通过两级遗传算法进行特征工程
IF 4.9
引用次数: 0
摘要
深度学习模型因其高预测性能而被广泛使用,但往往缺乏可解释性。传统的机器学习方法,如逻辑回归和集成模型,提供了更好的可解释性,但通常具有较低的预测能力。特征工程可以通过识别优化分类的特征来提高可解释模型的性能。然而,现有的特征工程方法面临着局限性:(1)通常没有对特征进行非线性变换,忽略了非线性空间的优点;(2)通常只进行一次特征选择,无法通过重复实验降低不确定性;(3)最小冗余最大相关性(mRMR)等传统方法需要额外的超参数来定义所选特征的数量。为了解决这些问题,本研究提出了一种分层的两级特征工程方法。在第一级,使用多个自举训练集识别相关特征。对于每个训练集,使用7个非线性变换函数对特征进行扩展,并使用非支配排序遗传算法II (NSGA-II)选择最大集成模型性能的最小特征集。在第二层,候选特征集使用两种策略进行聚合。我们在来自不同领域的12个数据集上评估了我们的方法,在减少特征集大小54.5%的同时,平均F1分数提高了1.5%。此外,我们的方法优于或匹配传统的基于过滤器的方法。我们的方法可以通过Python库(feature-gen)获得,使其他人能够从这个工具中受益。本研究强调了进化算法在生成增强可解释机器学习模型性能的特征集方面的效用。本文章由计算机程序翻译,如有差异,请以英文原文为准。
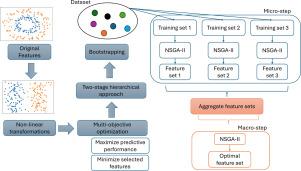
Feature engineering through two-level genetic algorithm
Deep learning models are widely used for their high predictive performance, but often lack interpretability. Traditional machine learning methods, such as logistic regression and ensemble models, offer greater interpretability but typically have lower predictive capacity. Feature engineering can enhance the performance of interpretable models by identifying features that optimize classification. However, existing feature engineering methods face limitations: (1) they usually do not apply non-linear transformations to features, ignoring the benefits of non-linear spaces; (2) they usually perform feature selection only once, failing to reduce uncertainty through repeated experiments; and (3) traditional methods like minimum redundancy maximum relevance (mRMR) require additional hyperparameters to define the number of selected features. To address these issues, this study proposed a hierarchical two-level feature engineering approach. In the first level, relevant features were identified using multiple bootstrapped training sets. For each training set, the features were expanded using seven non-linear transformation functions, and the minimum feature set maximizing ensemble model performance was selected using the Non-Dominated Sorting Genetic Algorithm II (NSGA-II). In the second level, candidate feature sets were aggregated using two strategies. We evaluated our approach on twelve datasets from various fields, achieving an average F1 score improvement of 1.5% while reducing the feature set size by 54.5%. Moreover, our approach outperformed or matched traditional filter-based methods. Our approach is available through a Python library (feature-gen), enabling others to benefit from this tool. This study highlights the utility of evolutionary algorithms to generate feature sets that enhance the performance of interpretable machine learning models.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Machine learning with applications
Management Science and Operations Research, Artificial Intelligence, Computer Science Applications
自引率
0.00%
发文量
0
审稿时长
98 days
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


