{"title":"更快的计算左有界最短唯一子串。","authors":"Larissa L M Aguiar, Felipe A Louza","doi":"10.1186/s13015-025-00287-5","DOIUrl":null,"url":null,"abstract":"<p><p>Finding shortest unique substrings (SUS) is a fundamental problem in string processing with applications in bioinformatics. In this paper, we present an algorithm for solving a variant of the SUS problem, the left-bounded shortest unique substrings (LSUS). This variant is particularly important in applications such as PCR primer design. Our algorithm runs in O(n) time using 2n memory words plus n bytes for an input string of length n. Experimental results with real and artificial datasets show that our algorithm is the fastest alternative in practice, being two times faster (on the average) than related works, while using a similar peak memory footprint.</p>","PeriodicalId":50823,"journal":{"name":"Algorithms for Molecular Biology","volume":"20 1","pages":"11"},"PeriodicalIF":1.7000,"publicationDate":"2025-06-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12181909/pdf/","citationCount":"0","resultStr":"{\"title\":\"Faster computation of left-bounded shortest unique substrings.\",\"authors\":\"Larissa L M Aguiar, Felipe A Louza\",\"doi\":\"10.1186/s13015-025-00287-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Finding shortest unique substrings (SUS) is a fundamental problem in string processing with applications in bioinformatics. In this paper, we present an algorithm for solving a variant of the SUS problem, the left-bounded shortest unique substrings (LSUS). This variant is particularly important in applications such as PCR primer design. Our algorithm runs in O(n) time using 2n memory words plus n bytes for an input string of length n. Experimental results with real and artificial datasets show that our algorithm is the fastest alternative in practice, being two times faster (on the average) than related works, while using a similar peak memory footprint.</p>\",\"PeriodicalId\":50823,\"journal\":{\"name\":\"Algorithms for Molecular Biology\",\"volume\":\"20 1\",\"pages\":\"11\"},\"PeriodicalIF\":1.7000,\"publicationDate\":\"2025-06-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12181909/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Algorithms for Molecular Biology\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13015-025-00287-5\",\"RegionNum\":4,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Algorithms for Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13015-025-00287-5","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
Faster computation of left-bounded shortest unique substrings.
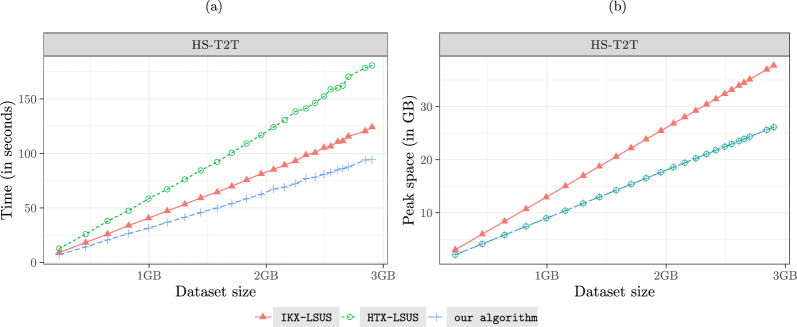
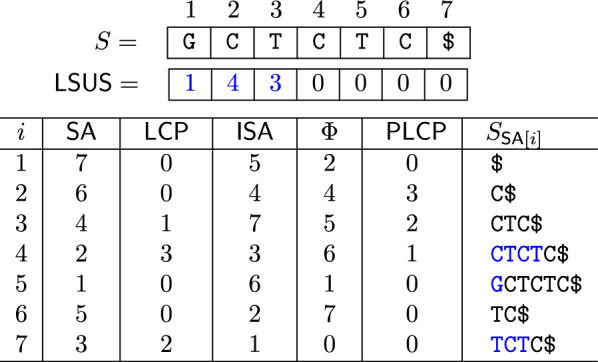
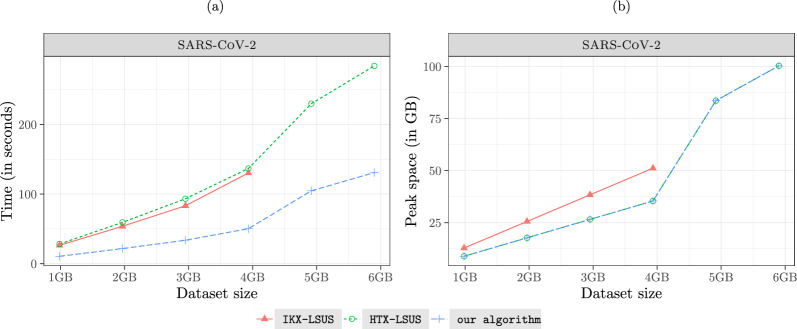
Finding shortest unique substrings (SUS) is a fundamental problem in string processing with applications in bioinformatics. In this paper, we present an algorithm for solving a variant of the SUS problem, the left-bounded shortest unique substrings (LSUS). This variant is particularly important in applications such as PCR primer design. Our algorithm runs in O(n) time using 2n memory words plus n bytes for an input string of length n. Experimental results with real and artificial datasets show that our algorithm is the fastest alternative in practice, being two times faster (on the average) than related works, while using a similar peak memory footprint.
期刊介绍:
Algorithms for Molecular Biology publishes articles on novel algorithms for biological sequence and structure analysis, phylogeny reconstruction, and combinatorial algorithms and machine learning.
Areas of interest include but are not limited to: algorithms for RNA and protein structure analysis, gene prediction and genome analysis, comparative sequence analysis and alignment, phylogeny, gene expression, machine learning, and combinatorial algorithms.
Where appropriate, manuscripts should describe applications to real-world data. However, pure algorithm papers are also welcome if future applications to biological data are to be expected, or if they address complexity or approximation issues of novel computational problems in molecular biology. Articles about novel software tools will be considered for publication if they contain some algorithmically interesting aspects.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


