Mateus Rodrigues Alessi, Heitor Augusto Gomes, Gabriel Oliveira, Matheus Lopes de Castro, Fabiano Grenteski, Leticia Miyashiro, Camila do Valle, Leticia Tozzini Tavares da Silva, Cristina Okamoto
{"title":"医学生ChatGPT-3.5和ChatGPT-4.0在巴西国家医学考试中回答问题的比较表现:横断面问卷研究","authors":"Mateus Rodrigues Alessi, Heitor Augusto Gomes, Gabriel Oliveira, Matheus Lopes de Castro, Fabiano Grenteski, Leticia Miyashiro, Camila do Valle, Leticia Tozzini Tavares da Silva, Cristina Okamoto","doi":"10.2196/66552","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence has advanced significantly in various fields, including medicine, where tools like ChatGPT (GPT) have demonstrated remarkable capabilities in interpreting and synthesizing complex medical data. Since its launch in 2019, GPT has evolved, with version 4.0 offering enhanced processing power, image interpretation, and more accurate responses. In medicine, GPT has been used for diagnosis, research, and education, achieving significant milestones like passing the United States Medical Licensing Examination. Recent studies show that GPT 4.0 outperforms earlier versions and even medical students on medical exams.</p><p><strong>Objective: </strong>This study aimed to evaluate and compare the performance of GPT versions 3.5 and 4.0 on Brazilian Progress Tests (PT) from 2021 to 2023, analyzing their accuracy compared to medical students.</p><p><strong>Methods: </strong>A cross-sectional observational study was conducted using 333 multiple-choice questions from the PT, excluding questions with images and those nullified or repeated. All questions were presented sequentially without modification to their structure. The performance of GPT versions was compared using statistical methods and medical students' scores were included for context.</p><p><strong>Results: </strong>There was a statistically significant difference in total performance scores across the 2021, 2022, and 2023 exams between GPT-3.5 and GPT-4.0 (P=.03). However, this significance did not remain after Bonferroni correction. On average, GPT v3.5 scored 68.4%, whereas v4.0 achieved 87.2%, reflecting an absolute improvement of 18.8% and a relative increase of 27.4% in accuracy. When broken down by subject, the average scores for GPT-3.5 and GPT-4.0, respectively, were as follows: surgery (73.5% vs 88.0%, P=.03), basic sciences (77.5% vs 96.2%, P=.004), internal medicine (61.5% vs 75.1%, P=.14), gynecology and obstetrics (64.5% vs 94.8%, P=.002), pediatrics (58.5% vs 80.0%, P=.02), and public health (77.8% vs 89.6%, P=.02). After Bonferroni correction, only basic sciences and gynecology and obstetrics retained statistically significant differences.</p><p><strong>Conclusions: </strong>GPT-4.0 demonstrates superior accuracy compared to its predecessor in answering medical questions on the PT. These results are similar to other studies, indicating that we are approaching a new revolution in medicine.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e66552"},"PeriodicalIF":2.0000,"publicationDate":"2025-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223693/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparative Performance of Medical Students, ChatGPT-3.5 and ChatGPT-4.0 in Answering Questions From a Brazilian National Medical Exam: Cross-Sectional Questionnaire Study.\",\"authors\":\"Mateus Rodrigues Alessi, Heitor Augusto Gomes, Gabriel Oliveira, Matheus Lopes de Castro, Fabiano Grenteski, Leticia Miyashiro, Camila do Valle, Leticia Tozzini Tavares da Silva, Cristina Okamoto\",\"doi\":\"10.2196/66552\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Artificial intelligence has advanced significantly in various fields, including medicine, where tools like ChatGPT (GPT) have demonstrated remarkable capabilities in interpreting and synthesizing complex medical data. Since its launch in 2019, GPT has evolved, with version 4.0 offering enhanced processing power, image interpretation, and more accurate responses. In medicine, GPT has been used for diagnosis, research, and education, achieving significant milestones like passing the United States Medical Licensing Examination. Recent studies show that GPT 4.0 outperforms earlier versions and even medical students on medical exams.</p><p><strong>Objective: </strong>This study aimed to evaluate and compare the performance of GPT versions 3.5 and 4.0 on Brazilian Progress Tests (PT) from 2021 to 2023, analyzing their accuracy compared to medical students.</p><p><strong>Methods: </strong>A cross-sectional observational study was conducted using 333 multiple-choice questions from the PT, excluding questions with images and those nullified or repeated. All questions were presented sequentially without modification to their structure. The performance of GPT versions was compared using statistical methods and medical students' scores were included for context.</p><p><strong>Results: </strong>There was a statistically significant difference in total performance scores across the 2021, 2022, and 2023 exams between GPT-3.5 and GPT-4.0 (P=.03). However, this significance did not remain after Bonferroni correction. On average, GPT v3.5 scored 68.4%, whereas v4.0 achieved 87.2%, reflecting an absolute improvement of 18.8% and a relative increase of 27.4% in accuracy. When broken down by subject, the average scores for GPT-3.5 and GPT-4.0, respectively, were as follows: surgery (73.5% vs 88.0%, P=.03), basic sciences (77.5% vs 96.2%, P=.004), internal medicine (61.5% vs 75.1%, P=.14), gynecology and obstetrics (64.5% vs 94.8%, P=.002), pediatrics (58.5% vs 80.0%, P=.02), and public health (77.8% vs 89.6%, P=.02). After Bonferroni correction, only basic sciences and gynecology and obstetrics retained statistically significant differences.</p><p><strong>Conclusions: </strong>GPT-4.0 demonstrates superior accuracy compared to its predecessor in answering medical questions on the PT. These results are similar to other studies, indicating that we are approaching a new revolution in medicine.</p>\",\"PeriodicalId\":73551,\"journal\":{\"name\":\"JMIR AI\",\"volume\":\"4 \",\"pages\":\"e66552\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2025-05-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223693/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR AI\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/66552\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/66552","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:人工智能在包括医学在内的各个领域取得了重大进展,ChatGPT (GPT)等工具在解释和综合复杂的医疗数据方面表现出了卓越的能力。自2019年推出以来,GPT不断发展,4.0版本提供了增强的处理能力、图像解释和更准确的响应。在医学领域,GPT已被用于诊断、研究和教育,取得了重要的里程碑,如通过美国医疗执照考试。最近的研究表明,GPT 4.0在医学考试中的表现超过了早期版本,甚至超过了医科学生。目的:本研究旨在评估和比较2021年至2023年GPT 3.5和4.0版本在巴西进步测试(PT)中的表现,分析其与医科学生相比的准确性。方法:采用PT中的333个选择题进行横断面观察性研究,排除带有图像和无效或重复的问题。所有问题都是按顺序提出的,结构没有改变。采用统计方法比较GPT版本的表现,并将医学生的得分纳入上下文。结果:GPT-3.5与GPT-4.0在2021年、2022年和2023年考试中的总成绩得分差异有统计学意义(P=.03)。然而,这种意义在Bonferroni修正后并没有保留。GPT v3.5的平均得分为68.4%,而v4.0的平均得分为87.2%,反映了18.8%的绝对改进和27.4%的准确度相对提高。按学科分类,GPT-3.5和GPT-4.0的平均得分分别为:外科(73.5% vs 88.0%, P= 0.03)、基础科学(77.5% vs 96.2%, P= 0.004)、内科(61.5% vs 75.1%, P= 0.14)、妇产科(64.5% vs 94.8%, P= 0.002)、儿科(58.5% vs 80.0%, P= 0.02)和公共卫生(77.8% vs 89.6%, P= 0.02)。经Bonferroni校正后,只有基础科学和妇产科仍有统计学上的显著差异。结论:GPT-4.0在PT上回答医学问题的准确性优于其前身。这些结果与其他研究相似,表明我们正在接近医学的新革命。
Comparative Performance of Medical Students, ChatGPT-3.5 and ChatGPT-4.0 in Answering Questions From a Brazilian National Medical Exam: Cross-Sectional Questionnaire Study.
Background: Artificial intelligence has advanced significantly in various fields, including medicine, where tools like ChatGPT (GPT) have demonstrated remarkable capabilities in interpreting and synthesizing complex medical data. Since its launch in 2019, GPT has evolved, with version 4.0 offering enhanced processing power, image interpretation, and more accurate responses. In medicine, GPT has been used for diagnosis, research, and education, achieving significant milestones like passing the United States Medical Licensing Examination. Recent studies show that GPT 4.0 outperforms earlier versions and even medical students on medical exams.
Objective: This study aimed to evaluate and compare the performance of GPT versions 3.5 and 4.0 on Brazilian Progress Tests (PT) from 2021 to 2023, analyzing their accuracy compared to medical students.
Methods: A cross-sectional observational study was conducted using 333 multiple-choice questions from the PT, excluding questions with images and those nullified or repeated. All questions were presented sequentially without modification to their structure. The performance of GPT versions was compared using statistical methods and medical students' scores were included for context.
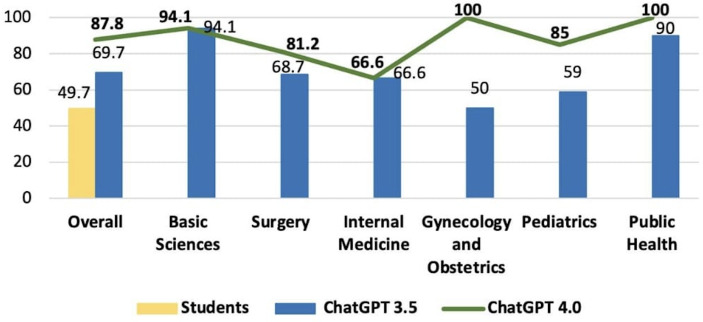
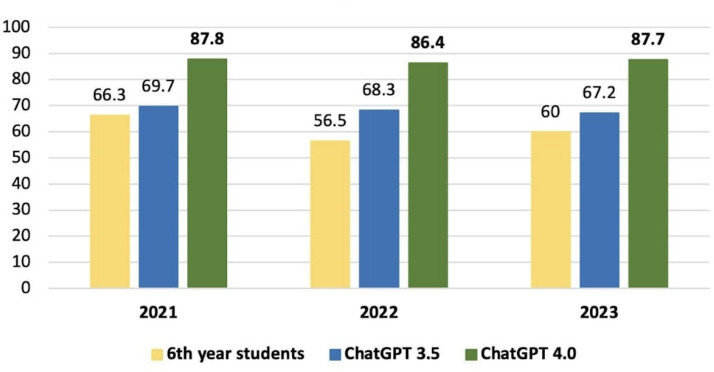
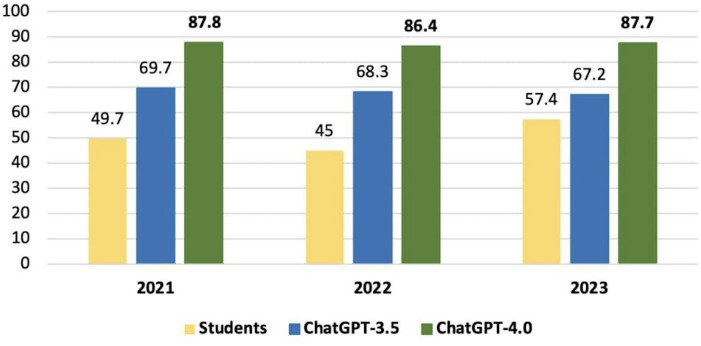
Results: There was a statistically significant difference in total performance scores across the 2021, 2022, and 2023 exams between GPT-3.5 and GPT-4.0 (P=.03). However, this significance did not remain after Bonferroni correction. On average, GPT v3.5 scored 68.4%, whereas v4.0 achieved 87.2%, reflecting an absolute improvement of 18.8% and a relative increase of 27.4% in accuracy. When broken down by subject, the average scores for GPT-3.5 and GPT-4.0, respectively, were as follows: surgery (73.5% vs 88.0%, P=.03), basic sciences (77.5% vs 96.2%, P=.004), internal medicine (61.5% vs 75.1%, P=.14), gynecology and obstetrics (64.5% vs 94.8%, P=.002), pediatrics (58.5% vs 80.0%, P=.02), and public health (77.8% vs 89.6%, P=.02). After Bonferroni correction, only basic sciences and gynecology and obstetrics retained statistically significant differences.
Conclusions: GPT-4.0 demonstrates superior accuracy compared to its predecessor in answering medical questions on the PT. These results are similar to other studies, indicating that we are approaching a new revolution in medicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


