规模还是多样性?住宅建筑早期设计阶段机器学习供热预测模型的综合数据集推荐
IF 9.6
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
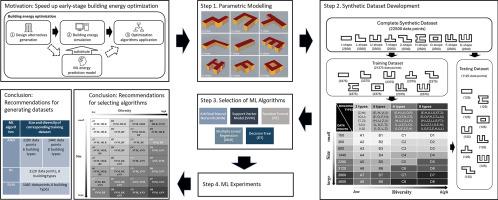
一种很有希望的减少建筑能耗的方法是使用模拟进行早期的建筑能耗优化,然而今天的模拟引擎是计算密集型的。最近,机器学习(ML)能量预测模型有望取代这些模拟引擎。然而,由于缺乏适当的数据集,通常很难开发这样的ML模型。合成数据集可以提供一个解决方案,但确定合成数据的最佳数量和多样性仍然是一项具有挑战性的任务。此外,对不同ML算法之间的兼容性和合成数据集的特征缺乏理解。为了填补这些空白,本研究使用瑞典的住宅建筑进行了多次ML实验,以确定性能最佳的ML算法,以及相应合成数据集的特征。开发了一个参数化模型来生成各种大小和建筑形状不同的合成数据集,称为多样性。通过文献综述选择的五种机器学习算法使用不同的数据集进行训练。结果表明,支持向量机总体上表现最好。多元线性回归在小型和低多样性数据集上表现良好,而人工神经网络在大型和高多样性数据集上表现良好。我们得出的结论是,当生成合成训练数据集时,一旦数据集大小达到1440左右,开发人员应该更多地关注增加多样性而不是大小。本研究为研究人员和从业人员(如软件工具开发人员)在早期优化中开发ML建筑能源预测模型提供了见解。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Size or diversity? Synthetic dataset recommendations for machine learning heating energy prediction models in early design stages for residential buildings
One promising means to reduce building energy for a more sustainable environment is to conduct early-stage building energy optimization using simulation, yet today’s simulation engines are computationally intensive. Recently, machine learning (ML) energy prediction models have shown promise in replacing these simulation engines. However, it is often difficult to develop such ML models due to the lack of proper datasets. Synthetic datasets can provide a solution, but determining the optimal quantity and diversity of synthetic data remains a challenging task. Furthermore, there is a lack of understanding of the compatibility between different ML algorithms and the characteristics of synthetic datasets. To fill these gaps, this study conducted multiple ML experiments using residential buildings in Sweden to determine the best-performing ML algorithm, as well as the characteristics of the corresponding synthetic dataset. A parametric model was developed to generate a wide range of synthetic datasets varying in size and building shape, referred to as diversity. Five ML algorithms selected through a literature review were trained using the different datasets. Results show that the Support Vector Machine performed the best overall. Multiple Linear Regression performed well with small and low-diverse datasets, while the Artificial Neural Network performed well with large and high-diverse datasets. We conclude that developers should focus more on increasing diversity instead of size once the dataset size reaches around 1440 when generating synthetic training datasets. This study offers insights for researchers and practitioners, such as software tool developers, when developing ML building energy prediction models in early-stage optimization.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Energy and AI
Engineering-Engineering (miscellaneous)
CiteScore
16.50
自引率
0.00%
发文量
64
审稿时长
56 days
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


