Jiahao Zhang, Bowen Wang, Hong Liu, Liangzhi Li, Yuta Nakashima, Hajime Nagahara
{"title":"E-InMeMo:视觉情境学习的增强提示。","authors":"Jiahao Zhang, Bowen Wang, Hong Liu, Liangzhi Li, Yuta Nakashima, Hajime Nagahara","doi":"10.3390/jimaging11070232","DOIUrl":null,"url":null,"abstract":"<p><p>Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose <b>E</b>nhanced <b>In</b>struct <b>Me</b><b>Mo</b>re (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL.</p>","PeriodicalId":37035,"journal":{"name":"Journal of Imaging","volume":"11 7","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2025-07-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12295390/pdf/","citationCount":"0","resultStr":"{\"title\":\"E-InMeMo: Enhanced Prompting for Visual In-Context Learning.\",\"authors\":\"Jiahao Zhang, Bowen Wang, Hong Liu, Liangzhi Li, Yuta Nakashima, Hajime Nagahara\",\"doi\":\"10.3390/jimaging11070232\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose <b>E</b>nhanced <b>In</b>struct <b>Me</b><b>Mo</b>re (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL.</p>\",\"PeriodicalId\":37035,\"journal\":{\"name\":\"Journal of Imaging\",\"volume\":\"11 7\",\"pages\":\"\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2025-07-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12295390/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Imaging\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/jimaging11070232\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Imaging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/jimaging11070232","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY","Score":null,"Total":0}
E-InMeMo: Enhanced Prompting for Visual In-Context Learning.
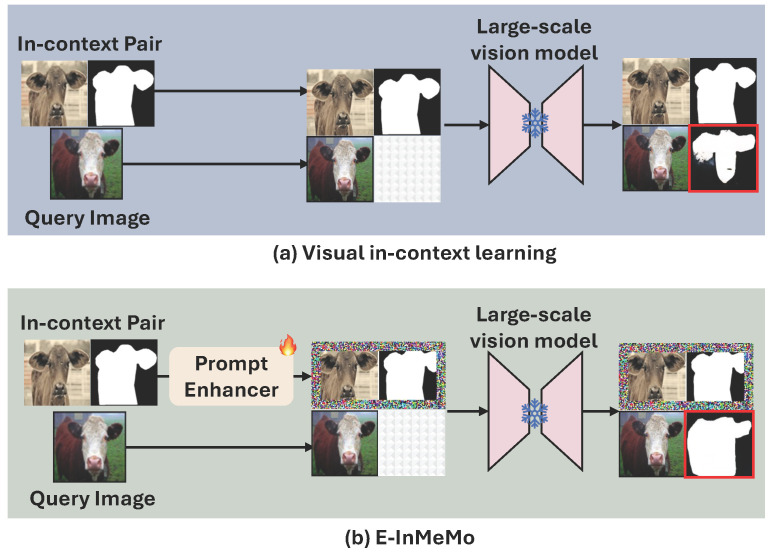
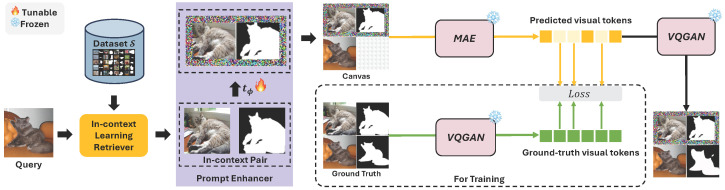
Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose Enhanced Instruct MeMore (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


