{"title":"Rprot-Vec:一种快速蛋白质结构相似度计算的深度学习方法。","authors":"Yichuan Zhang, Wen Zhang","doi":"10.1186/s12859-025-06213-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Predicting protein structural similarity and detecting homologous sequences remain fundamental and challenging tasks in computational biology. Accurate identification of structural homologs enables function inference for newly discovered or unannotated proteins. Traditional approaches often require full 3D structural data, which is unavailable for most proteins. Thus, there is a need for sequence-based methods capable of inferring structural similarity efficiently and at scale.</p><p><strong>Result: </strong>We present Rprot-Vec (Rapid Protein Vector), a deep learning model that predicts protein structural similarity and performs homology detection using only primary sequence data. The model integrates bidirectional GRU and multi-scale CNN layers with ProtT5-based encoding, enabling accurate and fast similarity estimation. Rprot-Vec achieves a 65.3% accurate similarity prediction rate in the homologous region (TM-score > 0.8), with an average prediction error of 0.0561 across all TM-score intervals. Despite having only 41% of the parameters of TM-vec, Rprot-Vec outperforms both public and locally trained TM-vec baselines in all tested settings. Additionally, we constructed and released three curated training datasets (CATH_TM_score_S/M/L), supporting further research in this area.</p><p><strong>Conclusion: </strong>Rprot-Vec offers a fast and lightweight solution for sequence-based structural similarity prediction. It can be applied in protein homology detection, structure-function inference, drug repurposing, and other downstream biological tasks. Its open-source availability and released datasets facilitate broader adoption and further development by the research community.</p>","PeriodicalId":8958,"journal":{"name":"BMC Bioinformatics","volume":"26 1","pages":"171"},"PeriodicalIF":3.3000,"publicationDate":"2025-07-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12243341/pdf/","citationCount":"0","resultStr":"{\"title\":\"Rprot-Vec: a deep learning approach for fast protein structure similarity calculation.\",\"authors\":\"Yichuan Zhang, Wen Zhang\",\"doi\":\"10.1186/s12859-025-06213-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Predicting protein structural similarity and detecting homologous sequences remain fundamental and challenging tasks in computational biology. Accurate identification of structural homologs enables function inference for newly discovered or unannotated proteins. Traditional approaches often require full 3D structural data, which is unavailable for most proteins. Thus, there is a need for sequence-based methods capable of inferring structural similarity efficiently and at scale.</p><p><strong>Result: </strong>We present Rprot-Vec (Rapid Protein Vector), a deep learning model that predicts protein structural similarity and performs homology detection using only primary sequence data. The model integrates bidirectional GRU and multi-scale CNN layers with ProtT5-based encoding, enabling accurate and fast similarity estimation. Rprot-Vec achieves a 65.3% accurate similarity prediction rate in the homologous region (TM-score > 0.8), with an average prediction error of 0.0561 across all TM-score intervals. Despite having only 41% of the parameters of TM-vec, Rprot-Vec outperforms both public and locally trained TM-vec baselines in all tested settings. Additionally, we constructed and released three curated training datasets (CATH_TM_score_S/M/L), supporting further research in this area.</p><p><strong>Conclusion: </strong>Rprot-Vec offers a fast and lightweight solution for sequence-based structural similarity prediction. It can be applied in protein homology detection, structure-function inference, drug repurposing, and other downstream biological tasks. Its open-source availability and released datasets facilitate broader adoption and further development by the research community.</p>\",\"PeriodicalId\":8958,\"journal\":{\"name\":\"BMC Bioinformatics\",\"volume\":\"26 1\",\"pages\":\"171\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2025-07-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12243341/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s12859-025-06213-1\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s12859-025-06213-1","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
Rprot-Vec: a deep learning approach for fast protein structure similarity calculation.
Background: Predicting protein structural similarity and detecting homologous sequences remain fundamental and challenging tasks in computational biology. Accurate identification of structural homologs enables function inference for newly discovered or unannotated proteins. Traditional approaches often require full 3D structural data, which is unavailable for most proteins. Thus, there is a need for sequence-based methods capable of inferring structural similarity efficiently and at scale.
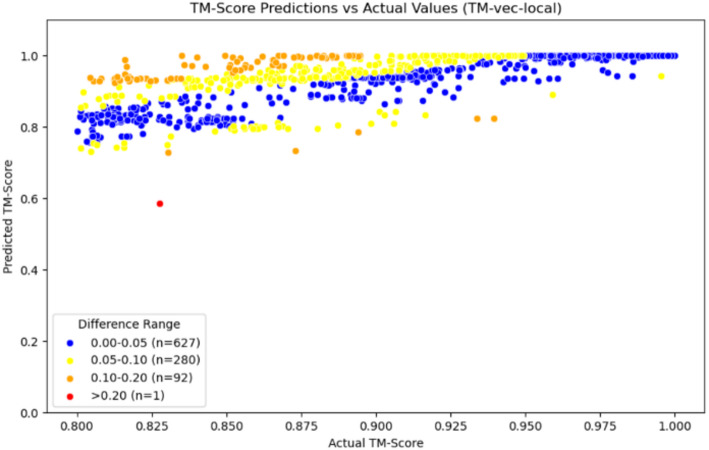
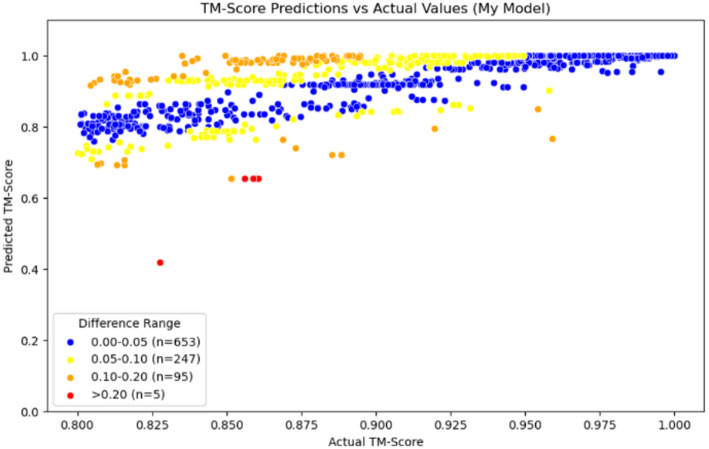
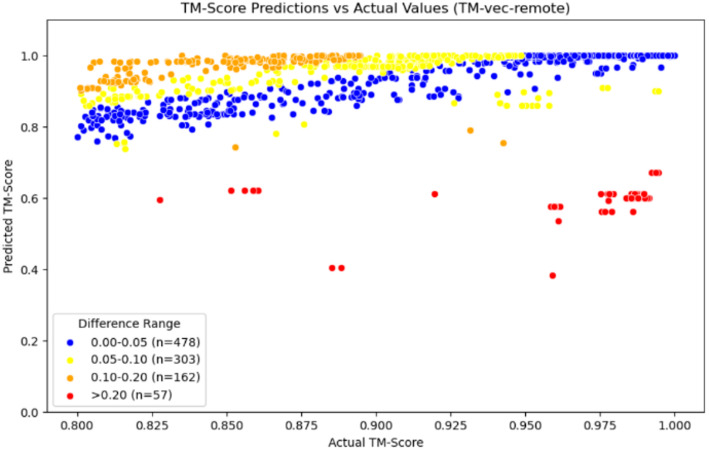
Result: We present Rprot-Vec (Rapid Protein Vector), a deep learning model that predicts protein structural similarity and performs homology detection using only primary sequence data. The model integrates bidirectional GRU and multi-scale CNN layers with ProtT5-based encoding, enabling accurate and fast similarity estimation. Rprot-Vec achieves a 65.3% accurate similarity prediction rate in the homologous region (TM-score > 0.8), with an average prediction error of 0.0561 across all TM-score intervals. Despite having only 41% of the parameters of TM-vec, Rprot-Vec outperforms both public and locally trained TM-vec baselines in all tested settings. Additionally, we constructed and released three curated training datasets (CATH_TM_score_S/M/L), supporting further research in this area.
Conclusion: Rprot-Vec offers a fast and lightweight solution for sequence-based structural similarity prediction. It can be applied in protein homology detection, structure-function inference, drug repurposing, and other downstream biological tasks. Its open-source availability and released datasets facilitate broader adoption and further development by the research community.
期刊介绍:
BMC Bioinformatics is an open access, peer-reviewed journal that considers articles on all aspects of the development, testing and novel application of computational and statistical methods for the modeling and analysis of all kinds of biological data, as well as other areas of computational biology.
BMC Bioinformatics is part of the BMC series which publishes subject-specific journals focused on the needs of individual research communities across all areas of biology and medicine. We offer an efficient, fair and friendly peer review service, and are committed to publishing all sound science, provided that there is some advance in knowledge presented by the work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


