GLST-Net:用于骨骼动作识别的全局和局部时空特征融合网络
IF 3.1
4区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
Journal of Visual Communication and Image Representation
Pub Date : 2025-06-23
DOI:10.1016/j.jvcir.2025.104515
引用次数: 0
摘要
图卷积网络(GCN)在基于骨架的动作识别中得到了广泛的应用。然而,GCNs通常基于局部图结构进行操作,这限制了它们识别和处理关节之间复杂的远程关系的能力。提出的GLST-Net包括三个主要模块:全局-局部双流特征提取(GLDE)模块、多尺度时间差异建模(MTDM)模块和时间特征提取(TFE)模块。GLDE旨在捕获整个运动过程中的全局和局部特征信息,并动态地将这两种类型的特征结合起来。此外,由于运动是由连续帧之间观察到的变化来定义的,MTDM通过计算多个时间尺度的差异来提取帧间的差异信息,从而增强了模型的时间建模能力。最后,TFE有效增强了模型提取时间特征的能力。在具有挑战性的NTU-RGB+D和UAV-Human数据集上进行的大量实验证明了该方法的有效性和优越性。本文章由计算机程序翻译,如有差异,请以英文原文为准。
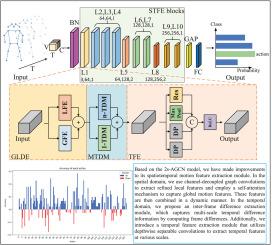
GLST-Net: Global and local spatio-temporal feature fusion network for skeleton-based action recognition
The Graph Convolutional Network (GCN) has been widely applied in skeleton-based action recognition. However, GCNs typically operate based on local graph structures, which limits their ability to recognize and process complex long-range relationships between joints. The proposed GLST-Net consists of three main modules: the Global–Local Dual-Stream Feature Extraction (GLDE) module, the Multi-Scale Temporal Difference Modeling (MTDM) module, and the Temporal Feature Extraction (TFE) module. The GLDE is designed to capture both global and local feature information throughout the motion process and dynamically combine these two types of features. Additionally, since motion is defined by the changes observed between consecutive frames, MTDM extracts inter-frame difference information by calculating differences across multiple time scales, thereby enhancing the model’s temporal modeling capability. Finally, TFE effectively strengthens the model’s ability to extract temporal features. Extensive experiments conducted on the challenging NTU-RGB+D and UAV-Human datasets demonstrate the effectiveness and superiority of the proposed method.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Journal of Visual Communication and Image Representation
工程技术-计算机:软件工程
CiteScore
5.40
自引率
11.50%
发文量
188
审稿时长
9.9 months
期刊介绍:
The Journal of Visual Communication and Image Representation publishes papers on state-of-the-art visual communication and image representation, with emphasis on novel technologies and theoretical work in this multidisciplinary area of pure and applied research. The field of visual communication and image representation is considered in its broadest sense and covers both digital and analog aspects as well as processing and communication in biological visual systems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


