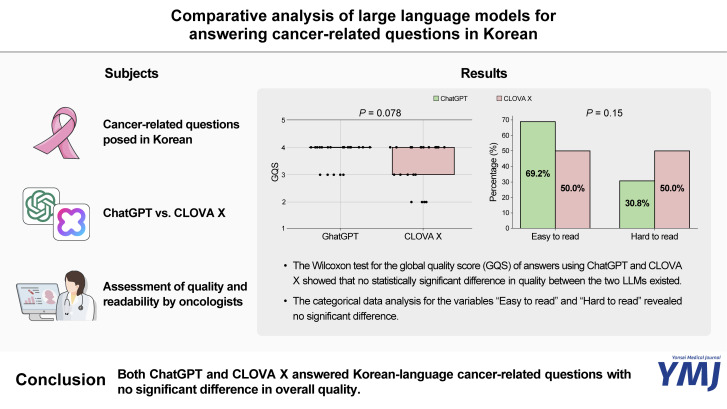
{"title":"用韩语回答癌症相关问题的大型语言模型比较分析。","authors":"Hyun Chang, Jin-Woo Jung, Yongho Kim","doi":"10.3349/ymj.2024.0200","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Large language models (LLMs) have shown potential in medicine, transforming patient education, clinical decision support, and medical research. However, the effectiveness of LLMs in providing accurate medical information, particularly in non-English languages, remains underexplored. This study aimed to compare the quality of responses generated by ChatGPT and Naver's CLOVA X to cancer-related questions posed in Korean.</p><p><strong>Materials and methods: </strong>The study involved selecting cancer-related questions from the National Cancer Institute and Korean National Cancer Information Center websites. Responses were generated using ChatGPT and CLOVA X, and three oncologists assessed their quality using the Global Quality Score (GQS). The readability of the responses generated by ChatGPT and CLOVA X was calculated using KReaD, an artificial intelligence-based tool designed to objectively assess the complexity of Korean texts and reader comprehension.</p><p><strong>Results: </strong>The Wilcoxon test for the GQS score of answers using ChatGPT and CLOVA X showed that there is no statistically significant difference in quality between the two LLMs (<i>p</i>>0.05). The chi-square statistic for the variables \"Good rating\" and \"Poor rating\" showed no significant difference in the quality of responses between the two LLMs (<i>p</i>>0.05). KReaD scores were higher for CLOVA X than for ChatGPT (<i>p</i>=0.036). The categorical data analysis for the variables \"Easy to read\" and \"Hard to read\" revealed no significant difference (<i>p</i>>0.05).</p><p><strong>Conclusion: </strong>Both ChatGPT and CLOVA X answered Korean-language cancer-related questions with no significant difference in overall quality.</p>","PeriodicalId":23765,"journal":{"name":"Yonsei Medical Journal","volume":"66 7","pages":"405-411"},"PeriodicalIF":2.8000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12206594/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparative Analysis of Large Language Models for Answering Cancer-Related Questions in Korean.\",\"authors\":\"Hyun Chang, Jin-Woo Jung, Yongho Kim\",\"doi\":\"10.3349/ymj.2024.0200\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Large language models (LLMs) have shown potential in medicine, transforming patient education, clinical decision support, and medical research. However, the effectiveness of LLMs in providing accurate medical information, particularly in non-English languages, remains underexplored. This study aimed to compare the quality of responses generated by ChatGPT and Naver's CLOVA X to cancer-related questions posed in Korean.</p><p><strong>Materials and methods: </strong>The study involved selecting cancer-related questions from the National Cancer Institute and Korean National Cancer Information Center websites. Responses were generated using ChatGPT and CLOVA X, and three oncologists assessed their quality using the Global Quality Score (GQS). The readability of the responses generated by ChatGPT and CLOVA X was calculated using KReaD, an artificial intelligence-based tool designed to objectively assess the complexity of Korean texts and reader comprehension.</p><p><strong>Results: </strong>The Wilcoxon test for the GQS score of answers using ChatGPT and CLOVA X showed that there is no statistically significant difference in quality between the two LLMs (<i>p</i>>0.05). The chi-square statistic for the variables \\\"Good rating\\\" and \\\"Poor rating\\\" showed no significant difference in the quality of responses between the two LLMs (<i>p</i>>0.05). KReaD scores were higher for CLOVA X than for ChatGPT (<i>p</i>=0.036). The categorical data analysis for the variables \\\"Easy to read\\\" and \\\"Hard to read\\\" revealed no significant difference (<i>p</i>>0.05).</p><p><strong>Conclusion: </strong>Both ChatGPT and CLOVA X answered Korean-language cancer-related questions with no significant difference in overall quality.</p>\",\"PeriodicalId\":23765,\"journal\":{\"name\":\"Yonsei Medical Journal\",\"volume\":\"66 7\",\"pages\":\"405-411\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12206594/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Yonsei Medical Journal\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3349/ymj.2024.0200\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, GENERAL & INTERNAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Yonsei Medical Journal","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3349/ymj.2024.0200","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
Comparative Analysis of Large Language Models for Answering Cancer-Related Questions in Korean.
Purpose: Large language models (LLMs) have shown potential in medicine, transforming patient education, clinical decision support, and medical research. However, the effectiveness of LLMs in providing accurate medical information, particularly in non-English languages, remains underexplored. This study aimed to compare the quality of responses generated by ChatGPT and Naver's CLOVA X to cancer-related questions posed in Korean.
Materials and methods: The study involved selecting cancer-related questions from the National Cancer Institute and Korean National Cancer Information Center websites. Responses were generated using ChatGPT and CLOVA X, and three oncologists assessed their quality using the Global Quality Score (GQS). The readability of the responses generated by ChatGPT and CLOVA X was calculated using KReaD, an artificial intelligence-based tool designed to objectively assess the complexity of Korean texts and reader comprehension.
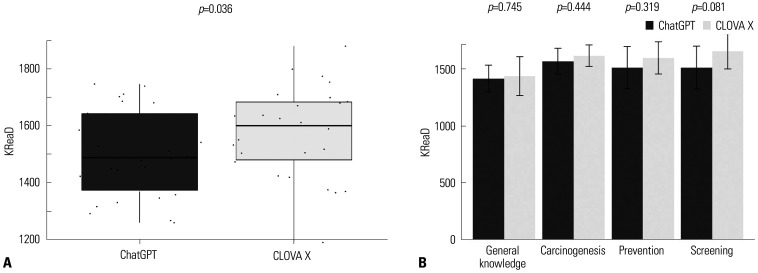
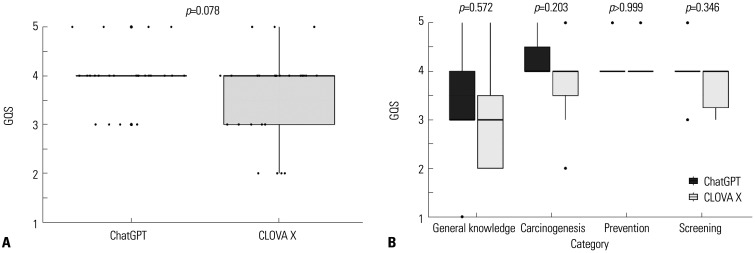
Results: The Wilcoxon test for the GQS score of answers using ChatGPT and CLOVA X showed that there is no statistically significant difference in quality between the two LLMs (p>0.05). The chi-square statistic for the variables "Good rating" and "Poor rating" showed no significant difference in the quality of responses between the two LLMs (p>0.05). KReaD scores were higher for CLOVA X than for ChatGPT (p=0.036). The categorical data analysis for the variables "Easy to read" and "Hard to read" revealed no significant difference (p>0.05).
Conclusion: Both ChatGPT and CLOVA X answered Korean-language cancer-related questions with no significant difference in overall quality.
期刊介绍:
The goal of the Yonsei Medical Journal (YMJ) is to publish high quality manuscripts dedicated to clinical or basic research. Any authors affiliated with an accredited biomedical institution may submit manuscripts of original articles, review articles, case reports, brief communications, and letters to the Editor.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


