Keith Mitchell, Samuel Hunter, Lutz Froenicke, Karl Murray, Matthew Settles, James S Trimmer
{"title":"clonevdjseq:用于克隆文库中VDJ序列测序、存档和分析的工作流和生物信息学管理系统。","authors":"Keith Mitchell, Samuel Hunter, Lutz Froenicke, Karl Murray, Matthew Settles, James S Trimmer","doi":"10.1186/s12859-025-06107-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Advances in next-generation sequencing technologies have facilitated extensive analysis of B cell and T cell receptor (BCR/TCR, respectively) sequences from monoclonal hybridoma libraries, single B cells, and single T cells, generating vast amounts of important data pertaining to antigen recognition. However, existing workflows and bioinformatics tools often lack the flexibility and scalability needed to handle large clonal level datasets effectively. An initial system and hybridoma dependent version of this code was distributed as part of the NeuroMabSeq publication, but clonevdjseq aims to be a technical addendum for broader system compatibility and enhanced modeling.</p><p><strong>Results: </strong>We present clonevdjseq, an integrated and accessible software solution leveraging nextflow and Django. Developed primarily for large hybridoma libraries, the workflow and pipeline is amenable to BCR/TCR sequence analysis of homogenous populations or clones of B and T cells, respectively. The clonevdjseq pipeline includes modules for read processing, amplicon denoising, and quality control of paired variable light/heavy chains of BCRs from B cells and hybridomas, or alpha(ɑ)/beta(β) and delta(δ)/gamma(γ) chains of TCRs in the case of T cell applications. The pipeline is built upon a robust, high-throughput library prep protocol, upon which processed data has been verified across thousands of monoclonal antibodies. The results of this effort has yielded sequences used to develop functional recombinant monoclonal antibodies and single chain variable fragments as a part of the NeuroMabSeq initiative where thousands of hybridoma samples were processed (Mitchell et al. in Sci Rep 13(1):16200, 2023) as well as provide additional modeling and extensibility to other modalities. The clonevdjseq software is accessible via Nextflow and also offers a database and web app as a final optional step in the processing for dissemination of results and data exploration.</p><p><strong>Conclusions: </strong>clonevdjseq offers a comprehensive and scalable solution for the processing and analysis of large monoclonal and oligoclonal VDJ datasets. Its modular design, dynamic pipeline, and robust database integration facilitate efficient data management and analysis. The platform is publicly available and aims to support the research community by providing an accessible and flexible tool for archiving and dissemination of BCR sequences from hybridomas, with applicability for other applications such as TCR sequences from single-cell T cell populations.</p>","PeriodicalId":8958,"journal":{"name":"BMC Bioinformatics","volume":"26 1","pages":"186"},"PeriodicalIF":3.3000,"publicationDate":"2025-07-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12278597/pdf/","citationCount":"0","resultStr":"{\"title\":\"clonevdjseq: A workflow and bioinformatics management system for sequencing, archiving, and analysis of VDJ sequences from clonal libraries.\",\"authors\":\"Keith Mitchell, Samuel Hunter, Lutz Froenicke, Karl Murray, Matthew Settles, James S Trimmer\",\"doi\":\"10.1186/s12859-025-06107-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Advances in next-generation sequencing technologies have facilitated extensive analysis of B cell and T cell receptor (BCR/TCR, respectively) sequences from monoclonal hybridoma libraries, single B cells, and single T cells, generating vast amounts of important data pertaining to antigen recognition. However, existing workflows and bioinformatics tools often lack the flexibility and scalability needed to handle large clonal level datasets effectively. An initial system and hybridoma dependent version of this code was distributed as part of the NeuroMabSeq publication, but clonevdjseq aims to be a technical addendum for broader system compatibility and enhanced modeling.</p><p><strong>Results: </strong>We present clonevdjseq, an integrated and accessible software solution leveraging nextflow and Django. Developed primarily for large hybridoma libraries, the workflow and pipeline is amenable to BCR/TCR sequence analysis of homogenous populations or clones of B and T cells, respectively. The clonevdjseq pipeline includes modules for read processing, amplicon denoising, and quality control of paired variable light/heavy chains of BCRs from B cells and hybridomas, or alpha(ɑ)/beta(β) and delta(δ)/gamma(γ) chains of TCRs in the case of T cell applications. The pipeline is built upon a robust, high-throughput library prep protocol, upon which processed data has been verified across thousands of monoclonal antibodies. The results of this effort has yielded sequences used to develop functional recombinant monoclonal antibodies and single chain variable fragments as a part of the NeuroMabSeq initiative where thousands of hybridoma samples were processed (Mitchell et al. in Sci Rep 13(1):16200, 2023) as well as provide additional modeling and extensibility to other modalities. The clonevdjseq software is accessible via Nextflow and also offers a database and web app as a final optional step in the processing for dissemination of results and data exploration.</p><p><strong>Conclusions: </strong>clonevdjseq offers a comprehensive and scalable solution for the processing and analysis of large monoclonal and oligoclonal VDJ datasets. Its modular design, dynamic pipeline, and robust database integration facilitate efficient data management and analysis. The platform is publicly available and aims to support the research community by providing an accessible and flexible tool for archiving and dissemination of BCR sequences from hybridomas, with applicability for other applications such as TCR sequences from single-cell T cell populations.</p>\",\"PeriodicalId\":8958,\"journal\":{\"name\":\"BMC Bioinformatics\",\"volume\":\"26 1\",\"pages\":\"186\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2025-07-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12278597/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s12859-025-06107-2\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s12859-025-06107-2","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
clonevdjseq: A workflow and bioinformatics management system for sequencing, archiving, and analysis of VDJ sequences from clonal libraries.
Background: Advances in next-generation sequencing technologies have facilitated extensive analysis of B cell and T cell receptor (BCR/TCR, respectively) sequences from monoclonal hybridoma libraries, single B cells, and single T cells, generating vast amounts of important data pertaining to antigen recognition. However, existing workflows and bioinformatics tools often lack the flexibility and scalability needed to handle large clonal level datasets effectively. An initial system and hybridoma dependent version of this code was distributed as part of the NeuroMabSeq publication, but clonevdjseq aims to be a technical addendum for broader system compatibility and enhanced modeling.
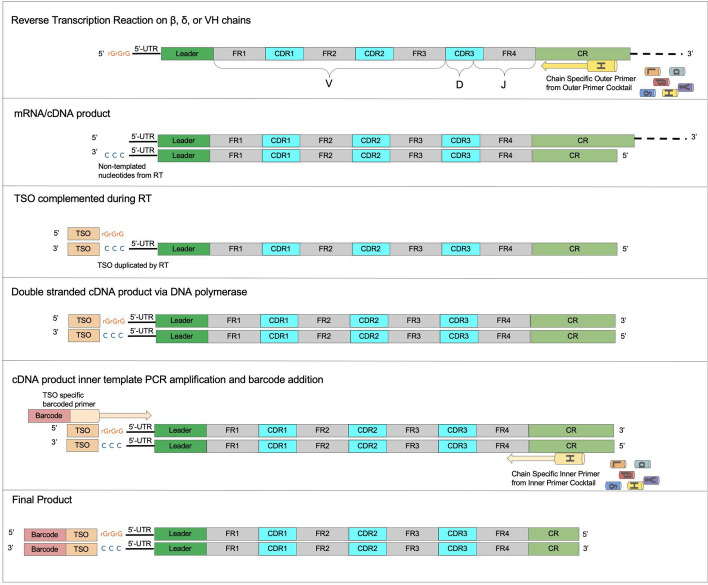
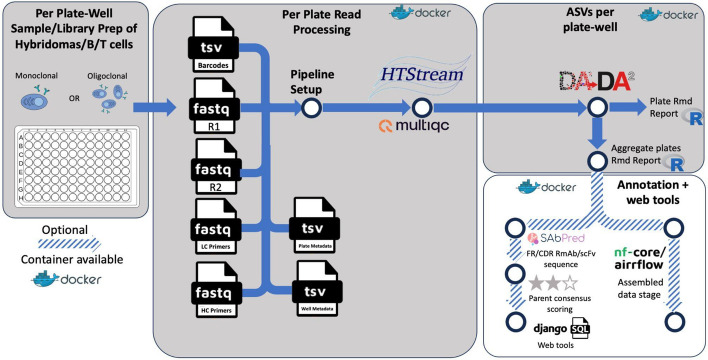
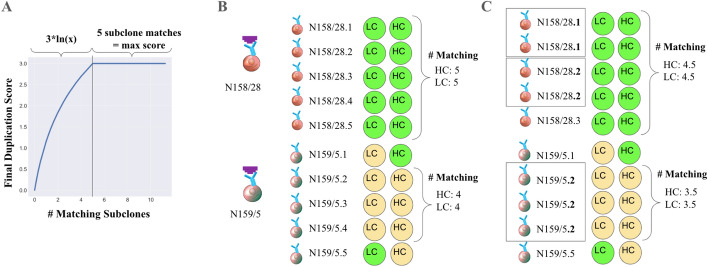
Results: We present clonevdjseq, an integrated and accessible software solution leveraging nextflow and Django. Developed primarily for large hybridoma libraries, the workflow and pipeline is amenable to BCR/TCR sequence analysis of homogenous populations or clones of B and T cells, respectively. The clonevdjseq pipeline includes modules for read processing, amplicon denoising, and quality control of paired variable light/heavy chains of BCRs from B cells and hybridomas, or alpha(ɑ)/beta(β) and delta(δ)/gamma(γ) chains of TCRs in the case of T cell applications. The pipeline is built upon a robust, high-throughput library prep protocol, upon which processed data has been verified across thousands of monoclonal antibodies. The results of this effort has yielded sequences used to develop functional recombinant monoclonal antibodies and single chain variable fragments as a part of the NeuroMabSeq initiative where thousands of hybridoma samples were processed (Mitchell et al. in Sci Rep 13(1):16200, 2023) as well as provide additional modeling and extensibility to other modalities. The clonevdjseq software is accessible via Nextflow and also offers a database and web app as a final optional step in the processing for dissemination of results and data exploration.
Conclusions: clonevdjseq offers a comprehensive and scalable solution for the processing and analysis of large monoclonal and oligoclonal VDJ datasets. Its modular design, dynamic pipeline, and robust database integration facilitate efficient data management and analysis. The platform is publicly available and aims to support the research community by providing an accessible and flexible tool for archiving and dissemination of BCR sequences from hybridomas, with applicability for other applications such as TCR sequences from single-cell T cell populations.
期刊介绍:
BMC Bioinformatics is an open access, peer-reviewed journal that considers articles on all aspects of the development, testing and novel application of computational and statistical methods for the modeling and analysis of all kinds of biological data, as well as other areas of computational biology.
BMC Bioinformatics is part of the BMC series which publishes subject-specific journals focused on the needs of individual research communities across all areas of biology and medicine. We offer an efficient, fair and friendly peer review service, and are committed to publishing all sound science, provided that there is some advance in knowledge presented by the work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


