{"title":"FakeMusicCaps:通过文本到音乐模型生成的合成音乐的检测和归属数据集。","authors":"Luca Comanducci, Paolo Bestagini, Stefano Tubaro","doi":"10.3390/jimaging11070242","DOIUrl":null,"url":null,"abstract":"<p><p>Text-to-music (TTM) models have recently revolutionized the automatic music generation research field, specifically by being able to generate music that sounds more plausible than all previous state-of-the-art models and by lowering the technical proficiency needed to use them. For these reasons, they have readily started to be adopted for commercial uses and music production practices. This widespread diffusion of TTMs poses several concerns regarding copyright violation and rightful attribution, posing the need of serious consideration of them by the audio forensics community. In this paper, we tackle the problem of detection and attribution of TTM-generated data. We propose a dataset, FakeMusicCaps, that contains several versions of the music-caption pairs dataset MusicCaps regenerated via several state-of-the-art TTM techniques. We evaluate the proposed dataset by performing initial experiments regarding the detection and attribution of TTM-generated audio considering both closed-set and open-set classification.</p>","PeriodicalId":37035,"journal":{"name":"Journal of Imaging","volume":"11 7","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2025-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12295441/pdf/","citationCount":"0","resultStr":"{\"title\":\"FakeMusicCaps: A Dataset for Detection and Attribution of Synthetic Music Generated via Text-to-Music Models.\",\"authors\":\"Luca Comanducci, Paolo Bestagini, Stefano Tubaro\",\"doi\":\"10.3390/jimaging11070242\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Text-to-music (TTM) models have recently revolutionized the automatic music generation research field, specifically by being able to generate music that sounds more plausible than all previous state-of-the-art models and by lowering the technical proficiency needed to use them. For these reasons, they have readily started to be adopted for commercial uses and music production practices. This widespread diffusion of TTMs poses several concerns regarding copyright violation and rightful attribution, posing the need of serious consideration of them by the audio forensics community. In this paper, we tackle the problem of detection and attribution of TTM-generated data. We propose a dataset, FakeMusicCaps, that contains several versions of the music-caption pairs dataset MusicCaps regenerated via several state-of-the-art TTM techniques. We evaluate the proposed dataset by performing initial experiments regarding the detection and attribution of TTM-generated audio considering both closed-set and open-set classification.</p>\",\"PeriodicalId\":37035,\"journal\":{\"name\":\"Journal of Imaging\",\"volume\":\"11 7\",\"pages\":\"\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2025-07-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12295441/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Imaging\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/jimaging11070242\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Imaging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/jimaging11070242","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY","Score":null,"Total":0}
FakeMusicCaps: A Dataset for Detection and Attribution of Synthetic Music Generated via Text-to-Music Models.
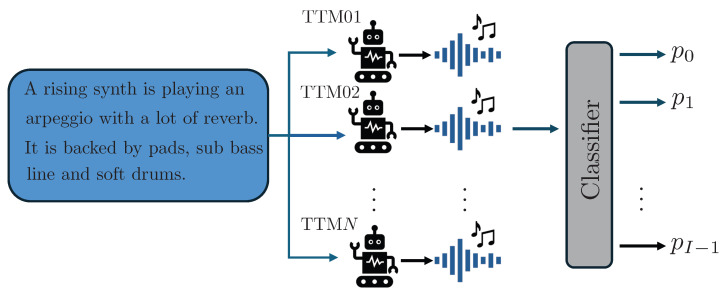
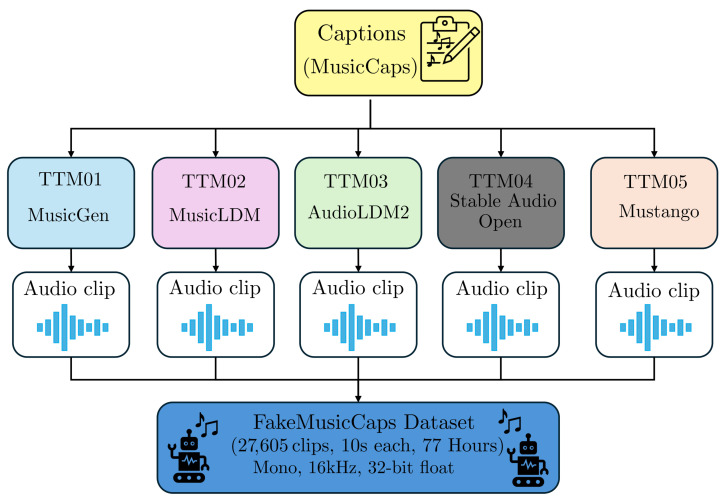
Text-to-music (TTM) models have recently revolutionized the automatic music generation research field, specifically by being able to generate music that sounds more plausible than all previous state-of-the-art models and by lowering the technical proficiency needed to use them. For these reasons, they have readily started to be adopted for commercial uses and music production practices. This widespread diffusion of TTMs poses several concerns regarding copyright violation and rightful attribution, posing the need of serious consideration of them by the audio forensics community. In this paper, we tackle the problem of detection and attribution of TTM-generated data. We propose a dataset, FakeMusicCaps, that contains several versions of the music-caption pairs dataset MusicCaps regenerated via several state-of-the-art TTM techniques. We evaluate the proposed dataset by performing initial experiments regarding the detection and attribution of TTM-generated audio considering both closed-set and open-set classification.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


