预测异常引导的多模态语言语义阿拉伯图像字幕
IF 4.9
引用次数: 0
摘要
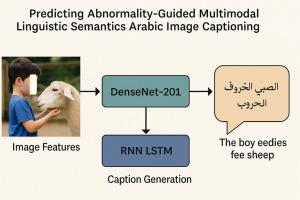
深度学习具有显著的高级图像字幕任务,使模型能够从视觉内容生成准确的描述性句子。虽然在英语图像字幕方面取得了很大进展,但阿拉伯语仍然未被充分开发,尽管它的语言复杂性和广泛使用。现有的阿拉伯语图像字幕系统存在数据集有限、模型调整不足以及对阿拉伯语形态学和语义适应能力差的问题。这一限制阻碍了准确、连贯的阿拉伯语字幕的发展,特别是在媒体索引和内容可及性等资源丰富的应用中。本研究旨在开发一个有效的阿拉伯语图像标题生成器,以解决该领域研究和工具的短缺。目标是创建一个健壮的模型,能够为视觉输入生成语义丰富、语法准确的阿拉伯语字幕。该系统集成了用于图像特征提取的DenseNet201卷积神经网络(CNN)和用于顺序标题生成的使用长短期记忆(RNN-LSTM)单元的深度递归神经网络。该模型是在Flickr8K数据集的阿拉伯语翻译版本上进行训练和微调的,该数据集由8000多张图像组成,每张图像都配有三个阿拉伯语字幕。优化后的DenseNet201 + LSTM模型在阿拉伯语图像字幕任务中的BLEU-4得分为0.85,ROUGE-L得分为0.90,METEOR得分为0.72,CIDEr得分为0.88,SPICE得分为0.68,perplexity得分为1.1,超过了基线和之前的模型。本研究提供了一种新颖的端到端阿拉伯语图像字幕框架,通过深度学习解决语言挑战。它为未来阿拉伯语图像理解的研究和实际应用提供了一个基准模型。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Predicting abnormality-guided multimodal linguistic semantics Arabic image captioning
Deep learning has significantly advanced image captioning tasks, enabling models to generate accurate, descriptive sentences from visual content. While much progress has been made in English-language image captioning, Arabic remains underexplored despite its linguistic complexity and widespread usage. Existing Arabic image captioning systems suffer from limited datasets, insufficiently tuned models, and poor adaptation to Arabic morphology and semantics. This limitation hinders the development of accurate, coherent Arabic captions, especially in high-resource applications such as media indexing and content accessibility. This study aims to develop an effective Arabic Image Caption Generator that addresses the shortage of research and tools in this domain. The goal is to create a robust model capable of generating semantically rich, syntactically accurate Arabic captions for visual inputs. The proposed system integrates a DenseNet201 convolutional neural network (CNN) for image feature extraction with a deep Recurrent Neural Network using Long Short-Term Memory (RNN-LSTM) units for sequential caption generation. The model was trained and fine-tuned on a translated Arabic version of the Flickr8K dataset, consisting of over 8000 images, each paired with three Arabic captions. The fine-tuned DenseNet201 + LSTM model achieved BLEU-4 of 0.85, ROUGE-L of 0.90, METEOR of 0.72, CIDEr of 0.88, SPICE of 0.68, and a perplexity score of 1.1, surpassing baseline and prior models in Arabic image captioning tasks. This research provides a novel, end-to-end Arabic image captioning framework, addressing linguistic challenges through deep learning. It offers a benchmark model for future research and practical applications in Arabic-language image understanding.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Machine learning with applications
Management Science and Operations Research, Artificial Intelligence, Computer Science Applications
自引率
0.00%
发文量
0
审稿时长
98 days
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


