{"title":"维管植物DNA条形码数据库的自动化管理","authors":"Andreas Kolter, Paul Hebert","doi":"10.1002/edn3.70125","DOIUrl":null,"url":null,"abstract":"<p>Comprehensive, curated, and current DNA barcode reference databases are essential for both the identification of single specimens and for the interpretation of metabarcoding data. In the case of plants, nuclear (ITS) and plastid (rbcL, matK) markers are commonly used together. Because the plastid regions are segments of protein-coding genes, their alignment and analysis are usually straightforward. By contrast, the assembly and validation of ITS records is considerably more difficult for two reasons: the prevalence of indels and intraindividual sequence variation. This complexity has provoked the development of several workflows to support the curation of reference databases for the internal transcribed spacer (ITS) region for plant barcoding. However, the pipelines used to create these databases lack functionalities which are essential to ensure a solid post-analytical validation. This paper presents a new workflow to address these shortcomings, with the goal of enhancing the reliability and accuracy of plant barcoding studies. We furthermore demonstrate that clustering of reference databases results in a substantial drop in the fraction of queries that gain a correct species-level assignment. By contrast, setting an acceptance threshold for identifications, based on the distance between query and match, leads to a meaningful reduction of error rates in incomplete reference databases.</p>","PeriodicalId":52828,"journal":{"name":"Environmental DNA","volume":"7 3","pages":""},"PeriodicalIF":6.2000,"publicationDate":"2025-06-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/edn3.70125","citationCount":"0","resultStr":"{\"title\":\"Automating the Curation of DNA Barcode Databases for Vascular Plants\",\"authors\":\"Andreas Kolter, Paul Hebert\",\"doi\":\"10.1002/edn3.70125\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Comprehensive, curated, and current DNA barcode reference databases are essential for both the identification of single specimens and for the interpretation of metabarcoding data. In the case of plants, nuclear (ITS) and plastid (rbcL, matK) markers are commonly used together. Because the plastid regions are segments of protein-coding genes, their alignment and analysis are usually straightforward. By contrast, the assembly and validation of ITS records is considerably more difficult for two reasons: the prevalence of indels and intraindividual sequence variation. This complexity has provoked the development of several workflows to support the curation of reference databases for the internal transcribed spacer (ITS) region for plant barcoding. However, the pipelines used to create these databases lack functionalities which are essential to ensure a solid post-analytical validation. This paper presents a new workflow to address these shortcomings, with the goal of enhancing the reliability and accuracy of plant barcoding studies. We furthermore demonstrate that clustering of reference databases results in a substantial drop in the fraction of queries that gain a correct species-level assignment. By contrast, setting an acceptance threshold for identifications, based on the distance between query and match, leads to a meaningful reduction of error rates in incomplete reference databases.</p>\",\"PeriodicalId\":52828,\"journal\":{\"name\":\"Environmental DNA\",\"volume\":\"7 3\",\"pages\":\"\"},\"PeriodicalIF\":6.2000,\"publicationDate\":\"2025-06-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/edn3.70125\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Environmental DNA\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/edn3.70125\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Agricultural and Biological Sciences\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Environmental DNA","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/edn3.70125","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Agricultural and Biological Sciences","Score":null,"Total":0}
Automating the Curation of DNA Barcode Databases for Vascular Plants
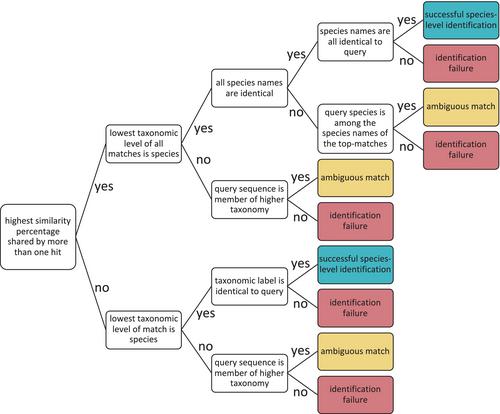
Comprehensive, curated, and current DNA barcode reference databases are essential for both the identification of single specimens and for the interpretation of metabarcoding data. In the case of plants, nuclear (ITS) and plastid (rbcL, matK) markers are commonly used together. Because the plastid regions are segments of protein-coding genes, their alignment and analysis are usually straightforward. By contrast, the assembly and validation of ITS records is considerably more difficult for two reasons: the prevalence of indels and intraindividual sequence variation. This complexity has provoked the development of several workflows to support the curation of reference databases for the internal transcribed spacer (ITS) region for plant barcoding. However, the pipelines used to create these databases lack functionalities which are essential to ensure a solid post-analytical validation. This paper presents a new workflow to address these shortcomings, with the goal of enhancing the reliability and accuracy of plant barcoding studies. We furthermore demonstrate that clustering of reference databases results in a substantial drop in the fraction of queries that gain a correct species-level assignment. By contrast, setting an acceptance threshold for identifications, based on the distance between query and match, leads to a meaningful reduction of error rates in incomplete reference databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


