Yuliya Burankova, Miriam Abele, Mohammad Bakhtiari, Christine von Toerne, Teresa K. Barth, Lisa Schweizer, Pieter Giesbertz, Johannes R. Schmidt, Stefan Kalkhof, Janina Müller-Deile, Peter A. van Veelen, Yassene Mohammed, Elke Hammer, Lis Arend, Klaudia Adamowicz, Tanja Laske, Anne Hartebrodt, Tobias Frisch, Chen Meng, Julian Matschinske, Julian Späth, Richard Röttger, Veit Schwämmle, Stefanie M. Hauck, Stefan F. Lichtenthaler, Axel Imhof, Matthias Mann, Christina Ludwig, Bernhard Kuster, Jan Baumbach, Olga Zolotareva
{"title":"保护隐私的多中心差异蛋白丰度分析。","authors":"Yuliya Burankova, Miriam Abele, Mohammad Bakhtiari, Christine von Toerne, Teresa K. Barth, Lisa Schweizer, Pieter Giesbertz, Johannes R. Schmidt, Stefan Kalkhof, Janina Müller-Deile, Peter A. van Veelen, Yassene Mohammed, Elke Hammer, Lis Arend, Klaudia Adamowicz, Tanja Laske, Anne Hartebrodt, Tobias Frisch, Chen Meng, Julian Matschinske, Julian Späth, Richard Röttger, Veit Schwämmle, Stefanie M. Hauck, Stefan F. Lichtenthaler, Axel Imhof, Matthias Mann, Christina Ludwig, Bernhard Kuster, Jan Baumbach, Olga Zolotareva","doi":"10.1038/s43588-025-00832-7","DOIUrl":null,"url":null,"abstract":"Quantitative mass spectrometry has revolutionized proteomics by enabling simultaneous quantification of thousands of proteins. Pooling patient-derived data from multiple institutions enhances statistical power but raises serious privacy concerns. Here we introduce FedProt, the first privacy-preserving tool for collaborative differential protein abundance analysis of distributed data, which utilizes federated learning and additive secret sharing. In the absence of a multicenter patient-derived dataset for evaluation, we created two: one at five centers from E. coli experiments and one at three centers from human serum. Evaluations using these datasets confirm that FedProt achieves accuracy equivalent to the DEqMS method applied to pooled data, with completely negligible absolute differences no greater than 4 × 10−12. By contrast, −log10P computed by the most accurate meta-analysis methods diverged from the centralized analysis results by up to 25–26. In this Resource, the authors present FedProt, a tool that enables privacy-preserving, federated differential protein abundance analysis across multiple institutions. Its results match the results of centralized analysis, enabling secure, collaborative proteomics without sensitive data sharing.","PeriodicalId":74246,"journal":{"name":"Nature computational science","volume":"5 8","pages":"675-688"},"PeriodicalIF":18.3000,"publicationDate":"2025-07-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12374843/pdf/","citationCount":"0","resultStr":"{\"title\":\"Privacy-preserving multicenter differential protein abundance analysis with FedProt\",\"authors\":\"Yuliya Burankova, Miriam Abele, Mohammad Bakhtiari, Christine von Toerne, Teresa K. Barth, Lisa Schweizer, Pieter Giesbertz, Johannes R. Schmidt, Stefan Kalkhof, Janina Müller-Deile, Peter A. van Veelen, Yassene Mohammed, Elke Hammer, Lis Arend, Klaudia Adamowicz, Tanja Laske, Anne Hartebrodt, Tobias Frisch, Chen Meng, Julian Matschinske, Julian Späth, Richard Röttger, Veit Schwämmle, Stefanie M. Hauck, Stefan F. Lichtenthaler, Axel Imhof, Matthias Mann, Christina Ludwig, Bernhard Kuster, Jan Baumbach, Olga Zolotareva\",\"doi\":\"10.1038/s43588-025-00832-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Quantitative mass spectrometry has revolutionized proteomics by enabling simultaneous quantification of thousands of proteins. Pooling patient-derived data from multiple institutions enhances statistical power but raises serious privacy concerns. Here we introduce FedProt, the first privacy-preserving tool for collaborative differential protein abundance analysis of distributed data, which utilizes federated learning and additive secret sharing. In the absence of a multicenter patient-derived dataset for evaluation, we created two: one at five centers from E. coli experiments and one at three centers from human serum. Evaluations using these datasets confirm that FedProt achieves accuracy equivalent to the DEqMS method applied to pooled data, with completely negligible absolute differences no greater than 4 × 10−12. By contrast, −log10P computed by the most accurate meta-analysis methods diverged from the centralized analysis results by up to 25–26. In this Resource, the authors present FedProt, a tool that enables privacy-preserving, federated differential protein abundance analysis across multiple institutions. Its results match the results of centralized analysis, enabling secure, collaborative proteomics without sensitive data sharing.\",\"PeriodicalId\":74246,\"journal\":{\"name\":\"Nature computational science\",\"volume\":\"5 8\",\"pages\":\"675-688\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2025-07-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12374843/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature computational science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.nature.com/articles/s43588-025-00832-7\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature computational science","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s43588-025-00832-7","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Privacy-preserving multicenter differential protein abundance analysis with FedProt
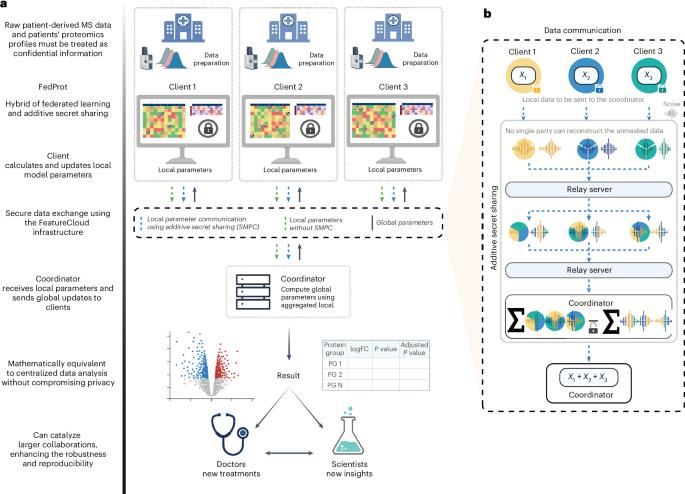
Quantitative mass spectrometry has revolutionized proteomics by enabling simultaneous quantification of thousands of proteins. Pooling patient-derived data from multiple institutions enhances statistical power but raises serious privacy concerns. Here we introduce FedProt, the first privacy-preserving tool for collaborative differential protein abundance analysis of distributed data, which utilizes federated learning and additive secret sharing. In the absence of a multicenter patient-derived dataset for evaluation, we created two: one at five centers from E. coli experiments and one at three centers from human serum. Evaluations using these datasets confirm that FedProt achieves accuracy equivalent to the DEqMS method applied to pooled data, with completely negligible absolute differences no greater than 4 × 10−12. By contrast, −log10P computed by the most accurate meta-analysis methods diverged from the centralized analysis results by up to 25–26. In this Resource, the authors present FedProt, a tool that enables privacy-preserving, federated differential protein abundance analysis across multiple institutions. Its results match the results of centralized analysis, enabling secure, collaborative proteomics without sensitive data sharing.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


