{"title":"主题-情感混合网络在可解释文档聚类中的应用:一个概率多维相似度分析","authors":"Marco Ortu","doi":"10.1002/asmb.70024","DOIUrl":null,"url":null,"abstract":"<p>This study introduces a statistical methodology for document clustering that integrates multiple dimensions of textual similarity through network topology analysis. The proposed methodology, which we call Multi-dimensional Similarity Network Analysis (MSNA), extends traditional document-clustering approaches by combining semantic embeddings, topic probability distributions, and emotional probability distribution into a unified similarity measure. We formalize this through a weighted combination of Jensen-Shannon divergences across different probability spaces, creating a comprehensive similarity network. The clustering is achieved through a community detection algorithm that optimizes a multi-objective modularity function, accounting for the different similarity dimensions. We prove the statistical consistency of our approach and derive bounds for the clustering performance under mild regularity conditions. The methodology is validated on a large-scale data set of Airbnb reviews <span></span><math>\n <semantics>\n <mrow>\n <mo>(</mo>\n <mi>n</mi>\n <mo>=</mo>\n <mn>114</mn>\n <mo>,</mo>\n <mn>000</mn>\n <mo>)</mo>\n </mrow>\n <annotation>$$ \\left(n=114,000\\right) $$</annotation>\n </semantics></math> from Sardinia, Italy, containing text content, topic distributions, and emotional features. Results show significant improvements in both clustering quality (average silhouette score increased) and interpretability compared to traditional single-dimension approaches. From an empirical perspective, the synthetic data validation demonstrates robust performance with topic strength in the range <span></span><math>\n <semantics>\n <mrow>\n <mo>[</mo>\n <mn>0</mn>\n <mo>.</mo>\n <mn>4</mn>\n <mo>,</mo>\n <mn>1</mn>\n <mo>.</mo>\n <mn>0</mn>\n <mo>]</mo>\n </mrow>\n <annotation>$$ \\left[0.4,1.0\\right] $$</annotation>\n </semantics></math> and emotion strength in <span></span><math>\n <semantics>\n <mrow>\n <mo>[</mo>\n <mn>0</mn>\n <mo>.</mo>\n <mn>2</mn>\n <mo>,</mo>\n <mn>1</mn>\n <mo>.</mo>\n <mn>0</mn>\n <mo>]</mo>\n </mrow>\n <annotation>$$ \\left[0.2,1.0\\right] $$</annotation>\n </semantics></math>, achieving mean Adjusted Rand Index scores of 0.44. The application to real-world data identifies five distinct clusters through PROCSIMA (PRObabilistic Clustering SIMilarity Analysis), with subsequent SMARTS (SeMantic Analysis of Review Topics and Sentiment) analysis revealing interpretable community structures within each cluster. The framework's ability to simultaneously capture text's semantic, thematic, and emotional aspects makes it particularly valuable for applications in customer experience analysis and service quality monitoring.</p>","PeriodicalId":55495,"journal":{"name":"Applied Stochastic Models in Business and Industry","volume":"41 4","pages":""},"PeriodicalIF":1.5000,"publicationDate":"2025-06-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/asmb.70024","citationCount":"0","resultStr":"{\"title\":\"Topic-Sentiment Hybrid Networks for Explainable Document Clustering: A Probabilistic Multi-Dimensional Similarity Analysis\",\"authors\":\"Marco Ortu\",\"doi\":\"10.1002/asmb.70024\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This study introduces a statistical methodology for document clustering that integrates multiple dimensions of textual similarity through network topology analysis. The proposed methodology, which we call Multi-dimensional Similarity Network Analysis (MSNA), extends traditional document-clustering approaches by combining semantic embeddings, topic probability distributions, and emotional probability distribution into a unified similarity measure. We formalize this through a weighted combination of Jensen-Shannon divergences across different probability spaces, creating a comprehensive similarity network. The clustering is achieved through a community detection algorithm that optimizes a multi-objective modularity function, accounting for the different similarity dimensions. We prove the statistical consistency of our approach and derive bounds for the clustering performance under mild regularity conditions. The methodology is validated on a large-scale data set of Airbnb reviews <span></span><math>\\n <semantics>\\n <mrow>\\n <mo>(</mo>\\n <mi>n</mi>\\n <mo>=</mo>\\n <mn>114</mn>\\n <mo>,</mo>\\n <mn>000</mn>\\n <mo>)</mo>\\n </mrow>\\n <annotation>$$ \\\\left(n=114,000\\\\right) $$</annotation>\\n </semantics></math> from Sardinia, Italy, containing text content, topic distributions, and emotional features. Results show significant improvements in both clustering quality (average silhouette score increased) and interpretability compared to traditional single-dimension approaches. From an empirical perspective, the synthetic data validation demonstrates robust performance with topic strength in the range <span></span><math>\\n <semantics>\\n <mrow>\\n <mo>[</mo>\\n <mn>0</mn>\\n <mo>.</mo>\\n <mn>4</mn>\\n <mo>,</mo>\\n <mn>1</mn>\\n <mo>.</mo>\\n <mn>0</mn>\\n <mo>]</mo>\\n </mrow>\\n <annotation>$$ \\\\left[0.4,1.0\\\\right] $$</annotation>\\n </semantics></math> and emotion strength in <span></span><math>\\n <semantics>\\n <mrow>\\n <mo>[</mo>\\n <mn>0</mn>\\n <mo>.</mo>\\n <mn>2</mn>\\n <mo>,</mo>\\n <mn>1</mn>\\n <mo>.</mo>\\n <mn>0</mn>\\n <mo>]</mo>\\n </mrow>\\n <annotation>$$ \\\\left[0.2,1.0\\\\right] $$</annotation>\\n </semantics></math>, achieving mean Adjusted Rand Index scores of 0.44. The application to real-world data identifies five distinct clusters through PROCSIMA (PRObabilistic Clustering SIMilarity Analysis), with subsequent SMARTS (SeMantic Analysis of Review Topics and Sentiment) analysis revealing interpretable community structures within each cluster. The framework's ability to simultaneously capture text's semantic, thematic, and emotional aspects makes it particularly valuable for applications in customer experience analysis and service quality monitoring.</p>\",\"PeriodicalId\":55495,\"journal\":{\"name\":\"Applied Stochastic Models in Business and Industry\",\"volume\":\"41 4\",\"pages\":\"\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2025-06-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/asmb.70024\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applied Stochastic Models in Business and Industry\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/asmb.70024\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied Stochastic Models in Business and Industry","FirstCategoryId":"100","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/asmb.70024","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Topic-Sentiment Hybrid Networks for Explainable Document Clustering: A Probabilistic Multi-Dimensional Similarity Analysis
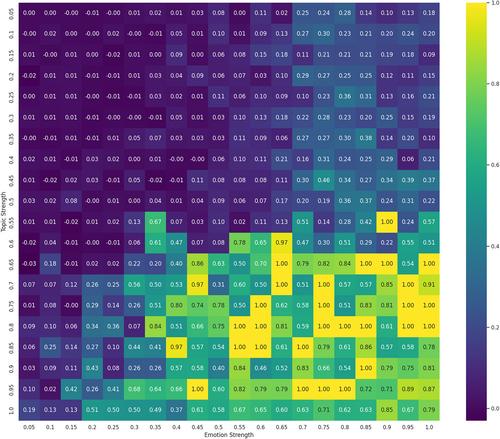
This study introduces a statistical methodology for document clustering that integrates multiple dimensions of textual similarity through network topology analysis. The proposed methodology, which we call Multi-dimensional Similarity Network Analysis (MSNA), extends traditional document-clustering approaches by combining semantic embeddings, topic probability distributions, and emotional probability distribution into a unified similarity measure. We formalize this through a weighted combination of Jensen-Shannon divergences across different probability spaces, creating a comprehensive similarity network. The clustering is achieved through a community detection algorithm that optimizes a multi-objective modularity function, accounting for the different similarity dimensions. We prove the statistical consistency of our approach and derive bounds for the clustering performance under mild regularity conditions. The methodology is validated on a large-scale data set of Airbnb reviews from Sardinia, Italy, containing text content, topic distributions, and emotional features. Results show significant improvements in both clustering quality (average silhouette score increased) and interpretability compared to traditional single-dimension approaches. From an empirical perspective, the synthetic data validation demonstrates robust performance with topic strength in the range and emotion strength in , achieving mean Adjusted Rand Index scores of 0.44. The application to real-world data identifies five distinct clusters through PROCSIMA (PRObabilistic Clustering SIMilarity Analysis), with subsequent SMARTS (SeMantic Analysis of Review Topics and Sentiment) analysis revealing interpretable community structures within each cluster. The framework's ability to simultaneously capture text's semantic, thematic, and emotional aspects makes it particularly valuable for applications in customer experience analysis and service quality monitoring.
期刊介绍:
ASMBI - Applied Stochastic Models in Business and Industry (formerly Applied Stochastic Models and Data Analysis) was first published in 1985, publishing contributions in the interface between stochastic modelling, data analysis and their applications in business, finance, insurance, management and production. In 2007 ASMBI became the official journal of the International Society for Business and Industrial Statistics (www.isbis.org). The main objective is to publish papers, both technical and practical, presenting new results which solve real-life problems or have great potential in doing so. Mathematical rigour, innovative stochastic modelling and sound applications are the key ingredients of papers to be published, after a very selective review process.
The journal is very open to new ideas, like Data Science and Big Data stemming from problems in business and industry or uncertainty quantification in engineering, as well as more traditional ones, like reliability, quality control, design of experiments, managerial processes, supply chains and inventories, insurance, econometrics, financial modelling (provided the papers are related to real problems). The journal is interested also in papers addressing the effects of business and industrial decisions on the environment, healthcare, social life. State-of-the art computational methods are very welcome as well, when combined with sound applications and innovative models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


