{"title":"TICTAC:靶向照明临床试验分析与化学信息学。","authors":"Jeremiah I Abok, Jeremy S Edwards, Jeremy J Yang","doi":"10.3389/fbinf.2025.1579865","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Identifying disease-target associations is a pivotal step in drug discovery, offering insights that guide the development and optimization of therapeutic interventions. Clinical trial data serves as a valuable source for inferring these associations. However, issues such as inconsistent data quality and limited interpretability pose significant challenges. To overcome these limitations, an integrated approach is required that consolidates evidence from diverse data sources to support the effective prioritization of biological targets for further research.</p><p><strong>Methods: </strong>We developed a comprehensive data integration and visualization pipeline to infer and evaluate associations between diseases and known and potential drug targets. This pipeline integrates clinical trial data with standardized metadata, providing an analytical workflow that enables the exploration of diseases linked to specific drug targets as well as facilitating the discovery of drug targets associated with specific diseases. The pipeline employs robust aggregation techniques to consolidate multivariate evidence from multiple studies, leveraging harmonized datasets to ensure consistency and reliability. Disease-target associations are systematically ranked and filtered using a rational scoring framework that assigns confidence scores derived from aggregated statistical metrics.</p><p><strong>Results: </strong>Our pipeline evaluates disease-target associations by linking protein-coding genes to diseases and incorporates a confidence assessment method based on aggregated evidence. Metrics such as meanRank scores are employed to prioritize associations, enabling researchers to focus on the most promising hypotheses. This systematic approach streamlines the identification and prioritization of biological targets, enhancing hypothesis generation and evidence-based decision-making.</p><p><strong>Discussion: </strong>This innovative pipeline provides a scalable solution for hypothesis generation, scoring, and ranking in drug discovery. As an open-source tool, it is equipped with publicly available datasets and designed for ease of use by researchers. The platform empowers scientists to make data-driven decisions in the prioritization of biological targets, facilitating the discovery of novel therapeutic opportunities.</p>","PeriodicalId":73066,"journal":{"name":"Frontiers in bioinformatics","volume":"5 ","pages":"1579865"},"PeriodicalIF":3.9000,"publicationDate":"2025-06-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12183303/pdf/","citationCount":"0","resultStr":"{\"title\":\"TICTAC: target illumination clinical trial analytics with cheminformatics.\",\"authors\":\"Jeremiah I Abok, Jeremy S Edwards, Jeremy J Yang\",\"doi\":\"10.3389/fbinf.2025.1579865\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Identifying disease-target associations is a pivotal step in drug discovery, offering insights that guide the development and optimization of therapeutic interventions. Clinical trial data serves as a valuable source for inferring these associations. However, issues such as inconsistent data quality and limited interpretability pose significant challenges. To overcome these limitations, an integrated approach is required that consolidates evidence from diverse data sources to support the effective prioritization of biological targets for further research.</p><p><strong>Methods: </strong>We developed a comprehensive data integration and visualization pipeline to infer and evaluate associations between diseases and known and potential drug targets. This pipeline integrates clinical trial data with standardized metadata, providing an analytical workflow that enables the exploration of diseases linked to specific drug targets as well as facilitating the discovery of drug targets associated with specific diseases. The pipeline employs robust aggregation techniques to consolidate multivariate evidence from multiple studies, leveraging harmonized datasets to ensure consistency and reliability. Disease-target associations are systematically ranked and filtered using a rational scoring framework that assigns confidence scores derived from aggregated statistical metrics.</p><p><strong>Results: </strong>Our pipeline evaluates disease-target associations by linking protein-coding genes to diseases and incorporates a confidence assessment method based on aggregated evidence. Metrics such as meanRank scores are employed to prioritize associations, enabling researchers to focus on the most promising hypotheses. This systematic approach streamlines the identification and prioritization of biological targets, enhancing hypothesis generation and evidence-based decision-making.</p><p><strong>Discussion: </strong>This innovative pipeline provides a scalable solution for hypothesis generation, scoring, and ranking in drug discovery. As an open-source tool, it is equipped with publicly available datasets and designed for ease of use by researchers. The platform empowers scientists to make data-driven decisions in the prioritization of biological targets, facilitating the discovery of novel therapeutic opportunities.</p>\",\"PeriodicalId\":73066,\"journal\":{\"name\":\"Frontiers in bioinformatics\",\"volume\":\"5 \",\"pages\":\"1579865\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2025-06-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12183303/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fbinf.2025.1579865\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fbinf.2025.1579865","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
TICTAC: target illumination clinical trial analytics with cheminformatics.
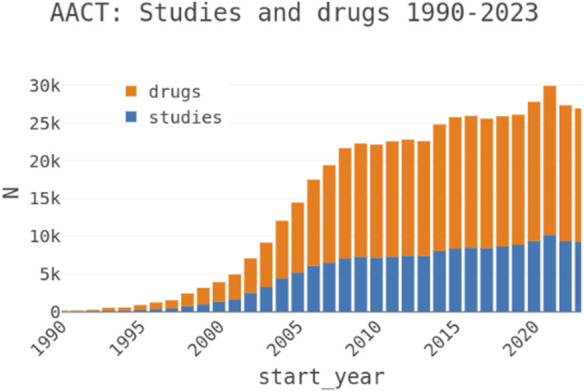
Introduction: Identifying disease-target associations is a pivotal step in drug discovery, offering insights that guide the development and optimization of therapeutic interventions. Clinical trial data serves as a valuable source for inferring these associations. However, issues such as inconsistent data quality and limited interpretability pose significant challenges. To overcome these limitations, an integrated approach is required that consolidates evidence from diverse data sources to support the effective prioritization of biological targets for further research.
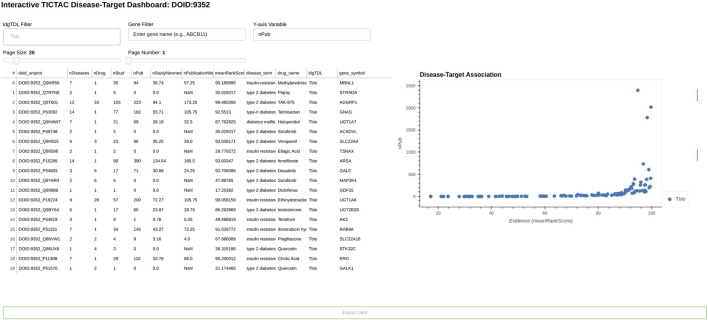
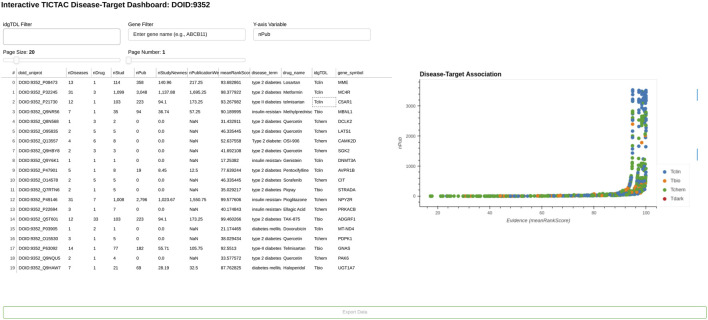
Methods: We developed a comprehensive data integration and visualization pipeline to infer and evaluate associations between diseases and known and potential drug targets. This pipeline integrates clinical trial data with standardized metadata, providing an analytical workflow that enables the exploration of diseases linked to specific drug targets as well as facilitating the discovery of drug targets associated with specific diseases. The pipeline employs robust aggregation techniques to consolidate multivariate evidence from multiple studies, leveraging harmonized datasets to ensure consistency and reliability. Disease-target associations are systematically ranked and filtered using a rational scoring framework that assigns confidence scores derived from aggregated statistical metrics.
Results: Our pipeline evaluates disease-target associations by linking protein-coding genes to diseases and incorporates a confidence assessment method based on aggregated evidence. Metrics such as meanRank scores are employed to prioritize associations, enabling researchers to focus on the most promising hypotheses. This systematic approach streamlines the identification and prioritization of biological targets, enhancing hypothesis generation and evidence-based decision-making.
Discussion: This innovative pipeline provides a scalable solution for hypothesis generation, scoring, and ranking in drug discovery. As an open-source tool, it is equipped with publicly available datasets and designed for ease of use by researchers. The platform empowers scientists to make data-driven decisions in the prioritization of biological targets, facilitating the discovery of novel therapeutic opportunities.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


