Raniah Nur Hanami, Rahmad Mahendra, Alfan Farizki Wicaksono
{"title":"印度尼西亚消费者健康问题的语义分类。","authors":"Raniah Nur Hanami, Rahmad Mahendra, Alfan Farizki Wicaksono","doi":"10.1186/s13326-025-00334-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Online consumer health forums serve as a way for the public to connect with medical professionals. While these medical forums offer a valuable service, online Question Answering (QA) forums can struggle to deliver timely answers due to the limited number of available healthcare professionals. One way to solve this problem is by developing an automatic QA system that can provide patients with quicker answers. One key component of such a system could be a module for classifying the semantic type of a question. This would allow the system to understand the patient's intent and route them towards the relevant information.</p><p><strong>Methods: </strong>This paper proposes a novel two-step approach to address the challenge of semantic type classification in Indonesian consumer health questions. We acknowledge the scarcity of Indonesian health domain data, a hurdle for machine learning models. To address this gap, we first introduce a novel corpus of annotated Indonesian consumer health questions. Second, we utilize this newly created corpus to build and evaluate a data-driven predictive model for classifying question semantic types. To enhance the trustworthiness and interpretability of the model's predictions, we employ an explainable model framework, LIME. This framework facilitates a deeper understanding of the role played by word-based features in the model's decision-making process. Additionally, it empowers us to conduct a comprehensive bias analysis, allowing for the detection of \"semantic bias\", where words with no inherent association with a specific semantic type disproportionately influence the model's predictions.</p><p><strong>Results: </strong>The annotation process revealed moderate agreement between expert annotators. In addition, not all words with high LIME probability could be considered true characteristics of a question type. This suggests a potential bias in the data used and the machine learning models themselves. Notably, XGBoost, Naïve Bayes, and MLP models exhibited a tendency to predict questions containing the words \"kanker\" (cancer) and \"depresi\" (depression) as belonging to the DIAGNOSIS category. In terms of prediction performance, Perceptron and XGBoost emerged as the top-performing models, achieving the highest weighted average F1 scores across all input scenarios and weighting factors. Naïve Bayes performed best after balancing the data with Borderline SMOTE, indicating its promise for handling imbalanced datasets.</p><p><strong>Conclusion: </strong>We constructed a corpus of query semantics in the domain of Indonesian consumer health, containing 964 questions annotated with their corresponding semantic types. This corpus served as the foundation for building a predictive model. We further investigated the impact of disease-biased words on model performance. These words exhibited high LIME scores, yet lacked association with a specific semantic type. We trained models using datasets with and without these biased words and found no significant difference in model performance between the two scenarios, suggesting that the models might possess an ability to mitigate the influence of such bias during the learning process.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":"16 1","pages":"13"},"PeriodicalIF":2.0000,"publicationDate":"2025-07-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12302743/pdf/","citationCount":"0","resultStr":"{\"title\":\"Semantic classification of Indonesian consumer health questions.\",\"authors\":\"Raniah Nur Hanami, Rahmad Mahendra, Alfan Farizki Wicaksono\",\"doi\":\"10.1186/s13326-025-00334-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Online consumer health forums serve as a way for the public to connect with medical professionals. While these medical forums offer a valuable service, online Question Answering (QA) forums can struggle to deliver timely answers due to the limited number of available healthcare professionals. One way to solve this problem is by developing an automatic QA system that can provide patients with quicker answers. One key component of such a system could be a module for classifying the semantic type of a question. This would allow the system to understand the patient's intent and route them towards the relevant information.</p><p><strong>Methods: </strong>This paper proposes a novel two-step approach to address the challenge of semantic type classification in Indonesian consumer health questions. We acknowledge the scarcity of Indonesian health domain data, a hurdle for machine learning models. To address this gap, we first introduce a novel corpus of annotated Indonesian consumer health questions. Second, we utilize this newly created corpus to build and evaluate a data-driven predictive model for classifying question semantic types. To enhance the trustworthiness and interpretability of the model's predictions, we employ an explainable model framework, LIME. This framework facilitates a deeper understanding of the role played by word-based features in the model's decision-making process. Additionally, it empowers us to conduct a comprehensive bias analysis, allowing for the detection of \\\"semantic bias\\\", where words with no inherent association with a specific semantic type disproportionately influence the model's predictions.</p><p><strong>Results: </strong>The annotation process revealed moderate agreement between expert annotators. In addition, not all words with high LIME probability could be considered true characteristics of a question type. This suggests a potential bias in the data used and the machine learning models themselves. Notably, XGBoost, Naïve Bayes, and MLP models exhibited a tendency to predict questions containing the words \\\"kanker\\\" (cancer) and \\\"depresi\\\" (depression) as belonging to the DIAGNOSIS category. In terms of prediction performance, Perceptron and XGBoost emerged as the top-performing models, achieving the highest weighted average F1 scores across all input scenarios and weighting factors. Naïve Bayes performed best after balancing the data with Borderline SMOTE, indicating its promise for handling imbalanced datasets.</p><p><strong>Conclusion: </strong>We constructed a corpus of query semantics in the domain of Indonesian consumer health, containing 964 questions annotated with their corresponding semantic types. This corpus served as the foundation for building a predictive model. We further investigated the impact of disease-biased words on model performance. These words exhibited high LIME scores, yet lacked association with a specific semantic type. We trained models using datasets with and without these biased words and found no significant difference in model performance between the two scenarios, suggesting that the models might possess an ability to mitigate the influence of such bias during the learning process.</p>\",\"PeriodicalId\":15055,\"journal\":{\"name\":\"Journal of Biomedical Semantics\",\"volume\":\"16 1\",\"pages\":\"13\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-07-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12302743/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Semantics\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1186/s13326-025-00334-5\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-025-00334-5","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Semantic classification of Indonesian consumer health questions.
Purpose: Online consumer health forums serve as a way for the public to connect with medical professionals. While these medical forums offer a valuable service, online Question Answering (QA) forums can struggle to deliver timely answers due to the limited number of available healthcare professionals. One way to solve this problem is by developing an automatic QA system that can provide patients with quicker answers. One key component of such a system could be a module for classifying the semantic type of a question. This would allow the system to understand the patient's intent and route them towards the relevant information.
Methods: This paper proposes a novel two-step approach to address the challenge of semantic type classification in Indonesian consumer health questions. We acknowledge the scarcity of Indonesian health domain data, a hurdle for machine learning models. To address this gap, we first introduce a novel corpus of annotated Indonesian consumer health questions. Second, we utilize this newly created corpus to build and evaluate a data-driven predictive model for classifying question semantic types. To enhance the trustworthiness and interpretability of the model's predictions, we employ an explainable model framework, LIME. This framework facilitates a deeper understanding of the role played by word-based features in the model's decision-making process. Additionally, it empowers us to conduct a comprehensive bias analysis, allowing for the detection of "semantic bias", where words with no inherent association with a specific semantic type disproportionately influence the model's predictions.
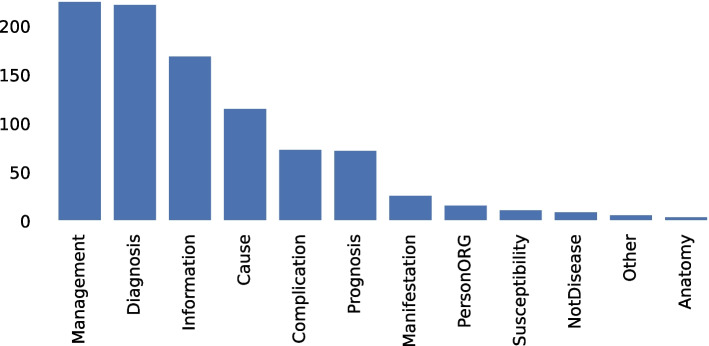
Results: The annotation process revealed moderate agreement between expert annotators. In addition, not all words with high LIME probability could be considered true characteristics of a question type. This suggests a potential bias in the data used and the machine learning models themselves. Notably, XGBoost, Naïve Bayes, and MLP models exhibited a tendency to predict questions containing the words "kanker" (cancer) and "depresi" (depression) as belonging to the DIAGNOSIS category. In terms of prediction performance, Perceptron and XGBoost emerged as the top-performing models, achieving the highest weighted average F1 scores across all input scenarios and weighting factors. Naïve Bayes performed best after balancing the data with Borderline SMOTE, indicating its promise for handling imbalanced datasets.
Conclusion: We constructed a corpus of query semantics in the domain of Indonesian consumer health, containing 964 questions annotated with their corresponding semantic types. This corpus served as the foundation for building a predictive model. We further investigated the impact of disease-biased words on model performance. These words exhibited high LIME scores, yet lacked association with a specific semantic type. We trained models using datasets with and without these biased words and found no significant difference in model performance between the two scenarios, suggesting that the models might possess an ability to mitigate the influence of such bias during the learning process.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


