Fu Zheng, Liu XingMing, Xu JuYing, Tao MengYing, Yang BaoJian, Shan Yan, Ye KeWei, Lu ZhiKai, Huang Cheng, Qi KeLan, Chen XiHao, Du WenFei, He Ping, Wang RunYu, Ying Ying, Bu XiaoHui
{"title":"通过分步人工智能预标注,显著降低超声医学图像数据库构建中的人工标注成本。","authors":"Fu Zheng, Liu XingMing, Xu JuYing, Tao MengYing, Yang BaoJian, Shan Yan, Ye KeWei, Lu ZhiKai, Huang Cheng, Qi KeLan, Chen XiHao, Du WenFei, He Ping, Wang RunYu, Ying Ying, Bu XiaoHui","doi":"10.1371/journal.pdig.0000738","DOIUrl":null,"url":null,"abstract":"<p><p>This study investigates the feasibility of reducing manual image annotation costs in medical image database construction by utilizing a step by step approach where the Artificial Intelligence model (AI model) trained on a previous batch of data automatically pre-annotates the next batch of image data, taking ultrasound image of thyroid nodule annotation as an example. The study used YOLOv8 as the AI model. During the AI model training, in addition to conventional image augmentation techniques, augmentation methods specifically tailored for ultrasound images were employed to balance the quantity differences between thyroid nodule classes and enhance model training effectiveness. The study found that training the model with augmented data significantly outperformed training with raw images data. When the number of original images number was only 1,360, with 7 thyroid nodule classifications, pre-annotation using the AI model trained on augmented data could save at least 30% of the manual annotation workload for junior physicians. When the scale of original images number reached 6,800, the classification accuracy of the AI model trained on augmented data was very close with that of junior physicians, eliminating the need for manual preliminary annotation.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 6","pages":"e0000738"},"PeriodicalIF":7.7000,"publicationDate":"2025-06-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12208487/pdf/","citationCount":"0","resultStr":"{\"title\":\"Significant reduction in manual annotation costs in ultrasound medical image database construction through step by step artificial intelligence pre-annotation.\",\"authors\":\"Fu Zheng, Liu XingMing, Xu JuYing, Tao MengYing, Yang BaoJian, Shan Yan, Ye KeWei, Lu ZhiKai, Huang Cheng, Qi KeLan, Chen XiHao, Du WenFei, He Ping, Wang RunYu, Ying Ying, Bu XiaoHui\",\"doi\":\"10.1371/journal.pdig.0000738\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>This study investigates the feasibility of reducing manual image annotation costs in medical image database construction by utilizing a step by step approach where the Artificial Intelligence model (AI model) trained on a previous batch of data automatically pre-annotates the next batch of image data, taking ultrasound image of thyroid nodule annotation as an example. The study used YOLOv8 as the AI model. During the AI model training, in addition to conventional image augmentation techniques, augmentation methods specifically tailored for ultrasound images were employed to balance the quantity differences between thyroid nodule classes and enhance model training effectiveness. The study found that training the model with augmented data significantly outperformed training with raw images data. When the number of original images number was only 1,360, with 7 thyroid nodule classifications, pre-annotation using the AI model trained on augmented data could save at least 30% of the manual annotation workload for junior physicians. When the scale of original images number reached 6,800, the classification accuracy of the AI model trained on augmented data was very close with that of junior physicians, eliminating the need for manual preliminary annotation.</p>\",\"PeriodicalId\":74465,\"journal\":{\"name\":\"PLOS digital health\",\"volume\":\"4 6\",\"pages\":\"e0000738\"},\"PeriodicalIF\":7.7000,\"publicationDate\":\"2025-06-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12208487/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLOS digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pdig.0000738\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/6/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000738","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
Significant reduction in manual annotation costs in ultrasound medical image database construction through step by step artificial intelligence pre-annotation.
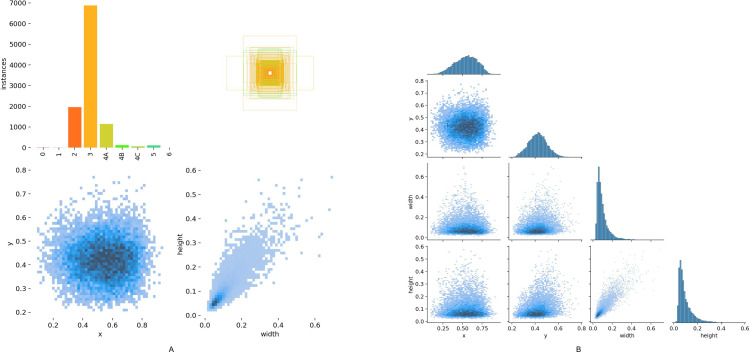
This study investigates the feasibility of reducing manual image annotation costs in medical image database construction by utilizing a step by step approach where the Artificial Intelligence model (AI model) trained on a previous batch of data automatically pre-annotates the next batch of image data, taking ultrasound image of thyroid nodule annotation as an example. The study used YOLOv8 as the AI model. During the AI model training, in addition to conventional image augmentation techniques, augmentation methods specifically tailored for ultrasound images were employed to balance the quantity differences between thyroid nodule classes and enhance model training effectiveness. The study found that training the model with augmented data significantly outperformed training with raw images data. When the number of original images number was only 1,360, with 7 thyroid nodule classifications, pre-annotation using the AI model trained on augmented data could save at least 30% of the manual annotation workload for junior physicians. When the scale of original images number reached 6,800, the classification accuracy of the AI model trained on augmented data was very close with that of junior physicians, eliminating the need for manual preliminary annotation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


