{"title":"Assay2Mol:使用BioAssay上下文进行基于大语言模型的药物设计。","authors":"Yifan Deng, Spencer S Ericksen, Anthony Gitter","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Scientific databases aggregate vast amounts of quantitative data alongside descriptive text. In biochemistry, molecule screening assays evaluate candidate molecules' functional responses against disease targets. Unstructured text that describes the biological mechanisms through which these targets operate, experimental screening protocols, and other attributes of assays offer rich information for drug discovery campaigns but has been untapped because of that unstructured format. We present Assay2Mol, a large language model-based workflow that can capitalize on the vast existing biochemical screening assays for early-stage drug discovery. Assay2Mol retrieves existing assay records involving targets similar to the new target and generates candidate molecules using in-context learning with the retrieved assay screening data. Assay2Mol outperforms recent machine learning approaches that generate candidate ligand molecules for target protein structures, while also promoting more synthesizable molecule generation.</p>","PeriodicalId":93888,"journal":{"name":"ArXiv","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2025-09-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12288650/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assay2Mol: Large Language Model-based Drug Design Using BioAssay Context.\",\"authors\":\"Yifan Deng, Spencer S Ericksen, Anthony Gitter\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Scientific databases aggregate vast amounts of quantitative data alongside descriptive text. In biochemistry, molecule screening assays evaluate candidate molecules' functional responses against disease targets. Unstructured text that describes the biological mechanisms through which these targets operate, experimental screening protocols, and other attributes of assays offer rich information for drug discovery campaigns but has been untapped because of that unstructured format. We present Assay2Mol, a large language model-based workflow that can capitalize on the vast existing biochemical screening assays for early-stage drug discovery. Assay2Mol retrieves existing assay records involving targets similar to the new target and generates candidate molecules using in-context learning with the retrieved assay screening data. Assay2Mol outperforms recent machine learning approaches that generate candidate ligand molecules for target protein structures, while also promoting more synthesizable molecule generation.</p>\",\"PeriodicalId\":93888,\"journal\":{\"name\":\"ArXiv\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-09-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12288650/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ArXiv\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ArXiv","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Assay2Mol: Large Language Model-based Drug Design Using BioAssay Context.
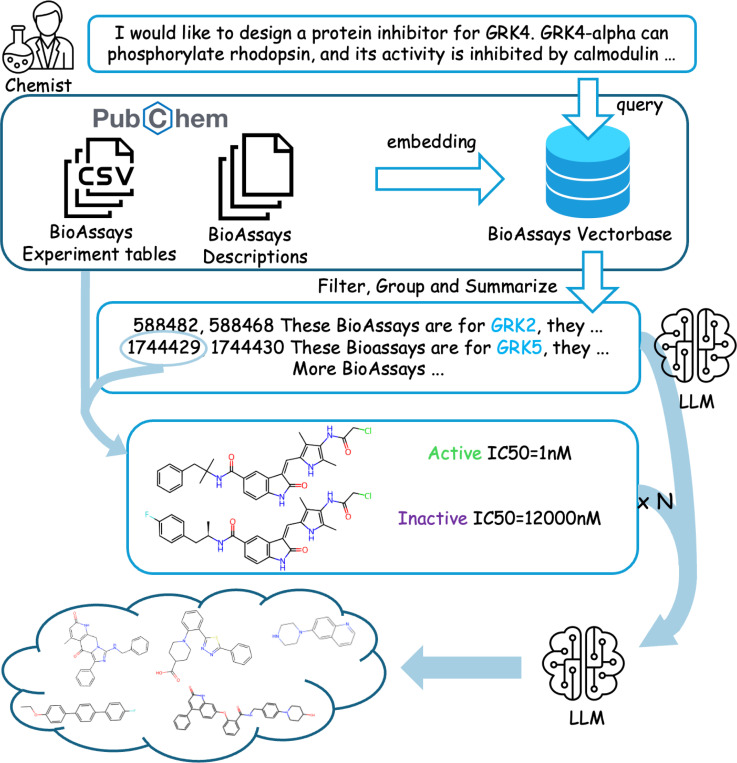
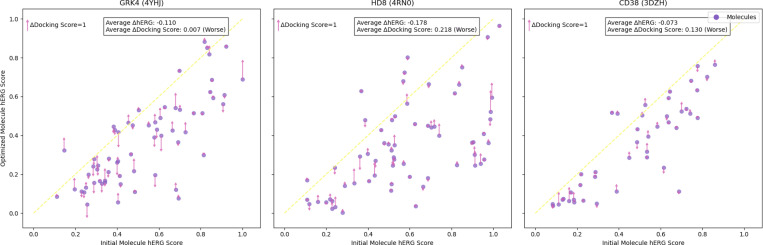
Scientific databases aggregate vast amounts of quantitative data alongside descriptive text. In biochemistry, molecule screening assays evaluate candidate molecules' functional responses against disease targets. Unstructured text that describes the biological mechanisms through which these targets operate, experimental screening protocols, and other attributes of assays offer rich information for drug discovery campaigns but has been untapped because of that unstructured format. We present Assay2Mol, a large language model-based workflow that can capitalize on the vast existing biochemical screening assays for early-stage drug discovery. Assay2Mol retrieves existing assay records involving targets similar to the new target and generates candidate molecules using in-context learning with the retrieved assay screening data. Assay2Mol outperforms recent machine learning approaches that generate candidate ligand molecules for target protein structures, while also promoting more synthesizable molecule generation.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


