Zhe Wang, Keqian Li, Suyuan Peng, Lihong Liu, Xiaolin Yang, Keyu Yao, Heinrich Herre, Yan Zhu
{"title":"基于大语言模型的中药方剂分类加权投票方法:算法开发与验证研究。","authors":"Zhe Wang, Keqian Li, Suyuan Peng, Lihong Liu, Xiaolin Yang, Keyu Yao, Heinrich Herre, Yan Zhu","doi":"10.2196/69286","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Several clinical cases and experiments have demonstrated the effectiveness of traditional Chinese medicine (TCM) formulas in treating and preventing diseases. These formulas contain critical information about their ingredients, efficacy, and indications. Classifying TCM formulas based on this information can effectively standardize TCM formulas management, support clinical and research applications, and promote the modernization and scientific use of TCM. To further advance this task, TCM formulas can be classified using various approaches, including manual classification, machine learning, and deep learning. Additionally, large language models (LLMs) are gaining prominence in the biomedical field. Integrating LLMs into TCM research could significantly enhance and accelerate the discovery of TCM knowledge by leveraging their advanced linguistic understanding and contextual reasoning capabilities.</p><p><strong>Objective: </strong>The objective of this study is to evaluate the performance of different LLMs in the TCM formula classification task. Additionally, by employing ensemble learning with multiple fine-tuned LLMs, this study aims to enhance classification accuracy.</p><p><strong>Methods: </strong>The data for the TCM formula were manually refined and cleaned. We selected 10 LLMs that support Chinese for fine-tuning. We then employed an ensemble learning approach that combined the predictions of multiple models using both hard and weighted voting, with weights determined by the average accuracy of each model. Finally, we selected the top 5 most effective models from each series of LLMs for weighted voting (top 5) and the top 3 most accurate models of 10 for weighted voting (top 3).</p><p><strong>Results: </strong>A total of 2441 TCM formulas were curated manually from multiple sources, including the Coding Rules for Chinese Medicinal Formulas and Their Codes, the Chinese National Medical Insurance Catalog for proprietary Chinese medicines, textbooks of TCM formulas, and TCM literature. The dataset was divided into a training set of 1999 TCM formulas and test set of 442 TCM formulas. The testing results showed that Qwen-14B achieved the highest accuracy of 75.32% among the single models. The accuracy rates for hard voting, weighted voting, weighted voting (top 5), and weighted voting (top 3) were 75.79%, 76.47%, 75.57%, and 77.15%, respectively.</p><p><strong>Conclusions: </strong>This study aims to explore the effectiveness of LLMs in the TCM formula classification task. To this end, we propose an ensemble learning method that integrates multiple fine-tuned LLMs through a voting mechanism. This method not only improves classification accuracy but also enhances the existing classification system for classifying the efficacy of TCM formula.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e69286"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12292024/pdf/","citationCount":"0","resultStr":"{\"title\":\"A Weighted Voting Approach for Traditional Chinese Medicine Formula Classification Using Large Language Models: Algorithm Development and Validation Study.\",\"authors\":\"Zhe Wang, Keqian Li, Suyuan Peng, Lihong Liu, Xiaolin Yang, Keyu Yao, Heinrich Herre, Yan Zhu\",\"doi\":\"10.2196/69286\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Several clinical cases and experiments have demonstrated the effectiveness of traditional Chinese medicine (TCM) formulas in treating and preventing diseases. These formulas contain critical information about their ingredients, efficacy, and indications. Classifying TCM formulas based on this information can effectively standardize TCM formulas management, support clinical and research applications, and promote the modernization and scientific use of TCM. To further advance this task, TCM formulas can be classified using various approaches, including manual classification, machine learning, and deep learning. Additionally, large language models (LLMs) are gaining prominence in the biomedical field. Integrating LLMs into TCM research could significantly enhance and accelerate the discovery of TCM knowledge by leveraging their advanced linguistic understanding and contextual reasoning capabilities.</p><p><strong>Objective: </strong>The objective of this study is to evaluate the performance of different LLMs in the TCM formula classification task. Additionally, by employing ensemble learning with multiple fine-tuned LLMs, this study aims to enhance classification accuracy.</p><p><strong>Methods: </strong>The data for the TCM formula were manually refined and cleaned. We selected 10 LLMs that support Chinese for fine-tuning. We then employed an ensemble learning approach that combined the predictions of multiple models using both hard and weighted voting, with weights determined by the average accuracy of each model. Finally, we selected the top 5 most effective models from each series of LLMs for weighted voting (top 5) and the top 3 most accurate models of 10 for weighted voting (top 3).</p><p><strong>Results: </strong>A total of 2441 TCM formulas were curated manually from multiple sources, including the Coding Rules for Chinese Medicinal Formulas and Their Codes, the Chinese National Medical Insurance Catalog for proprietary Chinese medicines, textbooks of TCM formulas, and TCM literature. The dataset was divided into a training set of 1999 TCM formulas and test set of 442 TCM formulas. The testing results showed that Qwen-14B achieved the highest accuracy of 75.32% among the single models. The accuracy rates for hard voting, weighted voting, weighted voting (top 5), and weighted voting (top 3) were 75.79%, 76.47%, 75.57%, and 77.15%, respectively.</p><p><strong>Conclusions: </strong>This study aims to explore the effectiveness of LLMs in the TCM formula classification task. To this end, we propose an ensemble learning method that integrates multiple fine-tuned LLMs through a voting mechanism. This method not only improves classification accuracy but also enhances the existing classification system for classifying the efficacy of TCM formula.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"13 \",\"pages\":\"e69286\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-07-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12292024/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/69286\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/69286","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
A Weighted Voting Approach for Traditional Chinese Medicine Formula Classification Using Large Language Models: Algorithm Development and Validation Study.
Background: Several clinical cases and experiments have demonstrated the effectiveness of traditional Chinese medicine (TCM) formulas in treating and preventing diseases. These formulas contain critical information about their ingredients, efficacy, and indications. Classifying TCM formulas based on this information can effectively standardize TCM formulas management, support clinical and research applications, and promote the modernization and scientific use of TCM. To further advance this task, TCM formulas can be classified using various approaches, including manual classification, machine learning, and deep learning. Additionally, large language models (LLMs) are gaining prominence in the biomedical field. Integrating LLMs into TCM research could significantly enhance and accelerate the discovery of TCM knowledge by leveraging their advanced linguistic understanding and contextual reasoning capabilities.
Objective: The objective of this study is to evaluate the performance of different LLMs in the TCM formula classification task. Additionally, by employing ensemble learning with multiple fine-tuned LLMs, this study aims to enhance classification accuracy.
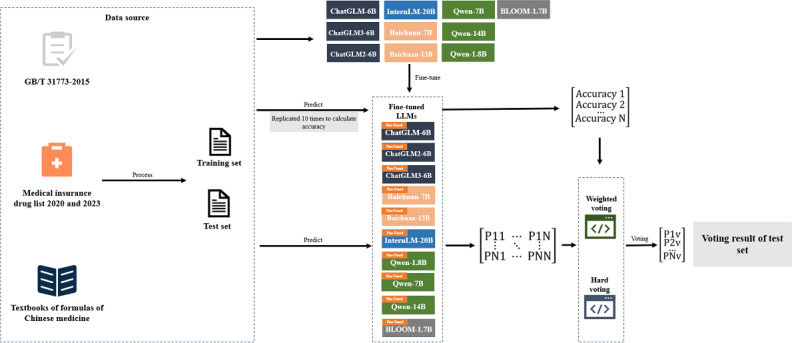
Methods: The data for the TCM formula were manually refined and cleaned. We selected 10 LLMs that support Chinese for fine-tuning. We then employed an ensemble learning approach that combined the predictions of multiple models using both hard and weighted voting, with weights determined by the average accuracy of each model. Finally, we selected the top 5 most effective models from each series of LLMs for weighted voting (top 5) and the top 3 most accurate models of 10 for weighted voting (top 3).
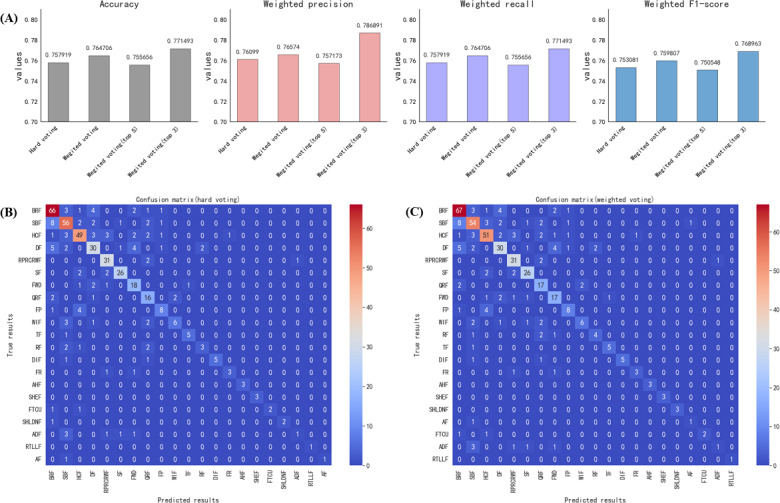
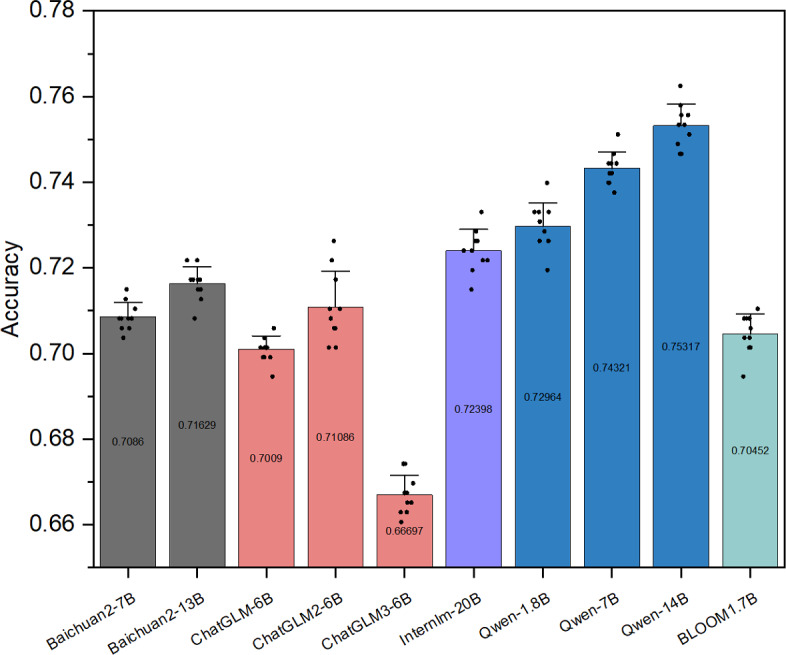
Results: A total of 2441 TCM formulas were curated manually from multiple sources, including the Coding Rules for Chinese Medicinal Formulas and Their Codes, the Chinese National Medical Insurance Catalog for proprietary Chinese medicines, textbooks of TCM formulas, and TCM literature. The dataset was divided into a training set of 1999 TCM formulas and test set of 442 TCM formulas. The testing results showed that Qwen-14B achieved the highest accuracy of 75.32% among the single models. The accuracy rates for hard voting, weighted voting, weighted voting (top 5), and weighted voting (top 3) were 75.79%, 76.47%, 75.57%, and 77.15%, respectively.
Conclusions: This study aims to explore the effectiveness of LLMs in the TCM formula classification task. To this end, we propose an ensemble learning method that integrates multiple fine-tuned LLMs through a voting mechanism. This method not only improves classification accuracy but also enhances the existing classification system for classifying the efficacy of TCM formula.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


