研究数据输入方法对对抗性攻击的鲁棒性
IF 5.4
2区 计算机科学
Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
摘要
网络安全攻击,如中毒和逃避,可以故意在数据中引入不同形式的虚假或误导性信息,可能导致关键基础设施的灾难性后果,如供水或能源发电厂。虽然许多研究已经调查了这些攻击对基于模型的预测方法的影响,但它们往往忽略了用于训练这些模型的数据中存在的杂质。其中一种形式是缺少数据,在一个或多个特性中缺少值。这个问题通常是通过用合理的估计输入缺失值来解决的,这直接影响了分类器的性能。这项工作的目标是通过调查不同类型的网络安全攻击如何影响归算过程来促进以数据为中心的人工智能方法。为此,我们在29个真实数据集(包括NSL-KDD和Edge-IIoT数据集)上使用四种流行的逃避和投毒攻击策略进行了实验,这些数据集被用作案例研究。对于对抗性攻击策略,我们采用了快速梯度符号法,Carlini &;Wagner, Project Gradient Descent, and Poison Attack against Support Vector Machine algorithm。此外,在非随机缺失、完全随机缺失和随机缺失机制下,使用三种缺失率(5%、20%、40%)测试了四种最先进的imputation策略。我们使用MAE评估imputation质量,同时使用Kolmogorov-Smirnov检验和卡方检验分析数据分布移位。此外,我们通过使用F1-score、Accuracy和AUC在输入的数据集上训练XGBoost分类器来测量分类性能。为了深化我们的分析,我们还纳入了六个复杂性指标来描述对抗性攻击和imputation策略如何影响数据集复杂性。我们的研究结果表明,对抗性攻击显著影响归咎过程。在与质量误差有关的归算评估方面,与其他对抗性方法相比,采用项目梯度下降攻击的归算方案具有更强的鲁棒性。关于数据分布误差,Kolmogorov-Smirnov检验的结果表明,在数值特征的背景下,所有的归算策略都与基线不同(没有丢失数据),而对于分类背景,Chi-Squared检验证明归算与基线之间没有差异。本文章由计算机程序翻译,如有差异,请以英文原文为准。
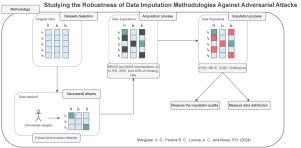
Studying the robustness of data imputation methodologies against adversarial attacks
Cybersecurity attacks, such as poisoning and evasion, can intentionally introduce false or misleading information in different forms into data, potentially leading to catastrophic consequences for critical infrastructures, like water supply or energy power plants. While numerous studies have investigated the impact of these attacks on model-based prediction approaches, they often overlook the impurities present in the data used to train these models. One of those forms is missing data, the absence of values in one or more features. This issue is typically addressed by imputing missing values with plausible estimates, which directly impacts the performance of the classifier.
The goal of this work is to promote a Data-centric AI approach by investigating how different types of cybersecurity attacks impact the imputation process. To this end, we conducted experiments using four popular evasion and poisoning attacks strategies across 29 real-world datasets, including the NSL-KDD and Edge-IIoT datasets, which were used as case study. For the adversarial attack strategies, we employed the Fast Gradient Sign Method, Carlini & Wagner, Project Gradient Descent, and Poison Attack against Support Vector Machine algorithm. Also, four state-of-the-art imputation strategies were tested under Missing Not At Random, Missing Completely at Random, and Missing At Random mechanisms using three missing rates (5%, 20%, 40%). We assessed imputation quality using MAE, while data distribution shifts were analyzed with the Kolmogorov–Smirnov and Chi-square tests. Furthermore, we measured classification performance by training an XGBoost classifier on the imputed datasets, using F1-score, Accuracy, and AUC. To deepen our analysis, we also incorporated six complexity metrics to characterize how adversarial attacks and imputation strategies impact dataset complexity. Our findings demonstrate that adversarial attacks significantly impact the imputation process. In terms of imputation assessment in what concerns to quality error, the scenario that enrolees imputation with Project Gradient Descent attack proved to be more robust in comparison to other adversarial methods. Regarding data distribution error, results from the Kolmogorov–Smirnov test indicate that in the context of numerical features, all imputation strategies differ from the baseline (without missing data) however for the categorical context Chi-Squared test proved no difference between imputation and the baseline.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computers & Security
工程技术-计算机:信息系统
CiteScore
12.40
自引率
7.10%
发文量
365
审稿时长
10.7 months
期刊介绍:
Computers & Security is the most respected technical journal in the IT security field. With its high-profile editorial board and informative regular features and columns, the journal is essential reading for IT security professionals around the world.
Computers & Security provides you with a unique blend of leading edge research and sound practical management advice. It is aimed at the professional involved with computer security, audit, control and data integrity in all sectors - industry, commerce and academia. Recognized worldwide as THE primary source of reference for applied research and technical expertise it is your first step to fully secure systems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


