Mathilde Girard, Léa Vandamme, Bastien Cazaux, Antoine Limasset
{"title":"OReO:为实际压缩优化读顺序。","authors":"Mathilde Girard, Léa Vandamme, Bastien Cazaux, Antoine Limasset","doi":"10.1093/bioadv/vbaf128","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Recent advances in high-throughput and third-generation sequencing technologies have created significant challenges in storing and managing the rapidly growing volume of read datasets. Although more than 50 specialized compression tools have been developed, employing methods such as reference-based approaches, customized generic compressors, and read reordering, many users still rely on common generic compressors (e.g. gzip, zstd, xz) for convenience, portability, and reliability, despite their low compression ratios. Here, we introduce Optimizing Read Order (OReO), a simple read-reordering framework that achieves high compression performance without requiring specialized software for decompression. By grouping overlapping reads together before applying generic compressors, OReO exploits inherent redundancies in sequencing data and achieves compression ratios on par with state-of-the-art tools. Moreover, because it relies only on standard decompressors, OReO avoids the need for dedicated installations and maintenance, removing a key barrier to practical adoption.</p><p><strong>Results: </strong>We evaluated OReO on both Oxford Nanopore Technologies (ONT) and HiFi genomic and metagenomic datasets of varying sizes and complexities. Our results demonstrate that OReO provides substantial compression gains with comparable resource usage and outperforms dedicated methods in decompression speed. We propose that future compression strategies should focus on reordering as a means to let generic compression tools fully exploit data redundancy, offering an efficient, sustainable, and user-friendly solution to the growing challenges of sequencing data storage.</p><p><strong>Availability and implementation: </strong>The OReO code is open source and available at github.com/girunivlille/oreo.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf128"},"PeriodicalIF":2.8000,"publicationDate":"2025-06-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12185860/pdf/","citationCount":"0","resultStr":"{\"title\":\"OReO: optimizing read order for practical compression.\",\"authors\":\"Mathilde Girard, Léa Vandamme, Bastien Cazaux, Antoine Limasset\",\"doi\":\"10.1093/bioadv/vbaf128\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Recent advances in high-throughput and third-generation sequencing technologies have created significant challenges in storing and managing the rapidly growing volume of read datasets. Although more than 50 specialized compression tools have been developed, employing methods such as reference-based approaches, customized generic compressors, and read reordering, many users still rely on common generic compressors (e.g. gzip, zstd, xz) for convenience, portability, and reliability, despite their low compression ratios. Here, we introduce Optimizing Read Order (OReO), a simple read-reordering framework that achieves high compression performance without requiring specialized software for decompression. By grouping overlapping reads together before applying generic compressors, OReO exploits inherent redundancies in sequencing data and achieves compression ratios on par with state-of-the-art tools. Moreover, because it relies only on standard decompressors, OReO avoids the need for dedicated installations and maintenance, removing a key barrier to practical adoption.</p><p><strong>Results: </strong>We evaluated OReO on both Oxford Nanopore Technologies (ONT) and HiFi genomic and metagenomic datasets of varying sizes and complexities. Our results demonstrate that OReO provides substantial compression gains with comparable resource usage and outperforms dedicated methods in decompression speed. We propose that future compression strategies should focus on reordering as a means to let generic compression tools fully exploit data redundancy, offering an efficient, sustainable, and user-friendly solution to the growing challenges of sequencing data storage.</p><p><strong>Availability and implementation: </strong>The OReO code is open source and available at github.com/girunivlille/oreo.</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"5 1\",\"pages\":\"vbaf128\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-06-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12185860/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbaf128\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf128","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
OReO: optimizing read order for practical compression.
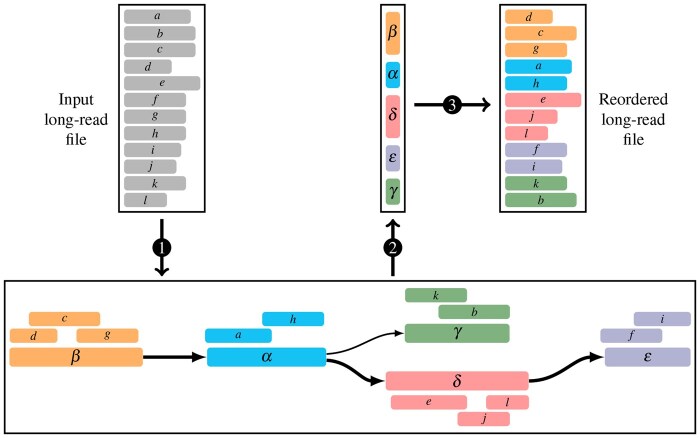
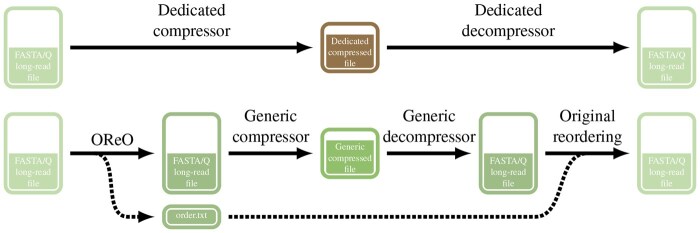
Motivation: Recent advances in high-throughput and third-generation sequencing technologies have created significant challenges in storing and managing the rapidly growing volume of read datasets. Although more than 50 specialized compression tools have been developed, employing methods such as reference-based approaches, customized generic compressors, and read reordering, many users still rely on common generic compressors (e.g. gzip, zstd, xz) for convenience, portability, and reliability, despite their low compression ratios. Here, we introduce Optimizing Read Order (OReO), a simple read-reordering framework that achieves high compression performance without requiring specialized software for decompression. By grouping overlapping reads together before applying generic compressors, OReO exploits inherent redundancies in sequencing data and achieves compression ratios on par with state-of-the-art tools. Moreover, because it relies only on standard decompressors, OReO avoids the need for dedicated installations and maintenance, removing a key barrier to practical adoption.
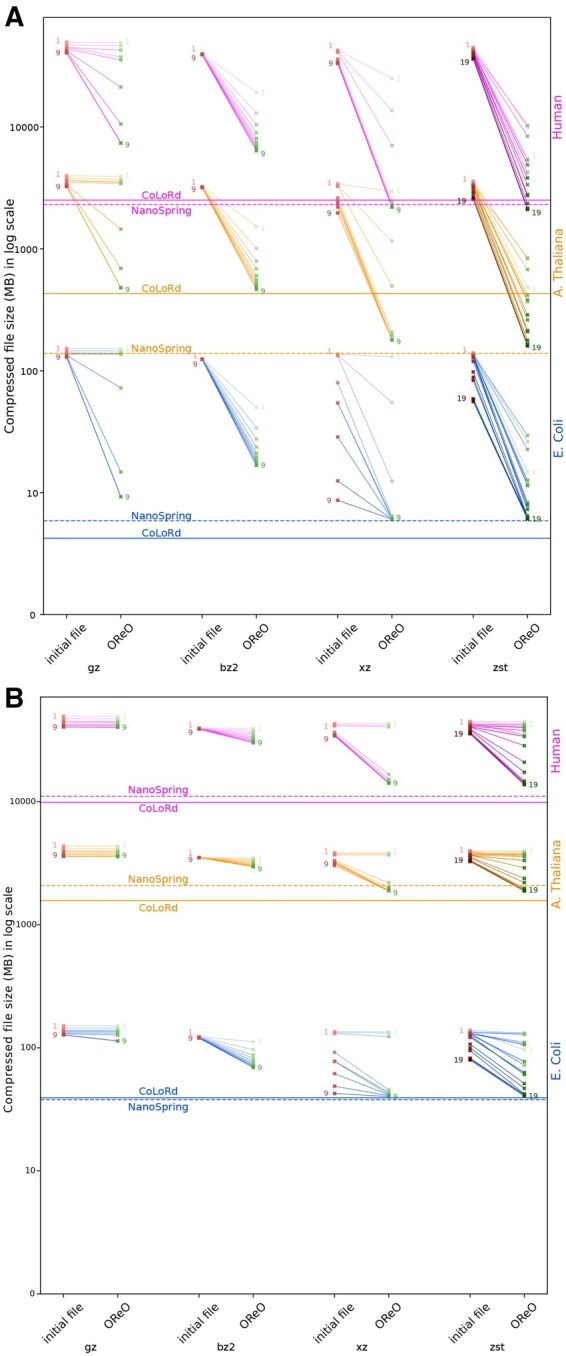
Results: We evaluated OReO on both Oxford Nanopore Technologies (ONT) and HiFi genomic and metagenomic datasets of varying sizes and complexities. Our results demonstrate that OReO provides substantial compression gains with comparable resource usage and outperforms dedicated methods in decompression speed. We propose that future compression strategies should focus on reordering as a means to let generic compression tools fully exploit data redundancy, offering an efficient, sustainable, and user-friendly solution to the growing challenges of sequencing data storage.
Availability and implementation: The OReO code is open source and available at github.com/girunivlille/oreo.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


