Woohyuk Jeon, Minjae Park, Doyeon An, Wonshik Nam, Ju-Young Shin, Seunghee Lee, Suehyun Lee
{"title":"从生物医学BERT模型中嵌入的参数知识预测药物副作用关系:使用自然语言处理方法的方法学研究。","authors":"Woohyuk Jeon, Minjae Park, Doyeon An, Wonshik Nam, Ju-Young Shin, Seunghee Lee, Suehyun Lee","doi":"10.2196/67513","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Adverse drug reactions (ADRs) pose serious risks to patient health, and effectively predicting and managing them is an important public health challenge. Given the complexity and specificity of biomedical text data, the traditional context-independent word embedding model, Word2Vec, has limitations in fully reflecting the domain specificity of such data. Although Bidirectional Encoder Representations from Transformers (BERT)-based models pretrained on biomedical corpora have demonstrated high performance in ADR-related studies, research using these models to predict previously unknown drug-side effect relationships remains insufficient.</p><p><strong>Objective: </strong>This study proposes a method for predicting drug-side effect relationships by leveraging the parametric knowledge embedded in biomedical BERT models. Through this approach, we predict promising candidates for potential drug-side effect relationships with unknown causal mechanisms by leveraging parametric knowledge from biomedical BERT models and embedding vector similarities of known relationships.</p><p><strong>Methods: </strong>We used 158,096 pairs of drug-side effect relationships from the side effect resource (SIDER) database to generate an adjacency matrix and calculate the cosine similarity between word embedding vectors of drugs and side effects. Relation scores were calculated for 8,235,435 drug-side effect pairs using this similarity. To evaluate the prediction accuracy of drug-side effect relationships, the area under the curve (AUC) value was measured using the calculated relation score and 158,096 known drug-side effect relationships from SIDER.</p><p><strong>Results: </strong>The clagator/biobert_v1.1 model achieved an AUC of 0.915 at an optimal threshold of 0.289, outperforming the existing Word2Vec model with an AUC of 0.848. The BERT-based models pretrained on the biomedical corpus outperformed the vanilla BERT model with an AUC of 0.857. External validation with the FDA (Food and Drug Administration) Adverse Event Reporting System data, using Fisher exact test based on 8,235,435 predicted drug-side effect pairs and 901,361 known relationships, confirmed high statistical significance (P<.001) with an odds ratio of 4.822. In addition, a literature review of predicted drug-side effect relationships not confirmed in the SIDER database revealed that these relationships have been reported in recent studies published after 2016.</p><p><strong>Conclusions: </strong>This study introduces a method for extracting drug-side effect relationships embedded in parameters of language models pretrained on biomedical corpora and using this information to predict previously unknown drug-side effect relationships. We found that BERT-based models pretrained with biomedical corpora consider contextual information and achieve better performance in drug-side effect relationship prediction. External validation using the FDA Adverse Event Reporting System dataset and the literature review of certain cases confirmed high statistical significance, demonstrating practical applicability. These results highlight the utility of natural language processing-based approaches for predicting and managing ADR.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e67513"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12287980/pdf/","citationCount":"0","resultStr":"{\"title\":\"Predicting Drug-Side Effect Relationships From Parametric Knowledge Embedded in Biomedical BERT Models: Methodological Study With a Natural Language Processing Approach.\",\"authors\":\"Woohyuk Jeon, Minjae Park, Doyeon An, Wonshik Nam, Ju-Young Shin, Seunghee Lee, Suehyun Lee\",\"doi\":\"10.2196/67513\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Adverse drug reactions (ADRs) pose serious risks to patient health, and effectively predicting and managing them is an important public health challenge. Given the complexity and specificity of biomedical text data, the traditional context-independent word embedding model, Word2Vec, has limitations in fully reflecting the domain specificity of such data. Although Bidirectional Encoder Representations from Transformers (BERT)-based models pretrained on biomedical corpora have demonstrated high performance in ADR-related studies, research using these models to predict previously unknown drug-side effect relationships remains insufficient.</p><p><strong>Objective: </strong>This study proposes a method for predicting drug-side effect relationships by leveraging the parametric knowledge embedded in biomedical BERT models. Through this approach, we predict promising candidates for potential drug-side effect relationships with unknown causal mechanisms by leveraging parametric knowledge from biomedical BERT models and embedding vector similarities of known relationships.</p><p><strong>Methods: </strong>We used 158,096 pairs of drug-side effect relationships from the side effect resource (SIDER) database to generate an adjacency matrix and calculate the cosine similarity between word embedding vectors of drugs and side effects. Relation scores were calculated for 8,235,435 drug-side effect pairs using this similarity. To evaluate the prediction accuracy of drug-side effect relationships, the area under the curve (AUC) value was measured using the calculated relation score and 158,096 known drug-side effect relationships from SIDER.</p><p><strong>Results: </strong>The clagator/biobert_v1.1 model achieved an AUC of 0.915 at an optimal threshold of 0.289, outperforming the existing Word2Vec model with an AUC of 0.848. The BERT-based models pretrained on the biomedical corpus outperformed the vanilla BERT model with an AUC of 0.857. External validation with the FDA (Food and Drug Administration) Adverse Event Reporting System data, using Fisher exact test based on 8,235,435 predicted drug-side effect pairs and 901,361 known relationships, confirmed high statistical significance (P<.001) with an odds ratio of 4.822. In addition, a literature review of predicted drug-side effect relationships not confirmed in the SIDER database revealed that these relationships have been reported in recent studies published after 2016.</p><p><strong>Conclusions: </strong>This study introduces a method for extracting drug-side effect relationships embedded in parameters of language models pretrained on biomedical corpora and using this information to predict previously unknown drug-side effect relationships. We found that BERT-based models pretrained with biomedical corpora consider contextual information and achieve better performance in drug-side effect relationship prediction. External validation using the FDA Adverse Event Reporting System dataset and the literature review of certain cases confirmed high statistical significance, demonstrating practical applicability. These results highlight the utility of natural language processing-based approaches for predicting and managing ADR.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"13 \",\"pages\":\"e67513\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-07-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12287980/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/67513\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/67513","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Predicting Drug-Side Effect Relationships From Parametric Knowledge Embedded in Biomedical BERT Models: Methodological Study With a Natural Language Processing Approach.
Background: Adverse drug reactions (ADRs) pose serious risks to patient health, and effectively predicting and managing them is an important public health challenge. Given the complexity and specificity of biomedical text data, the traditional context-independent word embedding model, Word2Vec, has limitations in fully reflecting the domain specificity of such data. Although Bidirectional Encoder Representations from Transformers (BERT)-based models pretrained on biomedical corpora have demonstrated high performance in ADR-related studies, research using these models to predict previously unknown drug-side effect relationships remains insufficient.
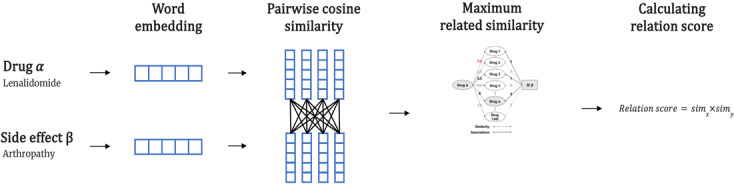
Objective: This study proposes a method for predicting drug-side effect relationships by leveraging the parametric knowledge embedded in biomedical BERT models. Through this approach, we predict promising candidates for potential drug-side effect relationships with unknown causal mechanisms by leveraging parametric knowledge from biomedical BERT models and embedding vector similarities of known relationships.
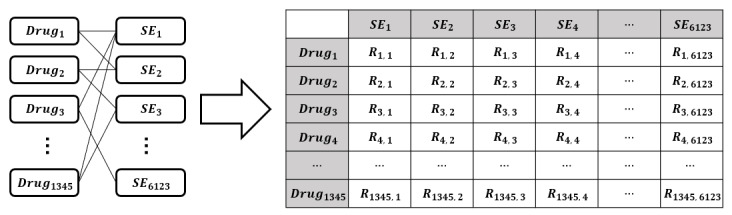
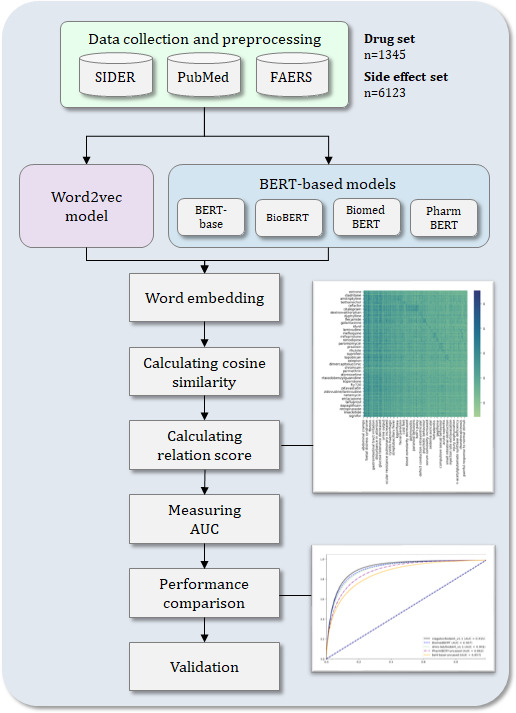
Methods: We used 158,096 pairs of drug-side effect relationships from the side effect resource (SIDER) database to generate an adjacency matrix and calculate the cosine similarity between word embedding vectors of drugs and side effects. Relation scores were calculated for 8,235,435 drug-side effect pairs using this similarity. To evaluate the prediction accuracy of drug-side effect relationships, the area under the curve (AUC) value was measured using the calculated relation score and 158,096 known drug-side effect relationships from SIDER.
Results: The clagator/biobert_v1.1 model achieved an AUC of 0.915 at an optimal threshold of 0.289, outperforming the existing Word2Vec model with an AUC of 0.848. The BERT-based models pretrained on the biomedical corpus outperformed the vanilla BERT model with an AUC of 0.857. External validation with the FDA (Food and Drug Administration) Adverse Event Reporting System data, using Fisher exact test based on 8,235,435 predicted drug-side effect pairs and 901,361 known relationships, confirmed high statistical significance (P<.001) with an odds ratio of 4.822. In addition, a literature review of predicted drug-side effect relationships not confirmed in the SIDER database revealed that these relationships have been reported in recent studies published after 2016.
Conclusions: This study introduces a method for extracting drug-side effect relationships embedded in parameters of language models pretrained on biomedical corpora and using this information to predict previously unknown drug-side effect relationships. We found that BERT-based models pretrained with biomedical corpora consider contextual information and achieve better performance in drug-side effect relationship prediction. External validation using the FDA Adverse Event Reporting System dataset and the literature review of certain cases confirmed high statistical significance, demonstrating practical applicability. These results highlight the utility of natural language processing-based approaches for predicting and managing ADR.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


