Giulio Formenti, Bonhwang Koo, Marco Sollitto, Jennifer Balacco, Nadolina Brajuka, Richard Burhans, Erick Duarte, Alice M Giani, Kirsty McCaffrey, Jack A Medico, Eugene W Myers, Patrik Smeds, Anton Nekrutenko, Erich D Jarvis
{"title":"使用rdeval在规模上评估测序读数。","authors":"Giulio Formenti, Bonhwang Koo, Marco Sollitto, Jennifer Balacco, Nadolina Brajuka, Richard Burhans, Erick Duarte, Alice M Giani, Kirsty McCaffrey, Jack A Medico, Eugene W Myers, Patrik Smeds, Anton Nekrutenko, Erich D Jarvis","doi":"10.1093/bioinformatics/btaf416","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Large sequencing datasets are being produced and deposited into public archives at unprecedented rates. The availability of tools that can reliably and efficiently generate and store sequencing read summary statistics has become critical.</p><p><strong>Results: </strong>As part of the effort by the Vertebrate Genomes Project (VGP) to generate high-quality reference genomes at scale, we sought to address the community's need for efficient sequence data evaluation by developing rdeval, a standalone tool to quickly compute and interactively display sequencing read metrics. Rdeval can either run on the fly or store key sequence data metrics in tiny read 'snapshot' files. Statistics can then be efficiently recalled from snapshots for additional processing. Rdeval can convert fa*[.gz] files to and from other popular formats including BAM and CRAM for better compression. Overall, while CRAM achieves the best compression, the gain compared to BAM is marginal, and BAM achieves the best compromise between data compression and access speed. Rdeval also generates a detailed visual report with multiple data analytics that can be exported in various formats. We showcase rdeval's functionalities using long-read data from different sequencing platforms and species, including human. For PacBio long-read sequencing, our analysis shows dramatic improvements in both read length and quality over time, as well as the benefit of increased coverage for genome assembly, though the magnitude varies by taxa.</p><p><strong>Availability and implementation: </strong>Rdeval is implemented in C++ for data processing and in R for data visualization. Precompiled releases (Linux, MacOS, Windows) and commented source code for rdeval are available under MIT license at https://github.com/vgl-hub/rdeval. Documentation is available on ReadTheDocs (https://rdeval-documentation.readthedocs.io). Rdeval is also available in Bioconda and in Galaxy (https://usegalaxy.org). An automated test workflow ensures the consistency of software updates.</p>","PeriodicalId":93899,"journal":{"name":"Bioinformatics (Oxford, England)","volume":" ","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12401588/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluation of sequencing reads at scale using rdeval.\",\"authors\":\"Giulio Formenti, Bonhwang Koo, Marco Sollitto, Jennifer Balacco, Nadolina Brajuka, Richard Burhans, Erick Duarte, Alice M Giani, Kirsty McCaffrey, Jack A Medico, Eugene W Myers, Patrik Smeds, Anton Nekrutenko, Erich D Jarvis\",\"doi\":\"10.1093/bioinformatics/btaf416\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Large sequencing datasets are being produced and deposited into public archives at unprecedented rates. The availability of tools that can reliably and efficiently generate and store sequencing read summary statistics has become critical.</p><p><strong>Results: </strong>As part of the effort by the Vertebrate Genomes Project (VGP) to generate high-quality reference genomes at scale, we sought to address the community's need for efficient sequence data evaluation by developing rdeval, a standalone tool to quickly compute and interactively display sequencing read metrics. Rdeval can either run on the fly or store key sequence data metrics in tiny read 'snapshot' files. Statistics can then be efficiently recalled from snapshots for additional processing. Rdeval can convert fa*[.gz] files to and from other popular formats including BAM and CRAM for better compression. Overall, while CRAM achieves the best compression, the gain compared to BAM is marginal, and BAM achieves the best compromise between data compression and access speed. Rdeval also generates a detailed visual report with multiple data analytics that can be exported in various formats. We showcase rdeval's functionalities using long-read data from different sequencing platforms and species, including human. For PacBio long-read sequencing, our analysis shows dramatic improvements in both read length and quality over time, as well as the benefit of increased coverage for genome assembly, though the magnitude varies by taxa.</p><p><strong>Availability and implementation: </strong>Rdeval is implemented in C++ for data processing and in R for data visualization. Precompiled releases (Linux, MacOS, Windows) and commented source code for rdeval are available under MIT license at https://github.com/vgl-hub/rdeval. Documentation is available on ReadTheDocs (https://rdeval-documentation.readthedocs.io). Rdeval is also available in Bioconda and in Galaxy (https://usegalaxy.org). An automated test workflow ensures the consistency of software updates.</p>\",\"PeriodicalId\":93899,\"journal\":{\"name\":\"Bioinformatics (Oxford, England)\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2025-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12401588/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics (Oxford, England)\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioinformatics/btaf416\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics (Oxford, England)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btaf416","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Evaluation of sequencing reads at scale using rdeval.
Motivation: Large sequencing datasets are being produced and deposited into public archives at unprecedented rates. The availability of tools that can reliably and efficiently generate and store sequencing read summary statistics has become critical.
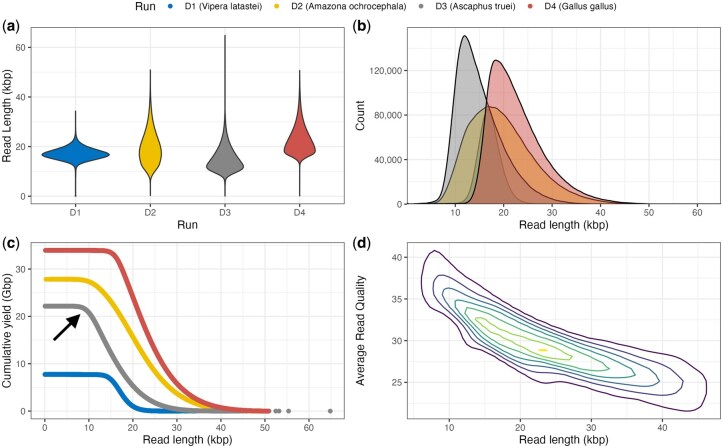
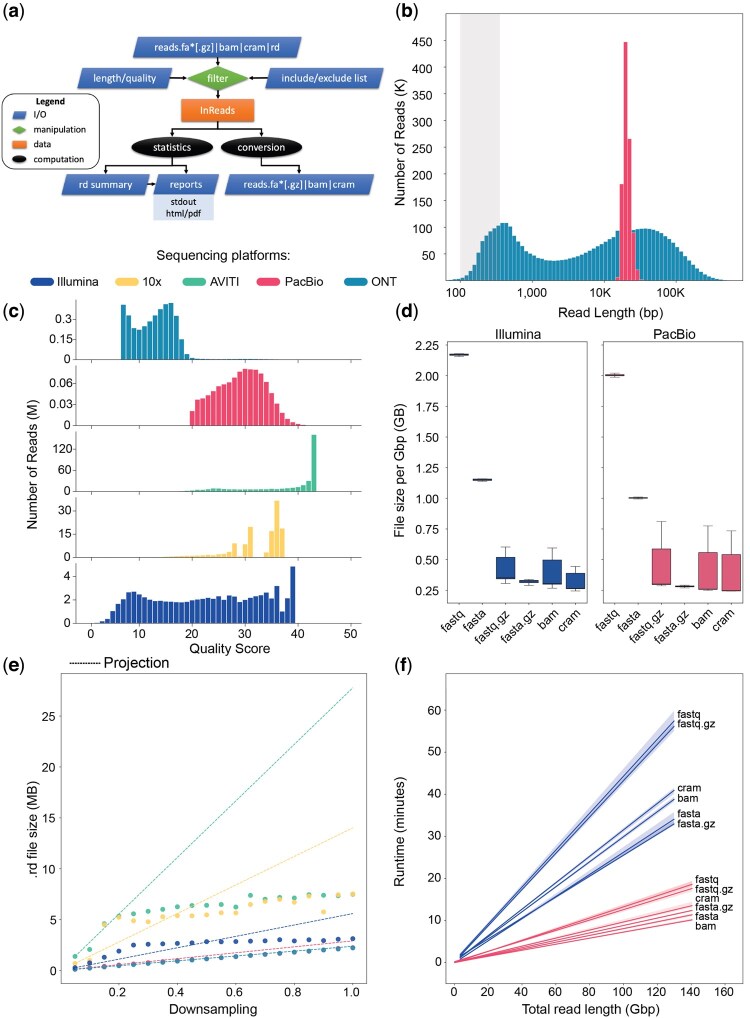
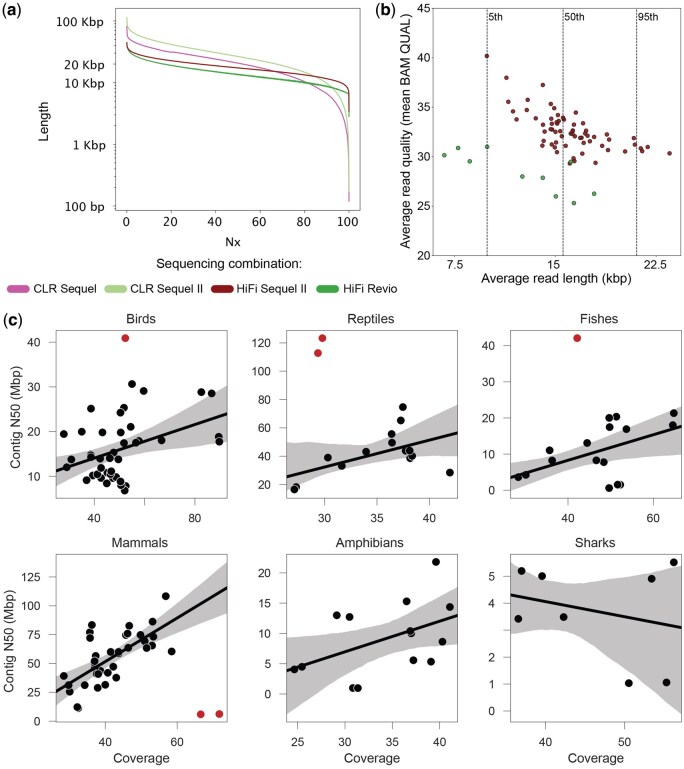
Results: As part of the effort by the Vertebrate Genomes Project (VGP) to generate high-quality reference genomes at scale, we sought to address the community's need for efficient sequence data evaluation by developing rdeval, a standalone tool to quickly compute and interactively display sequencing read metrics. Rdeval can either run on the fly or store key sequence data metrics in tiny read 'snapshot' files. Statistics can then be efficiently recalled from snapshots for additional processing. Rdeval can convert fa*[.gz] files to and from other popular formats including BAM and CRAM for better compression. Overall, while CRAM achieves the best compression, the gain compared to BAM is marginal, and BAM achieves the best compromise between data compression and access speed. Rdeval also generates a detailed visual report with multiple data analytics that can be exported in various formats. We showcase rdeval's functionalities using long-read data from different sequencing platforms and species, including human. For PacBio long-read sequencing, our analysis shows dramatic improvements in both read length and quality over time, as well as the benefit of increased coverage for genome assembly, though the magnitude varies by taxa.
Availability and implementation: Rdeval is implemented in C++ for data processing and in R for data visualization. Precompiled releases (Linux, MacOS, Windows) and commented source code for rdeval are available under MIT license at https://github.com/vgl-hub/rdeval. Documentation is available on ReadTheDocs (https://rdeval-documentation.readthedocs.io). Rdeval is also available in Bioconda and in Galaxy (https://usegalaxy.org). An automated test workflow ensures the consistency of software updates.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


