Mustafa Khanbhai, Catalina Carenzo, Sarindi Aryasinghe, David Manton, Erik Mayer
{"title":"利用人工智能推动患者体验反馈的及时改进:算法验证。","authors":"Mustafa Khanbhai, Catalina Carenzo, Sarindi Aryasinghe, David Manton, Erik Mayer","doi":"10.2196/60900","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Understanding and improving patient care is pivotal for health care providers. With increasing volumes of the Friends and Family Test (FFT) data in England, manual analysis of this patient feedback poses challenges for many health care organizations. This underscores the importance of automated text analysis, particularly in predicting sentiments and themes in real time.</p><p><strong>Objective: </strong>Leveraging machine learning and natural language processing, this study explores the utility of a supervised algorithm to systematically test and refine the algorithm's cross-contextual performance in diverse health care settings, addressing variations in population characteristics, geographical locations, and care settings, ultimately driving improvements based on patient feedback.</p><p><strong>Methods: </strong>The text analytics algorithm initially developed in a large acute trust in London was further tested in 9 health care organizations with diverse care settings across England. These trusts varied in technical capacity and resource, population demographics, and FFT free text datasets. Testing and validation of the algorithm were performed, including manual coding of a subset of retrospective comments. Technical infrastructure, including coding environments and packages for algorithm testing and deployment, was optimized. The algorithm was iteratively trained using bag of words from anonymized data, tailored to accommodate contextual variations, and tested for change in algorithm performance while simultaneously rectifying issues identified.</p><p><strong>Results: </strong>The algorithm demonstrated satisfactory overall accuracy (>75%) in predicting themes and sentiments embedded within free-text responses across a variety of care settings and population demographics. While the algorithm yielded strong and reusable models in relatively stable environments, such as adult inpatient care settings, the initial accuracy was notably lower in organizations providing services such as pediatrics and mental health. However, the accuracy of our algorithm significantly improved when individual trust coding templates were applied. Thematic saturation was reached after the fifth organization was recruited, and no further coding was required for the last 4 organizations. Subsequently, a framework and pipeline for deployment of the algorithm were developed to provide a standardized approach for implementation and analysis of FFT free text, ensuring ease of use.</p><p><strong>Conclusions: </strong>This study represents a significant step forward in leveraging free-text FFT data for valuable insights in diverse health care settings through the testing and development of a robust supervised learning text analytics algorithm. The disparity in some care settings was anticipated, given that the lexicon and phraseology used was inherently different from those prevalent in adult inpatient care (where the algorithm was developed). However, these challenges were addressed with further coding and testing. This approach enhanced the accuracy and reliability of the algorithm, encouraged inter- and intraorganizational collaboration, and shared learning.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e60900"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12270031/pdf/","citationCount":"0","resultStr":"{\"title\":\"Leveraging AI to Drive Timely Improvements in Patient Experience Feedback: Algorithm Validation.\",\"authors\":\"Mustafa Khanbhai, Catalina Carenzo, Sarindi Aryasinghe, David Manton, Erik Mayer\",\"doi\":\"10.2196/60900\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Understanding and improving patient care is pivotal for health care providers. With increasing volumes of the Friends and Family Test (FFT) data in England, manual analysis of this patient feedback poses challenges for many health care organizations. This underscores the importance of automated text analysis, particularly in predicting sentiments and themes in real time.</p><p><strong>Objective: </strong>Leveraging machine learning and natural language processing, this study explores the utility of a supervised algorithm to systematically test and refine the algorithm's cross-contextual performance in diverse health care settings, addressing variations in population characteristics, geographical locations, and care settings, ultimately driving improvements based on patient feedback.</p><p><strong>Methods: </strong>The text analytics algorithm initially developed in a large acute trust in London was further tested in 9 health care organizations with diverse care settings across England. These trusts varied in technical capacity and resource, population demographics, and FFT free text datasets. Testing and validation of the algorithm were performed, including manual coding of a subset of retrospective comments. Technical infrastructure, including coding environments and packages for algorithm testing and deployment, was optimized. The algorithm was iteratively trained using bag of words from anonymized data, tailored to accommodate contextual variations, and tested for change in algorithm performance while simultaneously rectifying issues identified.</p><p><strong>Results: </strong>The algorithm demonstrated satisfactory overall accuracy (>75%) in predicting themes and sentiments embedded within free-text responses across a variety of care settings and population demographics. While the algorithm yielded strong and reusable models in relatively stable environments, such as adult inpatient care settings, the initial accuracy was notably lower in organizations providing services such as pediatrics and mental health. However, the accuracy of our algorithm significantly improved when individual trust coding templates were applied. Thematic saturation was reached after the fifth organization was recruited, and no further coding was required for the last 4 organizations. Subsequently, a framework and pipeline for deployment of the algorithm were developed to provide a standardized approach for implementation and analysis of FFT free text, ensuring ease of use.</p><p><strong>Conclusions: </strong>This study represents a significant step forward in leveraging free-text FFT data for valuable insights in diverse health care settings through the testing and development of a robust supervised learning text analytics algorithm. The disparity in some care settings was anticipated, given that the lexicon and phraseology used was inherently different from those prevalent in adult inpatient care (where the algorithm was developed). However, these challenges were addressed with further coding and testing. This approach enhanced the accuracy and reliability of the algorithm, encouraged inter- and intraorganizational collaboration, and shared learning.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"13 \",\"pages\":\"e60900\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2025-07-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12270031/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/60900\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/60900","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Leveraging AI to Drive Timely Improvements in Patient Experience Feedback: Algorithm Validation.
Background: Understanding and improving patient care is pivotal for health care providers. With increasing volumes of the Friends and Family Test (FFT) data in England, manual analysis of this patient feedback poses challenges for many health care organizations. This underscores the importance of automated text analysis, particularly in predicting sentiments and themes in real time.
Objective: Leveraging machine learning and natural language processing, this study explores the utility of a supervised algorithm to systematically test and refine the algorithm's cross-contextual performance in diverse health care settings, addressing variations in population characteristics, geographical locations, and care settings, ultimately driving improvements based on patient feedback.
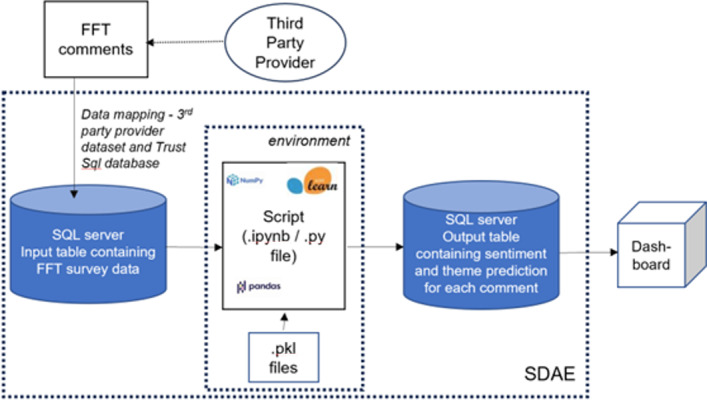
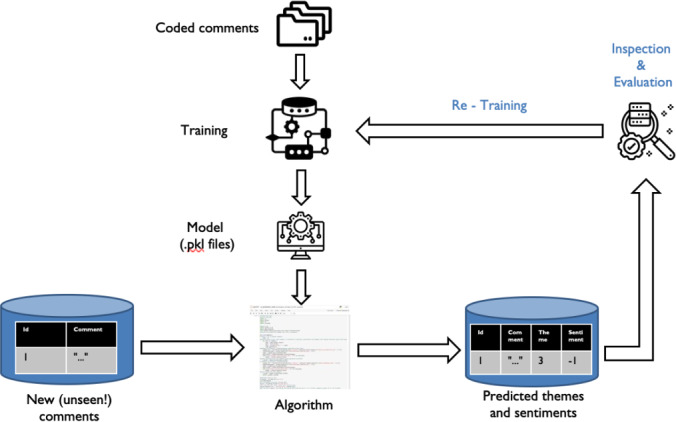
Methods: The text analytics algorithm initially developed in a large acute trust in London was further tested in 9 health care organizations with diverse care settings across England. These trusts varied in technical capacity and resource, population demographics, and FFT free text datasets. Testing and validation of the algorithm were performed, including manual coding of a subset of retrospective comments. Technical infrastructure, including coding environments and packages for algorithm testing and deployment, was optimized. The algorithm was iteratively trained using bag of words from anonymized data, tailored to accommodate contextual variations, and tested for change in algorithm performance while simultaneously rectifying issues identified.
Results: The algorithm demonstrated satisfactory overall accuracy (>75%) in predicting themes and sentiments embedded within free-text responses across a variety of care settings and population demographics. While the algorithm yielded strong and reusable models in relatively stable environments, such as adult inpatient care settings, the initial accuracy was notably lower in organizations providing services such as pediatrics and mental health. However, the accuracy of our algorithm significantly improved when individual trust coding templates were applied. Thematic saturation was reached after the fifth organization was recruited, and no further coding was required for the last 4 organizations. Subsequently, a framework and pipeline for deployment of the algorithm were developed to provide a standardized approach for implementation and analysis of FFT free text, ensuring ease of use.
Conclusions: This study represents a significant step forward in leveraging free-text FFT data for valuable insights in diverse health care settings through the testing and development of a robust supervised learning text analytics algorithm. The disparity in some care settings was anticipated, given that the lexicon and phraseology used was inherently different from those prevalent in adult inpatient care (where the algorithm was developed). However, these challenges were addressed with further coding and testing. This approach enhanced the accuracy and reliability of the algorithm, encouraged inter- and intraorganizational collaboration, and shared learning.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


