Panagiotis G. Karamertzanis*, Mike Rasenberg, Imran Shah and Grace Patlewicz,
{"title":"基于多任务深度学习和REACH数据的体外诱变性建模。","authors":"Panagiotis G. Karamertzanis*, Mike Rasenberg, Imran Shah and Grace Patlewicz, ","doi":"10.1021/acs.chemrestox.5c00152","DOIUrl":null,"url":null,"abstract":"<p >Under REACH, mutagenicity assessment relies on <i>in vitro</i> testing (gene mutation test in bacteria and/or mammalian cells, as well as chromosomal aberration or micronucleus assays in mammalian cells) followed by <i>in vivo</i> testing if necessary. This study explored the possibility of using the inherent correlation between these <i>in vitro</i> assays to create multi-task deep learning models and examine if they outperform single-task models. An extensive genotoxicity dataset with over 12,000 substances was compiled, including algorithmically curated REACH data and information from several public sources. Genotoxicity information was also retrieved from ToxValDB and literature sources to construct external (hold-out) test sets for a stringent assessment of the models’ generalized performance. A range of single-task and multi-task models were investigated from classical machine learning techniques and chemical fingerprints to deep learning methods using graphs for molecular structure representation. The best deep learning single-task model achieved a cross-validation balanced accuracy of 73–84% for the four <i>in vitro</i> assays and exceeded classical machine learning by 2–8%. Gene mutation detection for specific bacterial strains and metabolic activation modes exhibited balanced accuracy 82–85%, with improvements ranging from 7% to 12%. Multi-task deep learning models for specific bacterial strains and metabolic activation modes had on average 8% higher cross-validation test balanced accuracy than single-task models but were comparable when assay outcomes were aggregated. The best deep learning models for specific bacterial strains and metabolic activation modes showed external balanced accuracy of 72–78 % when there were at least 200 positives and 200 negatives. The dimensionality-reduced molecular embeddings from graph neural network models were able to distinguish positives from negatives and cluster structures that trigger known genotoxicity structural alerts. The models were also used to identify structural moieties linked to predicted negative genotoxicity in bacteria and positive genotoxicity in mammalian cells.</p>","PeriodicalId":31,"journal":{"name":"Chemical Research in Toxicology","volume":"38 8","pages":"1382–1407"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Modelling In vitro Mutagenicity Using Multi-Task Deep Learning and REACH Data\",\"authors\":\"Panagiotis G. Karamertzanis*, Mike Rasenberg, Imran Shah and Grace Patlewicz, \",\"doi\":\"10.1021/acs.chemrestox.5c00152\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Under REACH, mutagenicity assessment relies on <i>in vitro</i> testing (gene mutation test in bacteria and/or mammalian cells, as well as chromosomal aberration or micronucleus assays in mammalian cells) followed by <i>in vivo</i> testing if necessary. This study explored the possibility of using the inherent correlation between these <i>in vitro</i> assays to create multi-task deep learning models and examine if they outperform single-task models. An extensive genotoxicity dataset with over 12,000 substances was compiled, including algorithmically curated REACH data and information from several public sources. Genotoxicity information was also retrieved from ToxValDB and literature sources to construct external (hold-out) test sets for a stringent assessment of the models’ generalized performance. A range of single-task and multi-task models were investigated from classical machine learning techniques and chemical fingerprints to deep learning methods using graphs for molecular structure representation. The best deep learning single-task model achieved a cross-validation balanced accuracy of 73–84% for the four <i>in vitro</i> assays and exceeded classical machine learning by 2–8%. Gene mutation detection for specific bacterial strains and metabolic activation modes exhibited balanced accuracy 82–85%, with improvements ranging from 7% to 12%. Multi-task deep learning models for specific bacterial strains and metabolic activation modes had on average 8% higher cross-validation test balanced accuracy than single-task models but were comparable when assay outcomes were aggregated. The best deep learning models for specific bacterial strains and metabolic activation modes showed external balanced accuracy of 72–78 % when there were at least 200 positives and 200 negatives. The dimensionality-reduced molecular embeddings from graph neural network models were able to distinguish positives from negatives and cluster structures that trigger known genotoxicity structural alerts. The models were also used to identify structural moieties linked to predicted negative genotoxicity in bacteria and positive genotoxicity in mammalian cells.</p>\",\"PeriodicalId\":31,\"journal\":{\"name\":\"Chemical Research in Toxicology\",\"volume\":\"38 8\",\"pages\":\"1382–1407\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-07-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Chemical Research in Toxicology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acs.chemrestox.5c00152\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Chemical Research in Toxicology","FirstCategoryId":"3","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.chemrestox.5c00152","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
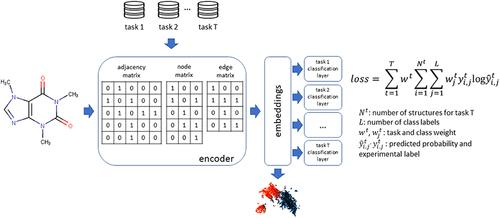
Modelling In vitro Mutagenicity Using Multi-Task Deep Learning and REACH Data
Under REACH, mutagenicity assessment relies on in vitro testing (gene mutation test in bacteria and/or mammalian cells, as well as chromosomal aberration or micronucleus assays in mammalian cells) followed by in vivo testing if necessary. This study explored the possibility of using the inherent correlation between these in vitro assays to create multi-task deep learning models and examine if they outperform single-task models. An extensive genotoxicity dataset with over 12,000 substances was compiled, including algorithmically curated REACH data and information from several public sources. Genotoxicity information was also retrieved from ToxValDB and literature sources to construct external (hold-out) test sets for a stringent assessment of the models’ generalized performance. A range of single-task and multi-task models were investigated from classical machine learning techniques and chemical fingerprints to deep learning methods using graphs for molecular structure representation. The best deep learning single-task model achieved a cross-validation balanced accuracy of 73–84% for the four in vitro assays and exceeded classical machine learning by 2–8%. Gene mutation detection for specific bacterial strains and metabolic activation modes exhibited balanced accuracy 82–85%, with improvements ranging from 7% to 12%. Multi-task deep learning models for specific bacterial strains and metabolic activation modes had on average 8% higher cross-validation test balanced accuracy than single-task models but were comparable when assay outcomes were aggregated. The best deep learning models for specific bacterial strains and metabolic activation modes showed external balanced accuracy of 72–78 % when there were at least 200 positives and 200 negatives. The dimensionality-reduced molecular embeddings from graph neural network models were able to distinguish positives from negatives and cluster structures that trigger known genotoxicity structural alerts. The models were also used to identify structural moieties linked to predicted negative genotoxicity in bacteria and positive genotoxicity in mammalian cells.
期刊介绍:
Chemical Research in Toxicology publishes Articles, Rapid Reports, Chemical Profiles, Reviews, Perspectives, Letters to the Editor, and ToxWatch on a wide range of topics in Toxicology that inform a chemical and molecular understanding and capacity to predict biological outcomes on the basis of structures and processes. The overarching goal of activities reported in the Journal are to provide knowledge and innovative approaches needed to promote intelligent solutions for human safety and ecosystem preservation. The journal emphasizes insight concerning mechanisms of toxicity over phenomenological observations. It upholds rigorous chemical, physical and mathematical standards for characterization and application of modern techniques.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


