Chunyang Li, Michael Stringer, Vikas Patil, Richard Mcshinsky, Deborah Morreall, Christina Yong, Kelli M Rasmussen, Zachary Burningham, Suzanne Tamang, Carolyn S Menendez, Akiko Chiba, Haley A Moss, Sarah Colonna, Kerry Rowe, Daphne Friedman, Michael J Kelley, Ahmad Halwani
{"title":"使用开源大型语言模型从非结构化文本中识别乳腺癌退伍军人生殖系基因测试的访问。","authors":"Chunyang Li, Michael Stringer, Vikas Patil, Richard Mcshinsky, Deborah Morreall, Christina Yong, Kelli M Rasmussen, Zachary Burningham, Suzanne Tamang, Carolyn S Menendez, Akiko Chiba, Haley A Moss, Sarah Colonna, Kerry Rowe, Daphne Friedman, Michael J Kelley, Ahmad Halwani","doi":"10.1200/CCI-24-00263","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>The ability of large language models (LLMs) to identify access to germline genetic testing from unstructured text remains unknown. The Department of Veterans Affairs (VA) assessed access in Veterans with breast cancer by implementing and evaluating the performance of open-source, locally deployable LLMs (Llama 3 70B, Llama 3 8B, and Llama 2 70B) in identifying access from clinical/consult notes.</p><p><strong>Methods: </strong>We identified a cohort of 1,201 Veterans diagnosed with breast cancer between January 1, 2021, and December 31, 2022, who received cancer care within the nationwide VA system and had clinical and/or consult notes available. Notes from a subset of 200 randomly selected patients, reviewed by subject-matter experts to identify access to testing, were split into development and testing sets, and various hyperparameters and prompting approaches were applied. We evaluated LLM performance using accuracy, precision, recall, and F1, with expert consensus on the labeled subset serving as ground truth. We compared LLM-identified access distribution in the entire cohort with expert-identified access in the labeled subset using the chi-squared test.</p><p><strong>Results: </strong>Llama 3 70B achieved an F1 score of 0.912 (95% CI, 0.853 to 0.971), besting Llama 3 8B (F1: 0.811; 95% CI, 0.720 to 0.901) and significantly outperforming Llama 2 70B (F1: 0.644; 95% CI, 0.514 to 0.773; the test set target variable prevalence was 0.72.) We observed no significant difference between the performance of Llama 3 70B and that of the average individual expert reviewer, nor between LLM-identified access distribution across the entire cohort and expert-identified distribution in the labeled subset.</p><p><strong>Conclusion: </strong>An open-source, locally deployable LLM effectively and efficiently identified germline genetic testing access from clinical notes. LLMs may enhance care quality and efficiency, while safeguarding sensitive data.</p>","PeriodicalId":51626,"journal":{"name":"JCO Clinical Cancer Informatics","volume":"9 ","pages":"e2400263"},"PeriodicalIF":2.8000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12303249/pdf/","citationCount":"0","resultStr":"{\"title\":\"Using Open-Source Large Language Models to Identify Access to Germline Genetic Testing in Veterans With Breast Cancer From Unstructured Text.\",\"authors\":\"Chunyang Li, Michael Stringer, Vikas Patil, Richard Mcshinsky, Deborah Morreall, Christina Yong, Kelli M Rasmussen, Zachary Burningham, Suzanne Tamang, Carolyn S Menendez, Akiko Chiba, Haley A Moss, Sarah Colonna, Kerry Rowe, Daphne Friedman, Michael J Kelley, Ahmad Halwani\",\"doi\":\"10.1200/CCI-24-00263\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>The ability of large language models (LLMs) to identify access to germline genetic testing from unstructured text remains unknown. The Department of Veterans Affairs (VA) assessed access in Veterans with breast cancer by implementing and evaluating the performance of open-source, locally deployable LLMs (Llama 3 70B, Llama 3 8B, and Llama 2 70B) in identifying access from clinical/consult notes.</p><p><strong>Methods: </strong>We identified a cohort of 1,201 Veterans diagnosed with breast cancer between January 1, 2021, and December 31, 2022, who received cancer care within the nationwide VA system and had clinical and/or consult notes available. Notes from a subset of 200 randomly selected patients, reviewed by subject-matter experts to identify access to testing, were split into development and testing sets, and various hyperparameters and prompting approaches were applied. We evaluated LLM performance using accuracy, precision, recall, and F1, with expert consensus on the labeled subset serving as ground truth. We compared LLM-identified access distribution in the entire cohort with expert-identified access in the labeled subset using the chi-squared test.</p><p><strong>Results: </strong>Llama 3 70B achieved an F1 score of 0.912 (95% CI, 0.853 to 0.971), besting Llama 3 8B (F1: 0.811; 95% CI, 0.720 to 0.901) and significantly outperforming Llama 2 70B (F1: 0.644; 95% CI, 0.514 to 0.773; the test set target variable prevalence was 0.72.) We observed no significant difference between the performance of Llama 3 70B and that of the average individual expert reviewer, nor between LLM-identified access distribution across the entire cohort and expert-identified distribution in the labeled subset.</p><p><strong>Conclusion: </strong>An open-source, locally deployable LLM effectively and efficiently identified germline genetic testing access from clinical notes. LLMs may enhance care quality and efficiency, while safeguarding sensitive data.</p>\",\"PeriodicalId\":51626,\"journal\":{\"name\":\"JCO Clinical Cancer Informatics\",\"volume\":\"9 \",\"pages\":\"e2400263\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12303249/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JCO Clinical Cancer Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1200/CCI-24-00263\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/7/22 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ONCOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JCO Clinical Cancer Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1200/CCI-24-00263","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/22 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
Using Open-Source Large Language Models to Identify Access to Germline Genetic Testing in Veterans With Breast Cancer From Unstructured Text.
Purpose: The ability of large language models (LLMs) to identify access to germline genetic testing from unstructured text remains unknown. The Department of Veterans Affairs (VA) assessed access in Veterans with breast cancer by implementing and evaluating the performance of open-source, locally deployable LLMs (Llama 3 70B, Llama 3 8B, and Llama 2 70B) in identifying access from clinical/consult notes.
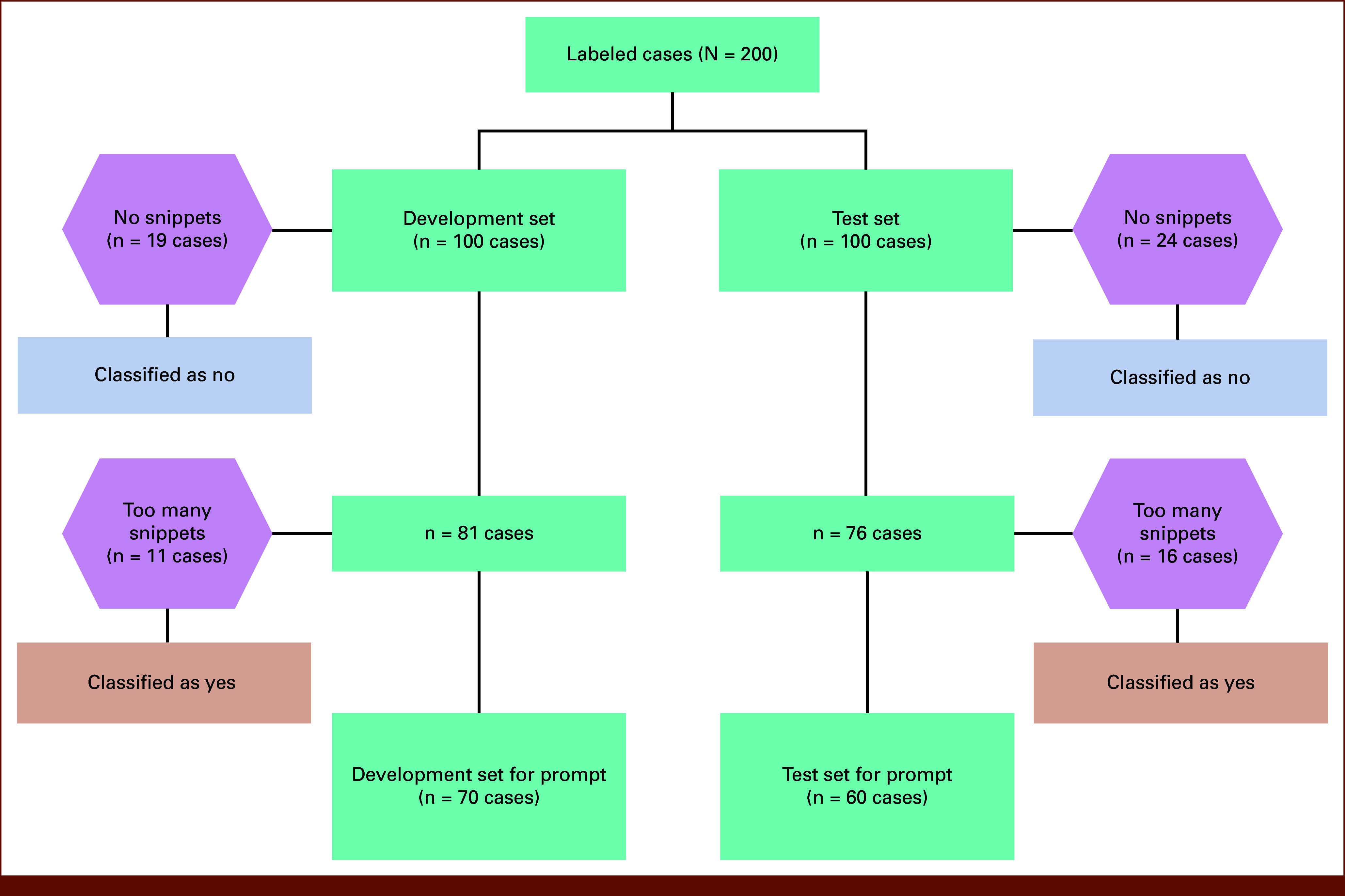
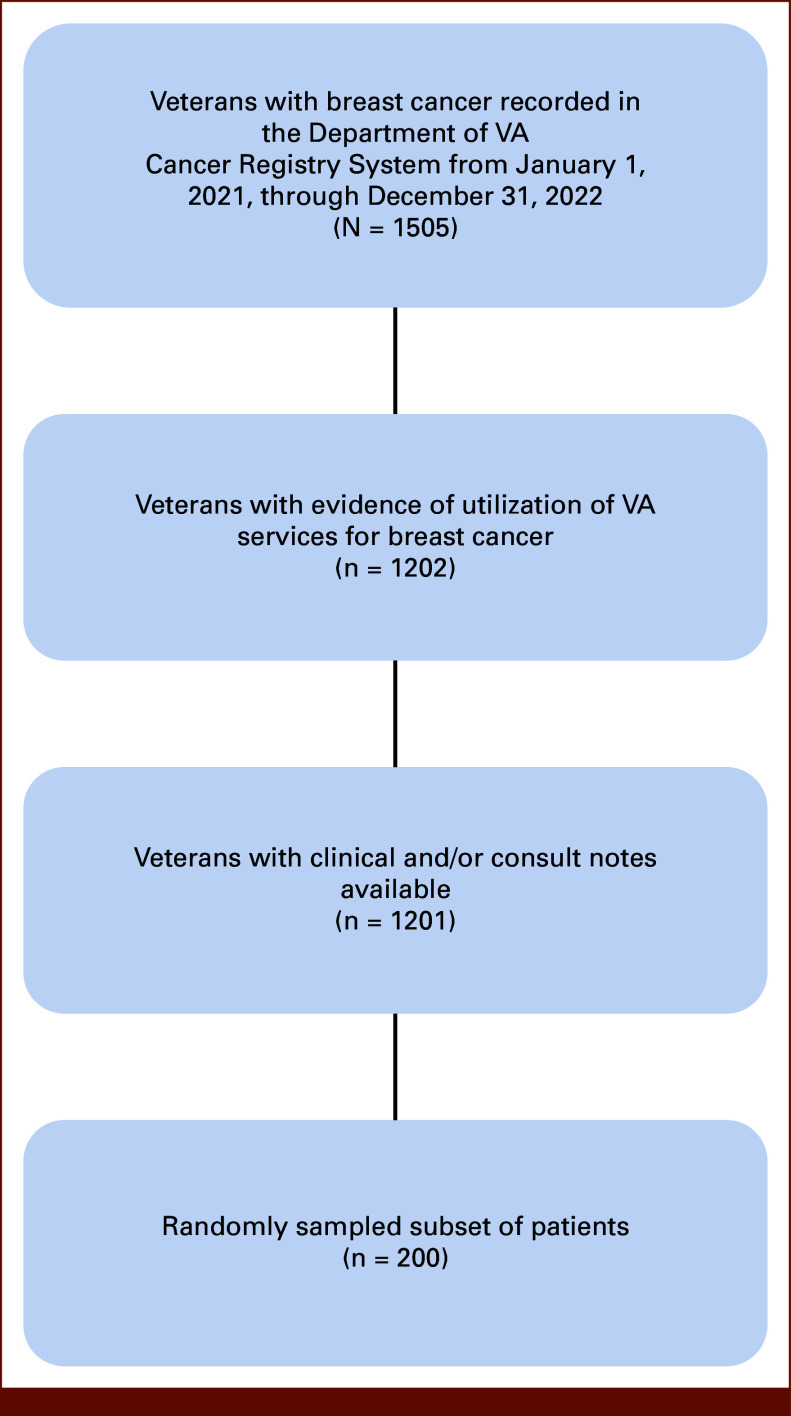
Methods: We identified a cohort of 1,201 Veterans diagnosed with breast cancer between January 1, 2021, and December 31, 2022, who received cancer care within the nationwide VA system and had clinical and/or consult notes available. Notes from a subset of 200 randomly selected patients, reviewed by subject-matter experts to identify access to testing, were split into development and testing sets, and various hyperparameters and prompting approaches were applied. We evaluated LLM performance using accuracy, precision, recall, and F1, with expert consensus on the labeled subset serving as ground truth. We compared LLM-identified access distribution in the entire cohort with expert-identified access in the labeled subset using the chi-squared test.
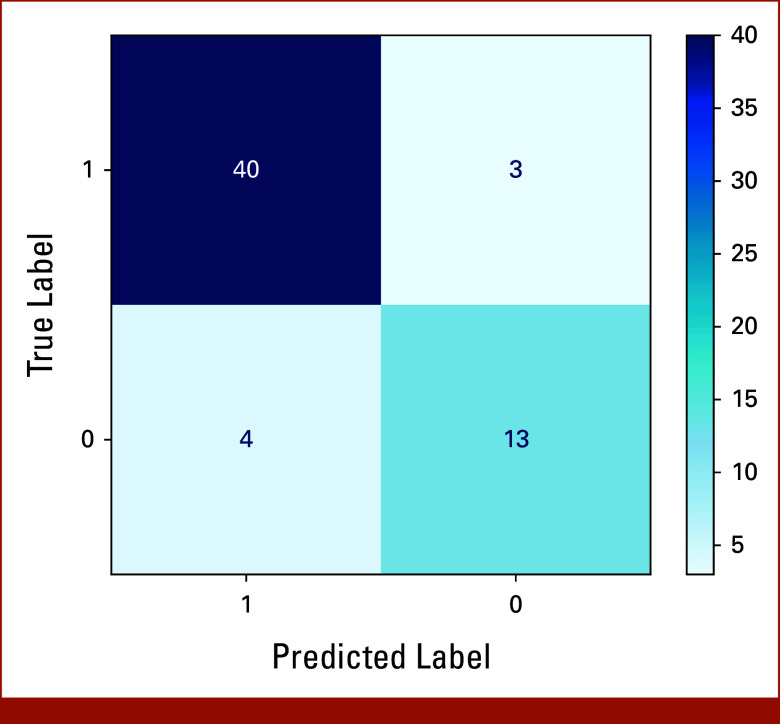
Results: Llama 3 70B achieved an F1 score of 0.912 (95% CI, 0.853 to 0.971), besting Llama 3 8B (F1: 0.811; 95% CI, 0.720 to 0.901) and significantly outperforming Llama 2 70B (F1: 0.644; 95% CI, 0.514 to 0.773; the test set target variable prevalence was 0.72.) We observed no significant difference between the performance of Llama 3 70B and that of the average individual expert reviewer, nor between LLM-identified access distribution across the entire cohort and expert-identified distribution in the labeled subset.
Conclusion: An open-source, locally deployable LLM effectively and efficiently identified germline genetic testing access from clinical notes. LLMs may enhance care quality and efficiency, while safeguarding sensitive data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


