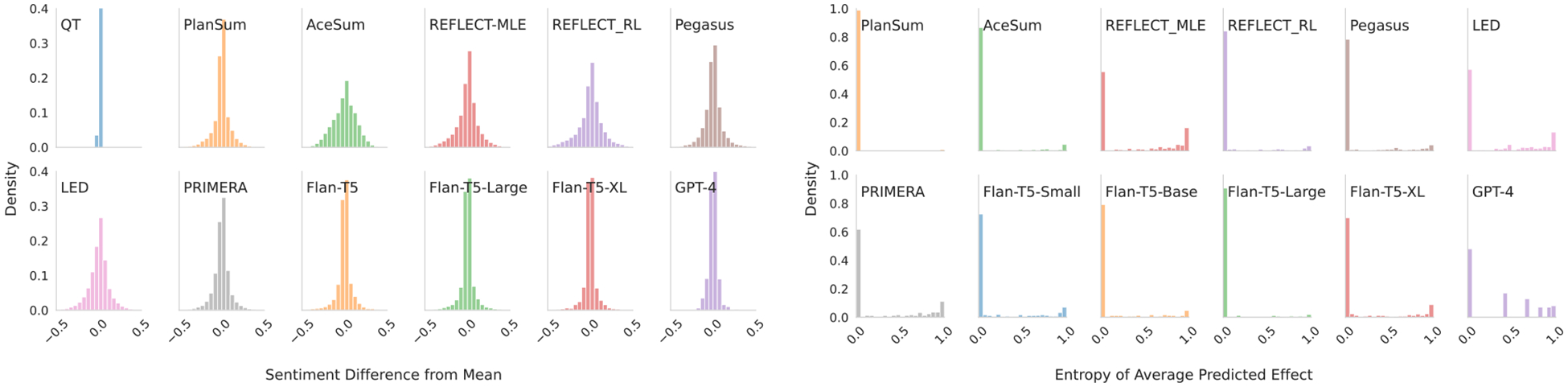
Multi-document summarization entails producing concise synopses of collections of inputs. For some applications, the synopsis should accurately synthesize inputs with respect to a key aspect, e.g., a synopsis of film reviews written about a particular movie should reflect the average critic consensus. As a more consequential example, narrative summaries that accompany biomedical systematic reviews of clinical trial results should accurately summarize the potentially conflicting results from individual trials. In this paper we ask: To what extent do modern multi-document summarization models implicitly perform this sort of synthesis? We run experiments over opinion and evidence synthesis datasets using a suite of summarization models, from fine-tuned transformers to GPT-4. We find that existing models partially perform synthesis, but imperfectly: Even the best performing models are over-sensitive to changes in input ordering and under-sensitive to changes in input compositions (e.g., ratio of positive to negative reviews). We propose a simple, general, effective method for improving model synthesis capabilities by generating an explicitly diverse set of candidate outputs, and then selecting from these the string best aligned with the expected aggregate measure for the inputs, or abstaining when the model produces no good candidate.
期刊介绍:
The highly regarded quarterly journal Computational Linguistics has a companion journal called Transactions of the Association for Computational Linguistics. This open access journal publishes articles in all areas of natural language processing and is an important resource for academic and industry computational linguists, natural language processing experts, artificial intelligence and machine learning investigators, cognitive scientists, speech specialists, as well as linguists and philosophers. The journal disseminates work of vital relevance to these professionals on an annual basis.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


