Helene Bei Thomsen, Livie Yumeng Li, Anders Aasted Isaksen, Benjamin Lebiecka-Johansen, Charline Bour, Guy Fagherazzi, William P T M van Doorn, Tibor V Varga, Adam Hulman
{"title":"基于持续血糖监测的60分钟1型糖尿病患者血糖预测的种族差异","authors":"Helene Bei Thomsen, Livie Yumeng Li, Anders Aasted Isaksen, Benjamin Lebiecka-Johansen, Charline Bour, Guy Fagherazzi, William P T M van Doorn, Tibor V Varga, Adam Hulman","doi":"10.1371/journal.pdig.0000918","DOIUrl":null,"url":null,"abstract":"<p><p>Non-Hispanic white (White) populations are overrepresented in medical studies. Potential healthcare disparities can happen when machine learning models, used in diabetes technologies, are trained on data from primarily White patients. We aimed to evaluate algorithmic fairness in glucose predictions. This study utilized continuous glucose monitoring (CGM) data from 101 White and 104 Black participants with type 1 diabetes collected by the JAEB Center for Health Research, US. Long short-term memory (LSTM) deep learning models were trained on 11 datasets of different proportions of White and Black participants and tailored to each individual using transfer learning to predict glucose 60 minutes ahead based on 60-minute windows. Root mean squared errors (RMSE) were calculated for each participant. Linear mixed-effect models were used to investigate the association between racial composition and RMSE while accounting for age, sex, and training data size. A median of 9 weeks (IQR: 7, 10) of CGM data was available per participant. The divergence in performance (RMSE slope by proportion) was not statistically significant for either group. However, the slope difference (from 0% White and 100% Black to 100% White and 0% Black) between groups was statistically significant (p = 0.02), meaning the RMSE increased 0.04 [0.01, 0.08] mmol/L more for Black participants compared to White participants when the proportion of White participants increased from 0 to 100% in the training data. This difference was attenuated in the transfer learned models (RMSE: 0.02 [-0.01, 0.05] mmol/L, p = 0.20). The racial composition of training data created a small statistically significant difference in the performance of the models, which was not present after using transfer learning. This demonstrates the importance of diversity in datasets and the potential value of transfer learning for developing more fair prediction models.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 6","pages":"e0000918"},"PeriodicalIF":7.7000,"publicationDate":"2025-06-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12208448/pdf/","citationCount":"0","resultStr":"{\"title\":\"Racial disparities in continuous glucose monitoring-based 60-min glucose predictions among people with type 1 diabetes.\",\"authors\":\"Helene Bei Thomsen, Livie Yumeng Li, Anders Aasted Isaksen, Benjamin Lebiecka-Johansen, Charline Bour, Guy Fagherazzi, William P T M van Doorn, Tibor V Varga, Adam Hulman\",\"doi\":\"10.1371/journal.pdig.0000918\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Non-Hispanic white (White) populations are overrepresented in medical studies. Potential healthcare disparities can happen when machine learning models, used in diabetes technologies, are trained on data from primarily White patients. We aimed to evaluate algorithmic fairness in glucose predictions. This study utilized continuous glucose monitoring (CGM) data from 101 White and 104 Black participants with type 1 diabetes collected by the JAEB Center for Health Research, US. Long short-term memory (LSTM) deep learning models were trained on 11 datasets of different proportions of White and Black participants and tailored to each individual using transfer learning to predict glucose 60 minutes ahead based on 60-minute windows. Root mean squared errors (RMSE) were calculated for each participant. Linear mixed-effect models were used to investigate the association between racial composition and RMSE while accounting for age, sex, and training data size. A median of 9 weeks (IQR: 7, 10) of CGM data was available per participant. The divergence in performance (RMSE slope by proportion) was not statistically significant for either group. However, the slope difference (from 0% White and 100% Black to 100% White and 0% Black) between groups was statistically significant (p = 0.02), meaning the RMSE increased 0.04 [0.01, 0.08] mmol/L more for Black participants compared to White participants when the proportion of White participants increased from 0 to 100% in the training data. This difference was attenuated in the transfer learned models (RMSE: 0.02 [-0.01, 0.05] mmol/L, p = 0.20). The racial composition of training data created a small statistically significant difference in the performance of the models, which was not present after using transfer learning. This demonstrates the importance of diversity in datasets and the potential value of transfer learning for developing more fair prediction models.</p>\",\"PeriodicalId\":74465,\"journal\":{\"name\":\"PLOS digital health\",\"volume\":\"4 6\",\"pages\":\"e0000918\"},\"PeriodicalIF\":7.7000,\"publicationDate\":\"2025-06-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12208448/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"PLOS digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1371/journal.pdig.0000918\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/6/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000918","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
Racial disparities in continuous glucose monitoring-based 60-min glucose predictions among people with type 1 diabetes.
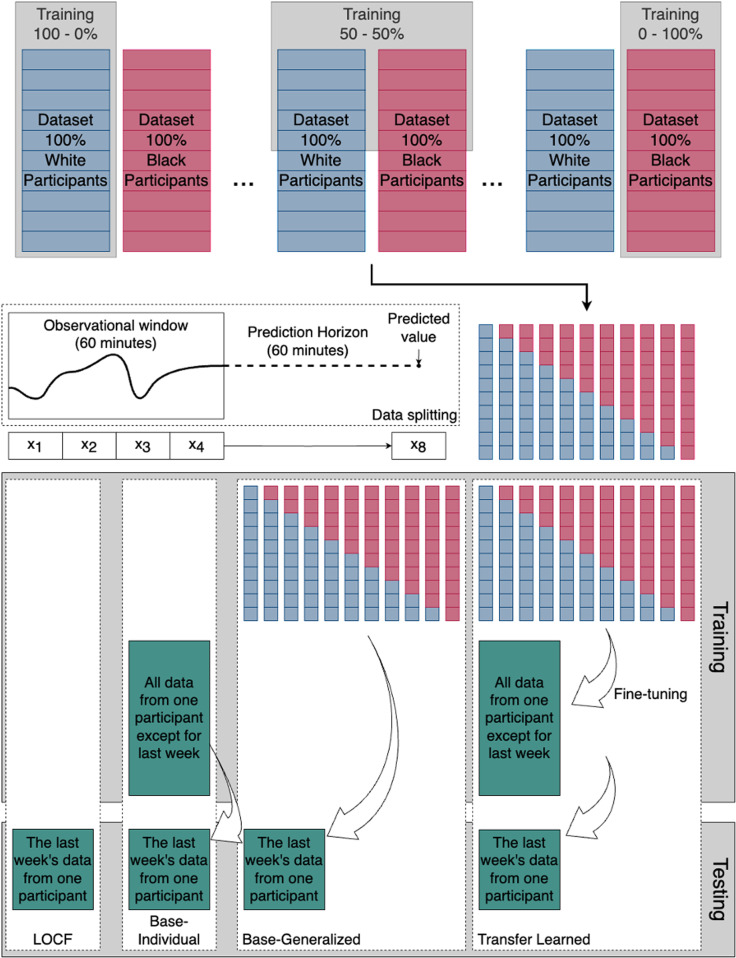
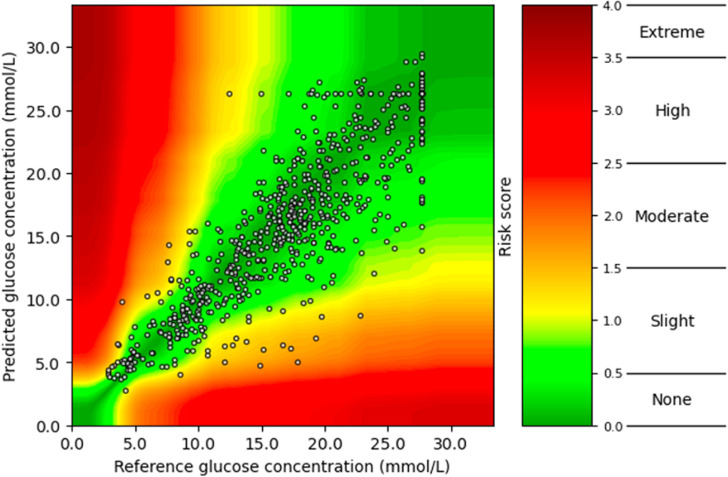
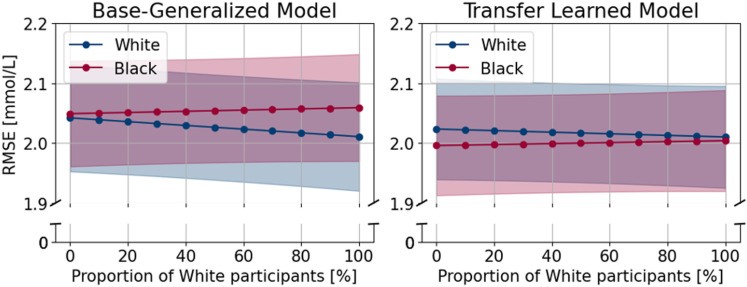
Non-Hispanic white (White) populations are overrepresented in medical studies. Potential healthcare disparities can happen when machine learning models, used in diabetes technologies, are trained on data from primarily White patients. We aimed to evaluate algorithmic fairness in glucose predictions. This study utilized continuous glucose monitoring (CGM) data from 101 White and 104 Black participants with type 1 diabetes collected by the JAEB Center for Health Research, US. Long short-term memory (LSTM) deep learning models were trained on 11 datasets of different proportions of White and Black participants and tailored to each individual using transfer learning to predict glucose 60 minutes ahead based on 60-minute windows. Root mean squared errors (RMSE) were calculated for each participant. Linear mixed-effect models were used to investigate the association between racial composition and RMSE while accounting for age, sex, and training data size. A median of 9 weeks (IQR: 7, 10) of CGM data was available per participant. The divergence in performance (RMSE slope by proportion) was not statistically significant for either group. However, the slope difference (from 0% White and 100% Black to 100% White and 0% Black) between groups was statistically significant (p = 0.02), meaning the RMSE increased 0.04 [0.01, 0.08] mmol/L more for Black participants compared to White participants when the proportion of White participants increased from 0 to 100% in the training data. This difference was attenuated in the transfer learned models (RMSE: 0.02 [-0.01, 0.05] mmol/L, p = 0.20). The racial composition of training data created a small statistically significant difference in the performance of the models, which was not present after using transfer learning. This demonstrates the importance of diversity in datasets and the potential value of transfer learning for developing more fair prediction models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


