{"title":"一种机器学习方法预测高血压使用横断面和两年随访数据来自印度东北部阿萨姆邦的健康和人口统计队列。","authors":"Krishnarjun Bora, Natarajaseenivasan Kalimuthusamy, Ananya Jyoti Gogoi, Namita Garh, Manisha Rabidas, Gargi Chanda, Rajshree Das, Prasanta Kumar Borah","doi":"10.25259/IJMR_881_2024","DOIUrl":null,"url":null,"abstract":"<p><p>Background & objectives Hypertension affects a sizable section of the world population and is being recognised as a growing problem. Its prediction using machine learning (ML) algorithms, will add to its control and prevention. The objective of the present investigation was to check the applicability of ML approaches in the prediction and detection of hypertension. Methods We included 53,301 participants at baseline from a health and demographic surveillance system in Dibrugarh, Assam (Dibrugarh-HDSS). We constructed two models, one at baseline and the other after two years of follow-up. Of the total participants (baseline: 29,402; follow up: 4,400), 70 per cent were randomly selected to fit seven popular classification models namely decision tree classifier (DTC), random forest classifier (RFC), support vector machine (SVM), linear discriminant analysis (LDA), logistic regression, Ada-boost classifier, and XG boost classifier. The data from the remaining 30 per cent were used to evaluate the performance of the models. Results In the baseline data, the Ada-boost classifier could identify hypertension with a maximum accuracy score of 87.02 per cent (CI: 86.01-88.03). The maximum area under the curve (AUC) score of 98.37 per cent (CI: 97.36-99.38) was obtained under RFC. For the prediction of risk at two years, the maximum average accuracy score of 77.57 per cent (CI: 76.6-78.54) was achieved under X-G Boost followed by RFC (77.2%, CI: 76.15-78.25) and a maximum AUC of (85.82%, CI: 84.88-86.76) was obtained under RFC. Interpretation & conclusions In both the identification and prediction of hypertension, RFC was found to be better than the other classifiers. 'Waist circumference' followed by 'body mass index' (BMI) were found to have maximum relative importance in the identification of hypertension, while in the case of two-year risk prediction, the baseline 'systolic blood pressure' (SBP), diastolic blood pressure (DBP), and 'BMI' had the maximum relative importance. The findings revealed the potential of predictive models in accurately identifying high-risk individuals, enabling timely interventions, and optimising clinical decision-making.</p>","PeriodicalId":13349,"journal":{"name":"Indian Journal of Medical Research","volume":"161 4","pages":"394-405"},"PeriodicalIF":2.5000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12178201/pdf/","citationCount":"0","resultStr":"{\"title\":\"A machine learning approach to predict hypertension using cross-sectional & two years follow up data from a health & demographic cohort of Assam, North East India.\",\"authors\":\"Krishnarjun Bora, Natarajaseenivasan Kalimuthusamy, Ananya Jyoti Gogoi, Namita Garh, Manisha Rabidas, Gargi Chanda, Rajshree Das, Prasanta Kumar Borah\",\"doi\":\"10.25259/IJMR_881_2024\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Background & objectives Hypertension affects a sizable section of the world population and is being recognised as a growing problem. Its prediction using machine learning (ML) algorithms, will add to its control and prevention. The objective of the present investigation was to check the applicability of ML approaches in the prediction and detection of hypertension. Methods We included 53,301 participants at baseline from a health and demographic surveillance system in Dibrugarh, Assam (Dibrugarh-HDSS). We constructed two models, one at baseline and the other after two years of follow-up. Of the total participants (baseline: 29,402; follow up: 4,400), 70 per cent were randomly selected to fit seven popular classification models namely decision tree classifier (DTC), random forest classifier (RFC), support vector machine (SVM), linear discriminant analysis (LDA), logistic regression, Ada-boost classifier, and XG boost classifier. The data from the remaining 30 per cent were used to evaluate the performance of the models. Results In the baseline data, the Ada-boost classifier could identify hypertension with a maximum accuracy score of 87.02 per cent (CI: 86.01-88.03). The maximum area under the curve (AUC) score of 98.37 per cent (CI: 97.36-99.38) was obtained under RFC. For the prediction of risk at two years, the maximum average accuracy score of 77.57 per cent (CI: 76.6-78.54) was achieved under X-G Boost followed by RFC (77.2%, CI: 76.15-78.25) and a maximum AUC of (85.82%, CI: 84.88-86.76) was obtained under RFC. Interpretation & conclusions In both the identification and prediction of hypertension, RFC was found to be better than the other classifiers. 'Waist circumference' followed by 'body mass index' (BMI) were found to have maximum relative importance in the identification of hypertension, while in the case of two-year risk prediction, the baseline 'systolic blood pressure' (SBP), diastolic blood pressure (DBP), and 'BMI' had the maximum relative importance. The findings revealed the potential of predictive models in accurately identifying high-risk individuals, enabling timely interventions, and optimising clinical decision-making.</p>\",\"PeriodicalId\":13349,\"journal\":{\"name\":\"Indian Journal of Medical Research\",\"volume\":\"161 4\",\"pages\":\"394-405\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12178201/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Indian Journal of Medical Research\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.25259/IJMR_881_2024\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"IMMUNOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Indian Journal of Medical Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.25259/IJMR_881_2024","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"IMMUNOLOGY","Score":null,"Total":0}
A machine learning approach to predict hypertension using cross-sectional & two years follow up data from a health & demographic cohort of Assam, North East India.
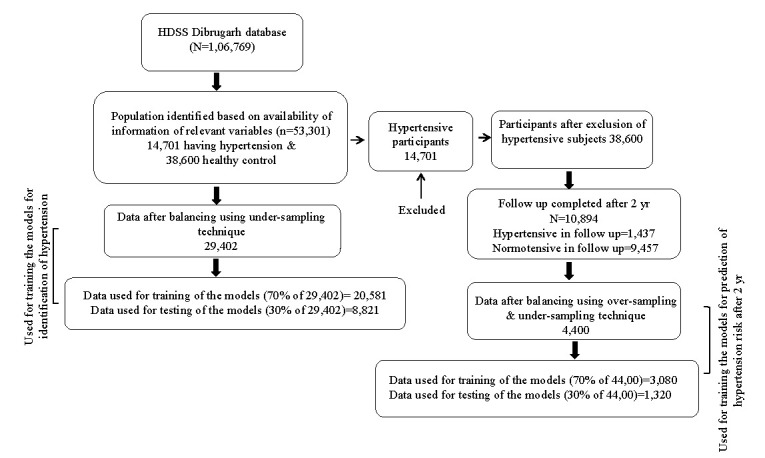
Background & objectives Hypertension affects a sizable section of the world population and is being recognised as a growing problem. Its prediction using machine learning (ML) algorithms, will add to its control and prevention. The objective of the present investigation was to check the applicability of ML approaches in the prediction and detection of hypertension. Methods We included 53,301 participants at baseline from a health and demographic surveillance system in Dibrugarh, Assam (Dibrugarh-HDSS). We constructed two models, one at baseline and the other after two years of follow-up. Of the total participants (baseline: 29,402; follow up: 4,400), 70 per cent were randomly selected to fit seven popular classification models namely decision tree classifier (DTC), random forest classifier (RFC), support vector machine (SVM), linear discriminant analysis (LDA), logistic regression, Ada-boost classifier, and XG boost classifier. The data from the remaining 30 per cent were used to evaluate the performance of the models. Results In the baseline data, the Ada-boost classifier could identify hypertension with a maximum accuracy score of 87.02 per cent (CI: 86.01-88.03). The maximum area under the curve (AUC) score of 98.37 per cent (CI: 97.36-99.38) was obtained under RFC. For the prediction of risk at two years, the maximum average accuracy score of 77.57 per cent (CI: 76.6-78.54) was achieved under X-G Boost followed by RFC (77.2%, CI: 76.15-78.25) and a maximum AUC of (85.82%, CI: 84.88-86.76) was obtained under RFC. Interpretation & conclusions In both the identification and prediction of hypertension, RFC was found to be better than the other classifiers. 'Waist circumference' followed by 'body mass index' (BMI) were found to have maximum relative importance in the identification of hypertension, while in the case of two-year risk prediction, the baseline 'systolic blood pressure' (SBP), diastolic blood pressure (DBP), and 'BMI' had the maximum relative importance. The findings revealed the potential of predictive models in accurately identifying high-risk individuals, enabling timely interventions, and optimising clinical decision-making.
期刊介绍:
The Indian Journal of Medical Research (IJMR) [ISSN 0971-5916] is one of the oldest medical Journals not only in India, but probably in Asia, as it started in the year 1913. The Journal was started as a quarterly (4 issues/year) in 1913 and made bimonthly (6 issues/year) in 1958. It became monthly (12 issues/year) in the year 1964.
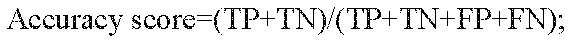
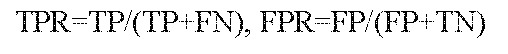

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


