{"title":"用于群体遗传分析的主成分判别分析方法的Python包。","authors":"Alejandro Correa Rojo, Pieter Moris, Hanne Meuwissen, Pieter Monsieurs, Dirk Valkenborg","doi":"10.1093/bioadv/vbaf143","DOIUrl":null,"url":null,"abstract":"<p><strong>Summary: </strong>The Discriminant Analysis of Principal Components method is a pivotal tool in population genetics, combining principal component analysis and linear discriminant analysis to assess the genetic structure of populations using genetic markers, focusing on the description of variation between genetic clusters. Despite its utility, the original R implementation in the adegenet package faces computational challenges with large genomic datasets. To address these limitations, we introduce DAPCy, a Python package leveraging the scikit-learn library to enhance the method's scalability and efficiency. DAPCy supports large datasets by utilizing compressed sparse matrices and truncated singular value decomposition for dimensionality reduction, coupled with training-test cross-validation for robust model evaluation. It also includes modules for <i>de novo</i> genetic clustering and extensive visualization and reporting capabilities. Compared to the original R implementation, DAPCy can process genomic datasets with thousands of samples and features in less computational time and with reduced memory usage. To show DAPCy's computational capabilities, we benchmarked it with the R implementation using the <i>Plasmodium falciparum</i> dataset from MalariaGEN and the 1000 Genomes Project.</p><p><strong>Availability and implementation: </strong>DAPCy can be installed as a Python package through pip. Source code is available on https://gitlab.com/uhasselt-bioinfo/dapcy. Documentation and a tutorial can be found on https://uhasselt-bioinfo.gitlab.io/dapcy/.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf143"},"PeriodicalIF":2.8000,"publicationDate":"2025-06-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12237503/pdf/","citationCount":"0","resultStr":"{\"title\":\"DAPCy: a Python package for the discriminant analysis of principal components method for population genetic analyses.\",\"authors\":\"Alejandro Correa Rojo, Pieter Moris, Hanne Meuwissen, Pieter Monsieurs, Dirk Valkenborg\",\"doi\":\"10.1093/bioadv/vbaf143\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Summary: </strong>The Discriminant Analysis of Principal Components method is a pivotal tool in population genetics, combining principal component analysis and linear discriminant analysis to assess the genetic structure of populations using genetic markers, focusing on the description of variation between genetic clusters. Despite its utility, the original R implementation in the adegenet package faces computational challenges with large genomic datasets. To address these limitations, we introduce DAPCy, a Python package leveraging the scikit-learn library to enhance the method's scalability and efficiency. DAPCy supports large datasets by utilizing compressed sparse matrices and truncated singular value decomposition for dimensionality reduction, coupled with training-test cross-validation for robust model evaluation. It also includes modules for <i>de novo</i> genetic clustering and extensive visualization and reporting capabilities. Compared to the original R implementation, DAPCy can process genomic datasets with thousands of samples and features in less computational time and with reduced memory usage. To show DAPCy's computational capabilities, we benchmarked it with the R implementation using the <i>Plasmodium falciparum</i> dataset from MalariaGEN and the 1000 Genomes Project.</p><p><strong>Availability and implementation: </strong>DAPCy can be installed as a Python package through pip. Source code is available on https://gitlab.com/uhasselt-bioinfo/dapcy. Documentation and a tutorial can be found on https://uhasselt-bioinfo.gitlab.io/dapcy/.</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"5 1\",\"pages\":\"vbaf143\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-06-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12237503/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbaf143\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf143","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
DAPCy: a Python package for the discriminant analysis of principal components method for population genetic analyses.
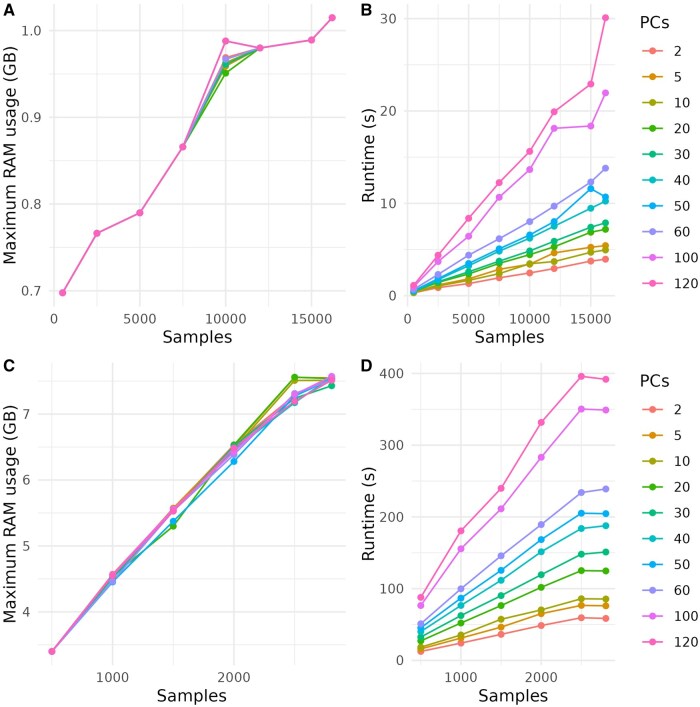
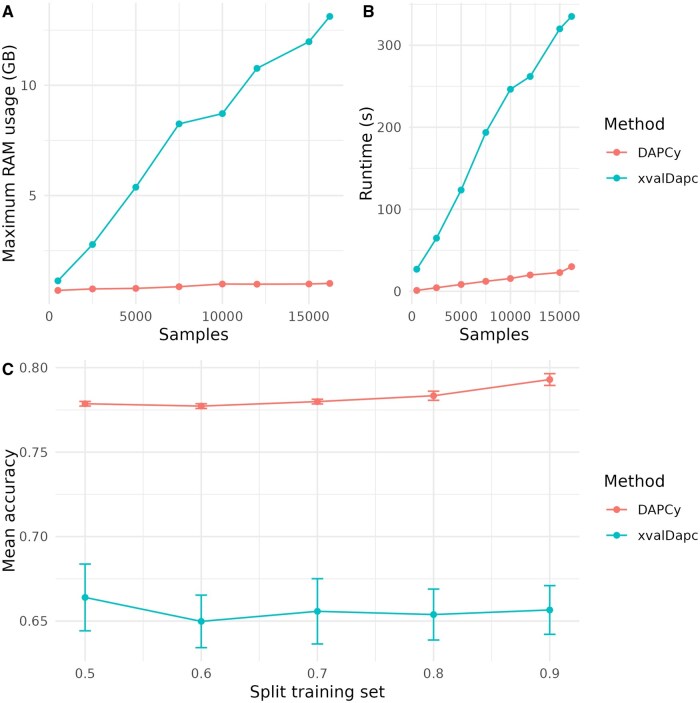
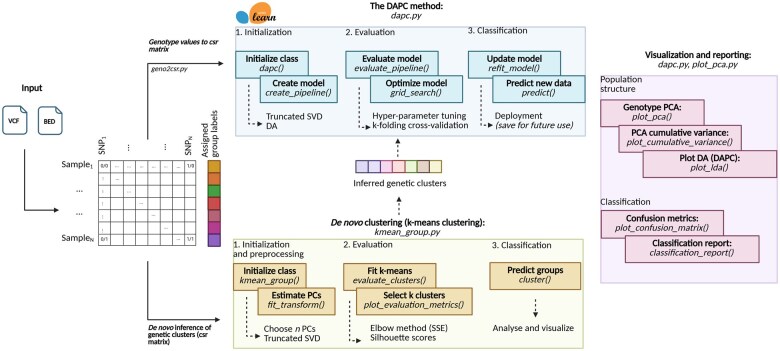
Summary: The Discriminant Analysis of Principal Components method is a pivotal tool in population genetics, combining principal component analysis and linear discriminant analysis to assess the genetic structure of populations using genetic markers, focusing on the description of variation between genetic clusters. Despite its utility, the original R implementation in the adegenet package faces computational challenges with large genomic datasets. To address these limitations, we introduce DAPCy, a Python package leveraging the scikit-learn library to enhance the method's scalability and efficiency. DAPCy supports large datasets by utilizing compressed sparse matrices and truncated singular value decomposition for dimensionality reduction, coupled with training-test cross-validation for robust model evaluation. It also includes modules for de novo genetic clustering and extensive visualization and reporting capabilities. Compared to the original R implementation, DAPCy can process genomic datasets with thousands of samples and features in less computational time and with reduced memory usage. To show DAPCy's computational capabilities, we benchmarked it with the R implementation using the Plasmodium falciparum dataset from MalariaGEN and the 1000 Genomes Project.
Availability and implementation: DAPCy can be installed as a Python package through pip. Source code is available on https://gitlab.com/uhasselt-bioinfo/dapcy. Documentation and a tutorial can be found on https://uhasselt-bioinfo.gitlab.io/dapcy/.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:



