{"title":"使用自然语言处理从电子健康记录中提取健康的社会决定因素。","authors":"Zhenghua Chen, Patricia Lasserre, Angela Lin, Rasika Rajapakshe","doi":"10.1200/CCI-24-00317","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Social Determinants of Health (SDoH) have a significant effect on health outcomes and inequalities. SDoH can be extracted from electronic health records (EHR) to aid policy development and research to improve population health. Automated extraction using artificial intelligence (AI) can improve efficiency and cost-effectiveness. The focus of this study was to autonomously extract comprehensive SDoH details from EHR using a natural language processing (NLP)-based AI pipeline.</p><p><strong>Materials and methods: </strong>A curated set of 1,000 BC Cancer clinical documents with concentrated SDoH information served as the reference standard for training and evaluating NLP models. Two pipelines were used: an open-source pipeline trained on the annotated medical documents and an industrial pretrained solution used as a benchmark. Three experiments optimized the first pipeline's performance, assessing the effect of including subtype word positions during training. The superior open-source pipeline was then used to extract SDoH information from 13,258 oncology documents.</p><p><strong>Results: </strong>The open-source pipeline achieved an average F1 score accuracy of 0.88 on the validation data set for extracting 13 SDoH factors, surpassing the benchmark by 5%. It excelled in detailed subtype extraction, while the benchmark performed better in identifying rarely annotated SDoH information in BC Cancer data set. Overall, 60,717 SDoH factors and associated details were extracted from BC Cancer EHR oncology documents. The most frequently extracted SDoH factors included tobacco use, employment status, marital status, alcohol consumption, and living status, occurring between 8k to 12k times.</p><p><strong>Conclusion: </strong>This study demonstrates the potential of an NLP pipeline to extract SDoH factors from clinical notes, with strong performance on limited data, although data set-specific adjustments are needed for broader application across institutions.</p>","PeriodicalId":51626,"journal":{"name":"JCO Clinical Cancer Informatics","volume":"9 ","pages":"e2400317"},"PeriodicalIF":2.8000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12309507/pdf/","citationCount":"0","resultStr":"{\"title\":\"Extraction of Social Determinants of Health From Electronic Health Records Using Natural Language Processing.\",\"authors\":\"Zhenghua Chen, Patricia Lasserre, Angela Lin, Rasika Rajapakshe\",\"doi\":\"10.1200/CCI-24-00317\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Social Determinants of Health (SDoH) have a significant effect on health outcomes and inequalities. SDoH can be extracted from electronic health records (EHR) to aid policy development and research to improve population health. Automated extraction using artificial intelligence (AI) can improve efficiency and cost-effectiveness. The focus of this study was to autonomously extract comprehensive SDoH details from EHR using a natural language processing (NLP)-based AI pipeline.</p><p><strong>Materials and methods: </strong>A curated set of 1,000 BC Cancer clinical documents with concentrated SDoH information served as the reference standard for training and evaluating NLP models. Two pipelines were used: an open-source pipeline trained on the annotated medical documents and an industrial pretrained solution used as a benchmark. Three experiments optimized the first pipeline's performance, assessing the effect of including subtype word positions during training. The superior open-source pipeline was then used to extract SDoH information from 13,258 oncology documents.</p><p><strong>Results: </strong>The open-source pipeline achieved an average F1 score accuracy of 0.88 on the validation data set for extracting 13 SDoH factors, surpassing the benchmark by 5%. It excelled in detailed subtype extraction, while the benchmark performed better in identifying rarely annotated SDoH information in BC Cancer data set. Overall, 60,717 SDoH factors and associated details were extracted from BC Cancer EHR oncology documents. The most frequently extracted SDoH factors included tobacco use, employment status, marital status, alcohol consumption, and living status, occurring between 8k to 12k times.</p><p><strong>Conclusion: </strong>This study demonstrates the potential of an NLP pipeline to extract SDoH factors from clinical notes, with strong performance on limited data, although data set-specific adjustments are needed for broader application across institutions.</p>\",\"PeriodicalId\":51626,\"journal\":{\"name\":\"JCO Clinical Cancer Informatics\",\"volume\":\"9 \",\"pages\":\"e2400317\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12309507/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JCO Clinical Cancer Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1200/CCI-24-00317\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/7/23 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JCO Clinical Cancer Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1200/CCI-24-00317","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/23 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
Extraction of Social Determinants of Health From Electronic Health Records Using Natural Language Processing.
Purpose: Social Determinants of Health (SDoH) have a significant effect on health outcomes and inequalities. SDoH can be extracted from electronic health records (EHR) to aid policy development and research to improve population health. Automated extraction using artificial intelligence (AI) can improve efficiency and cost-effectiveness. The focus of this study was to autonomously extract comprehensive SDoH details from EHR using a natural language processing (NLP)-based AI pipeline.
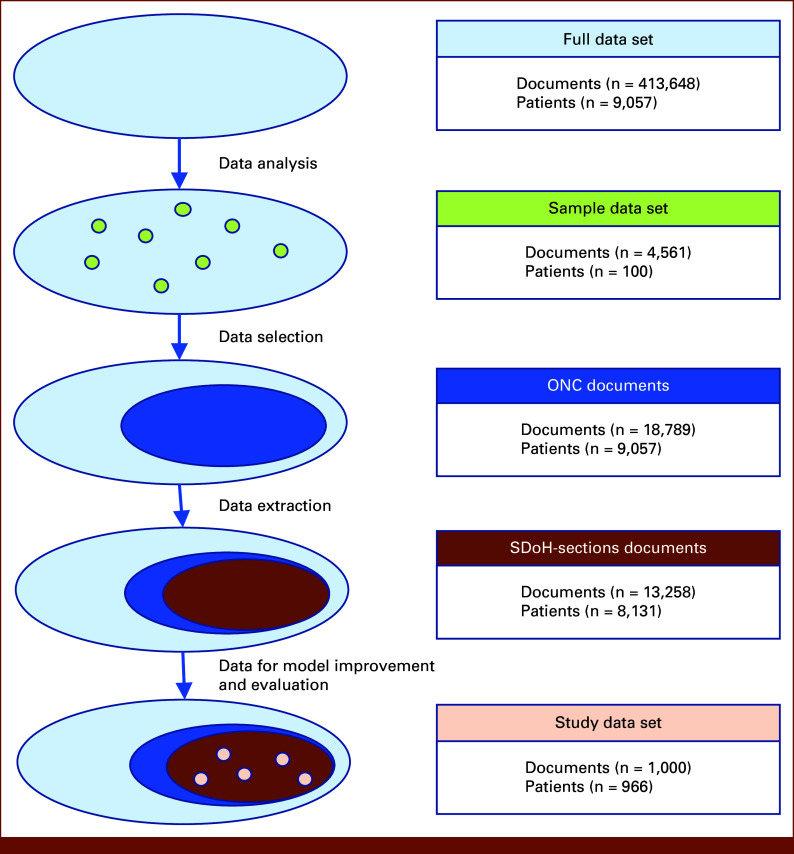
Materials and methods: A curated set of 1,000 BC Cancer clinical documents with concentrated SDoH information served as the reference standard for training and evaluating NLP models. Two pipelines were used: an open-source pipeline trained on the annotated medical documents and an industrial pretrained solution used as a benchmark. Three experiments optimized the first pipeline's performance, assessing the effect of including subtype word positions during training. The superior open-source pipeline was then used to extract SDoH information from 13,258 oncology documents.
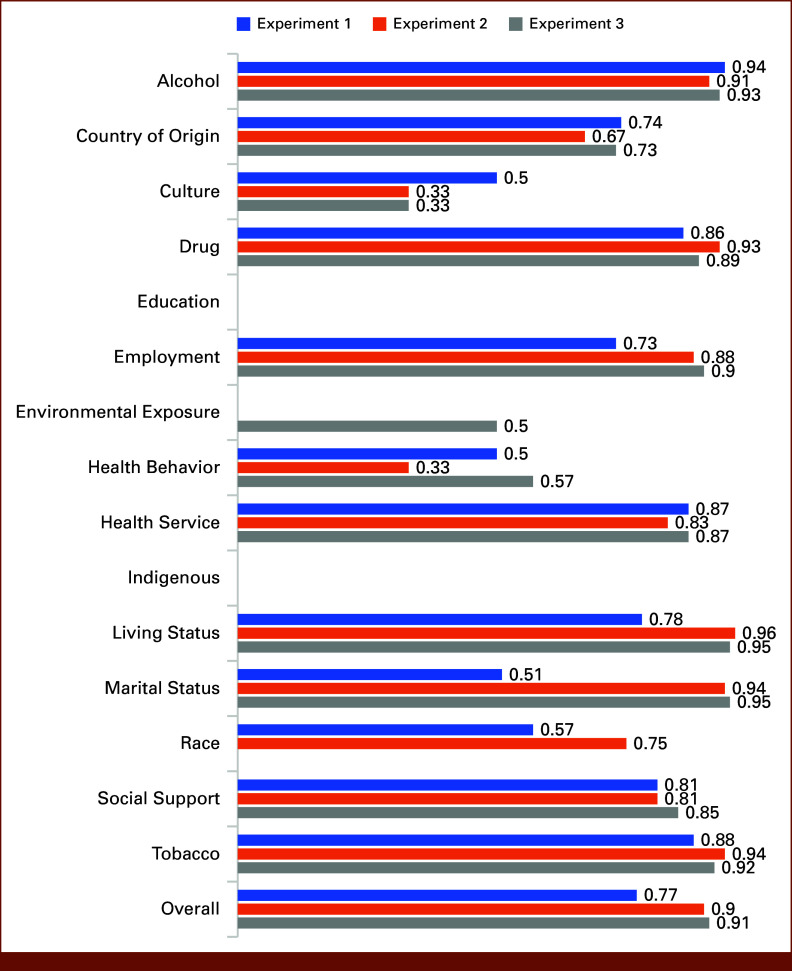
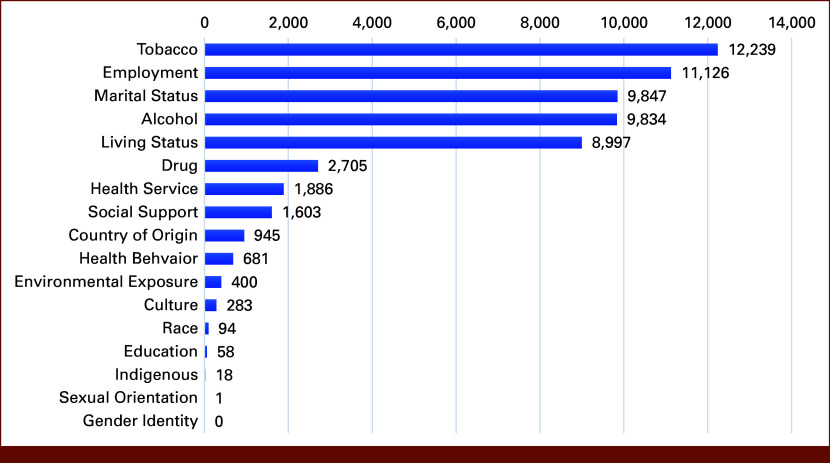
Results: The open-source pipeline achieved an average F1 score accuracy of 0.88 on the validation data set for extracting 13 SDoH factors, surpassing the benchmark by 5%. It excelled in detailed subtype extraction, while the benchmark performed better in identifying rarely annotated SDoH information in BC Cancer data set. Overall, 60,717 SDoH factors and associated details were extracted from BC Cancer EHR oncology documents. The most frequently extracted SDoH factors included tobacco use, employment status, marital status, alcohol consumption, and living status, occurring between 8k to 12k times.
Conclusion: This study demonstrates the potential of an NLP pipeline to extract SDoH factors from clinical notes, with strong performance on limited data, although data set-specific adjustments are needed for broader application across institutions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


