{"title":"用于估计超声检查候补名单优先级的训练语言模型:算法开发和验证。","authors":"Kanato Masayoshi, Masahiro Hashimoto, Naoki Toda, Hirozumi Mori, Goh Kobayashi, Hasnine Haque, Mizuki So, Masahiro Jinzaki","doi":"10.2196/68020","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Ultrasound examinations, while valuable, are time-consuming and often limited in availability. Consequently, many hospitals implement reservation systems; however, these systems typically lack prioritization for examination purposes. Hence, our hospital uses a waitlist system that prioritizes examination requests based on their clinical value when slots become available due to cancellations. This system, however, requires a manual review of examination purposes, which are recorded in free-form text. We hypothesized that artificial intelligence language models could preliminarily estimate the priority of requests before manual reviews.</p><p><strong>Objective: </strong>This study aimed to investigate potential challenges associated with using language models for estimating the priority of medical examination requests and to evaluate the performance of language models in processing Japanese medical texts.</p><p><strong>Methods: </strong>We retrospectively collected ultrasound examination requests from the waitlist system at Keio University Hospital, spanning January 2020 to March 2023. Each request comprised an examination purpose documented by the requesting physician and a 6-tier priority level assigned by a radiologist during the clinical workflow. We fine-tuned JMedRoBERTa, Luke, OpenCalm, and LLaMA2 under two conditions: (1) tuning only the final layer and (2) tuning all layers using either standard backpropagation or low-rank adaptation.</p><p><strong>Results: </strong>We had 2335 and 204 requests in the training and test datasets post cleaning. When only the final layers were tuned, JMedRoBERTa outperformed the other models (Kendall coefficient=0.225). With full fine-tuning, JMedRoBERTa continued to perform best (Kendall coefficient=0.254), though with reduced margins compared with the other models. The radiologist's retrospective re-evaluation yielded a Kendall coefficient of 0.221.</p><p><strong>Conclusions: </strong>Language models can estimate the priority of examination requests with accuracy comparable with that of human radiologists. The fine-tuning results indicate that general-purpose language models can be adapted to domain-specific texts (ie, Japanese medical texts) with sufficient fine-tuning. Further research is required to address priority rank ambiguity, expand the dataset across multiple institutions, and explore more recent language models with potentially higher performance or better suitability for this task.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e68020"},"PeriodicalIF":2.0000,"publicationDate":"2025-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12325119/pdf/","citationCount":"0","resultStr":"{\"title\":\"Training Language Models for Estimating Priority Levels in Ultrasound Examination Waitlists: Algorithm Development and Validation.\",\"authors\":\"Kanato Masayoshi, Masahiro Hashimoto, Naoki Toda, Hirozumi Mori, Goh Kobayashi, Hasnine Haque, Mizuki So, Masahiro Jinzaki\",\"doi\":\"10.2196/68020\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Ultrasound examinations, while valuable, are time-consuming and often limited in availability. Consequently, many hospitals implement reservation systems; however, these systems typically lack prioritization for examination purposes. Hence, our hospital uses a waitlist system that prioritizes examination requests based on their clinical value when slots become available due to cancellations. This system, however, requires a manual review of examination purposes, which are recorded in free-form text. We hypothesized that artificial intelligence language models could preliminarily estimate the priority of requests before manual reviews.</p><p><strong>Objective: </strong>This study aimed to investigate potential challenges associated with using language models for estimating the priority of medical examination requests and to evaluate the performance of language models in processing Japanese medical texts.</p><p><strong>Methods: </strong>We retrospectively collected ultrasound examination requests from the waitlist system at Keio University Hospital, spanning January 2020 to March 2023. Each request comprised an examination purpose documented by the requesting physician and a 6-tier priority level assigned by a radiologist during the clinical workflow. We fine-tuned JMedRoBERTa, Luke, OpenCalm, and LLaMA2 under two conditions: (1) tuning only the final layer and (2) tuning all layers using either standard backpropagation or low-rank adaptation.</p><p><strong>Results: </strong>We had 2335 and 204 requests in the training and test datasets post cleaning. When only the final layers were tuned, JMedRoBERTa outperformed the other models (Kendall coefficient=0.225). With full fine-tuning, JMedRoBERTa continued to perform best (Kendall coefficient=0.254), though with reduced margins compared with the other models. The radiologist's retrospective re-evaluation yielded a Kendall coefficient of 0.221.</p><p><strong>Conclusions: </strong>Language models can estimate the priority of examination requests with accuracy comparable with that of human radiologists. The fine-tuning results indicate that general-purpose language models can be adapted to domain-specific texts (ie, Japanese medical texts) with sufficient fine-tuning. Further research is required to address priority rank ambiguity, expand the dataset across multiple institutions, and explore more recent language models with potentially higher performance or better suitability for this task.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e68020\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-07-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12325119/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/68020\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/68020","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Training Language Models for Estimating Priority Levels in Ultrasound Examination Waitlists: Algorithm Development and Validation.
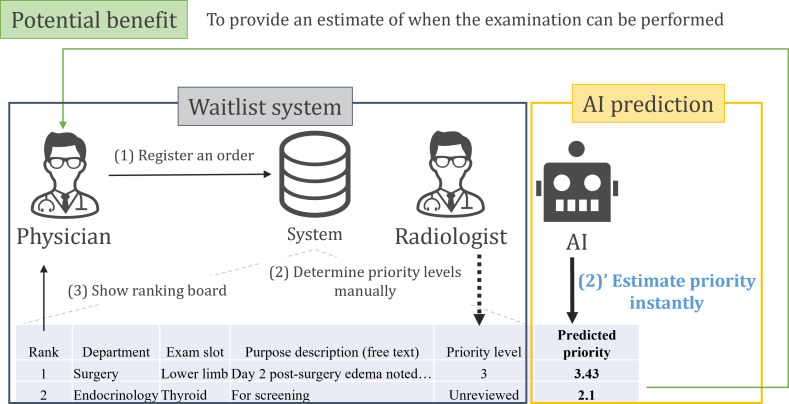
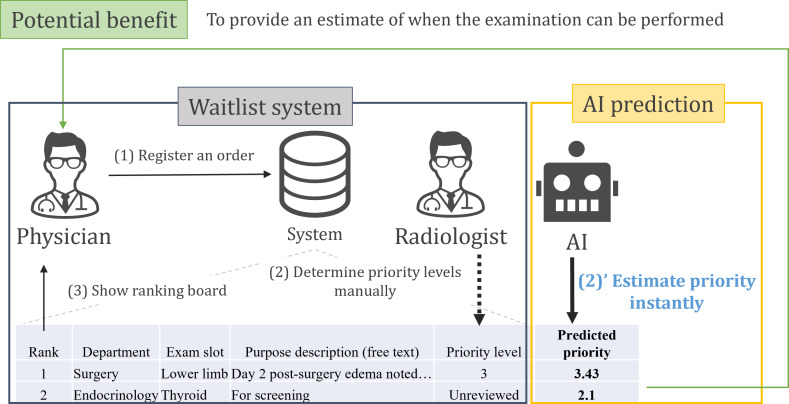
Background: Ultrasound examinations, while valuable, are time-consuming and often limited in availability. Consequently, many hospitals implement reservation systems; however, these systems typically lack prioritization for examination purposes. Hence, our hospital uses a waitlist system that prioritizes examination requests based on their clinical value when slots become available due to cancellations. This system, however, requires a manual review of examination purposes, which are recorded in free-form text. We hypothesized that artificial intelligence language models could preliminarily estimate the priority of requests before manual reviews.
Objective: This study aimed to investigate potential challenges associated with using language models for estimating the priority of medical examination requests and to evaluate the performance of language models in processing Japanese medical texts.
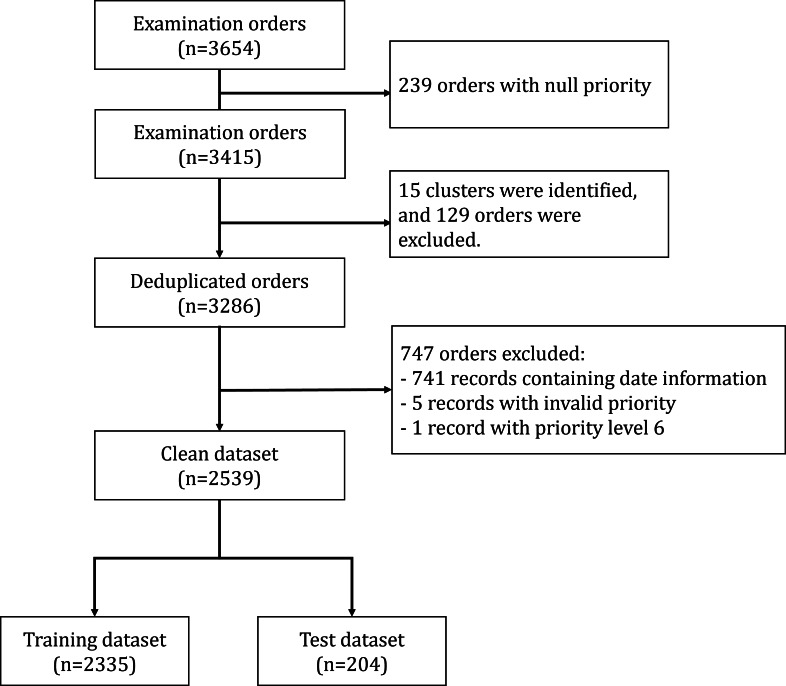
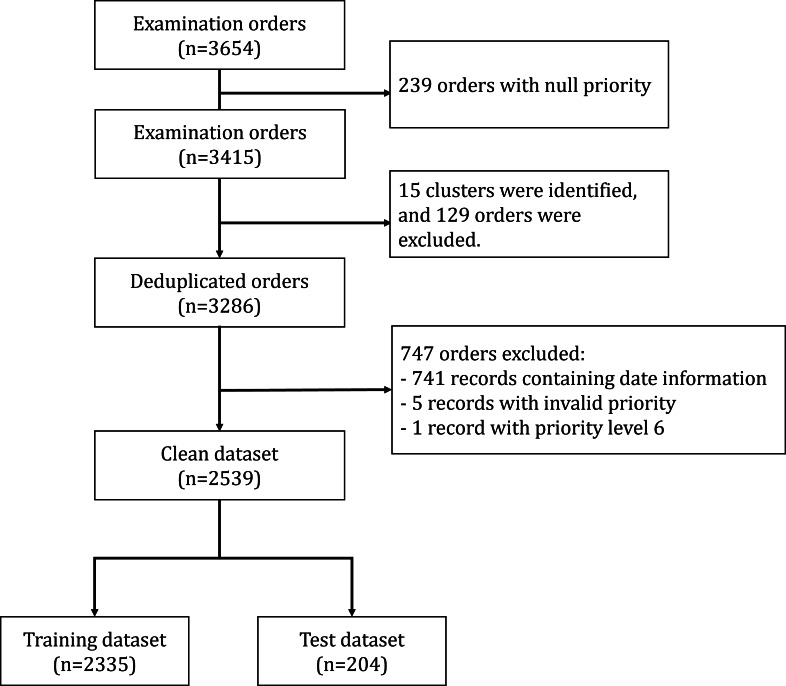
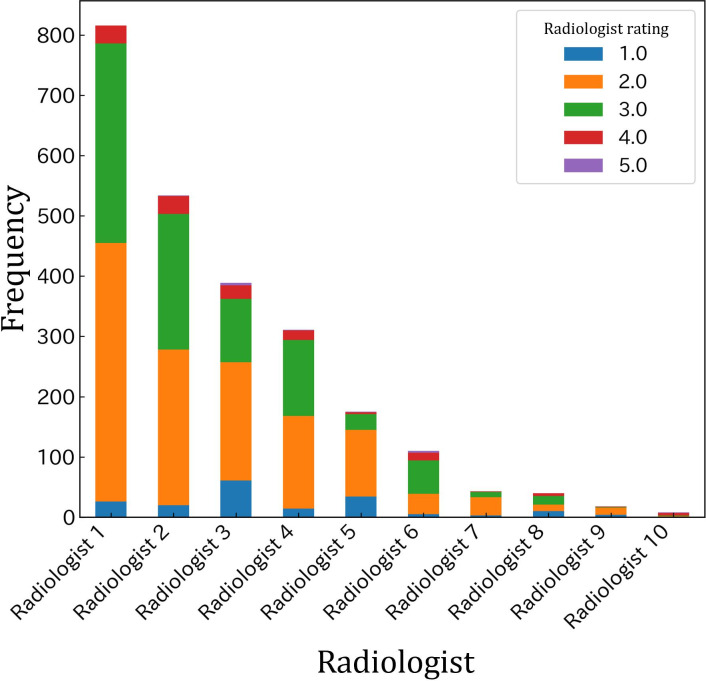
Methods: We retrospectively collected ultrasound examination requests from the waitlist system at Keio University Hospital, spanning January 2020 to March 2023. Each request comprised an examination purpose documented by the requesting physician and a 6-tier priority level assigned by a radiologist during the clinical workflow. We fine-tuned JMedRoBERTa, Luke, OpenCalm, and LLaMA2 under two conditions: (1) tuning only the final layer and (2) tuning all layers using either standard backpropagation or low-rank adaptation.
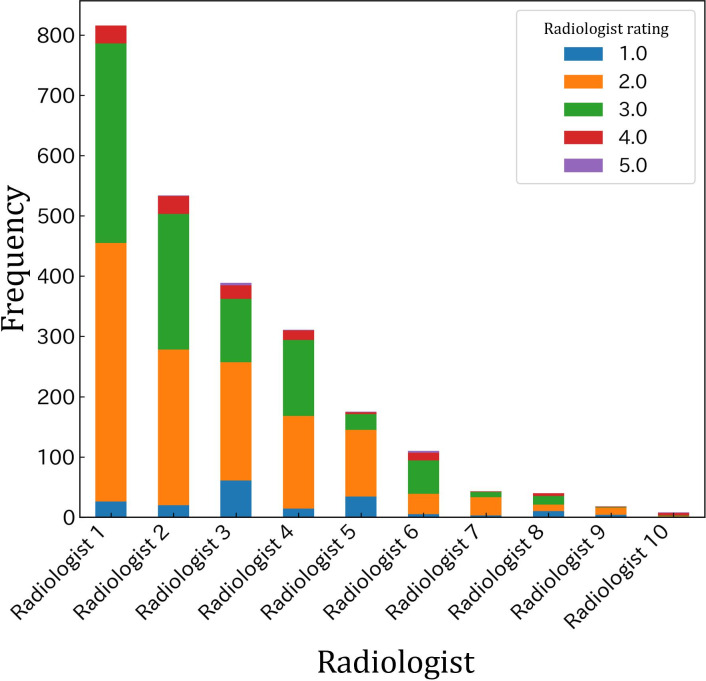
Results: We had 2335 and 204 requests in the training and test datasets post cleaning. When only the final layers were tuned, JMedRoBERTa outperformed the other models (Kendall coefficient=0.225). With full fine-tuning, JMedRoBERTa continued to perform best (Kendall coefficient=0.254), though with reduced margins compared with the other models. The radiologist's retrospective re-evaluation yielded a Kendall coefficient of 0.221.
Conclusions: Language models can estimate the priority of examination requests with accuracy comparable with that of human radiologists. The fine-tuning results indicate that general-purpose language models can be adapted to domain-specific texts (ie, Japanese medical texts) with sufficient fine-tuning. Further research is required to address priority rank ambiguity, expand the dataset across multiple institutions, and explore more recent language models with potentially higher performance or better suitability for this task.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


