{"title":"医疗保健的可再生生成人工智能评估:临床医生在循环中的方法。","authors":"Leah Livingston, Amber Featherstone-Uwague, Amanda Barry, Kenneth Barretto, Tara Morey, Drahomira Herrmannova, Venkatesh Avula","doi":"10.1093/jamiaopen/ooaf054","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To develop and apply a reproducible methodology for evaluating generative artificial intelligence (AI) powered systems in health care, addressing the gap between theoretical evaluation frameworks and practical implementation guidance.</p><p><strong>Materials and methods: </strong>A 5-dimension evaluation framework was developed to assess query comprehension and response helpfulness, correctness, completeness, and potential clinical harm. The framework was applied to evaluate ClinicalKey AI using queries drawn from user logs, a benchmark dataset, and subject matter expert curated queries. Forty-one board-certified physicians and pharmacists were recruited to independently evaluate query-response pairs. An agreement protocol using the mode and modified Delphi method resolved disagreements in evaluation scores.</p><p><strong>Results: </strong>Of 633 queries, 614 (96.99%) produced evaluable responses, with subject matter experts completing evaluations of 426 query-response pairs. Results demonstrated high rates of response correctness (95.5%) and query comprehension (98.6%), with 94.4% of responses rated as helpful. Two responses (0.47%) received scores indicating potential clinical harm. Pairwise consensus occurred in 60.6% of evaluations, with remaining cases requiring third tie-breaker review.</p><p><strong>Discussion: </strong>The framework demonstrated effectiveness in quantifying performance through comprehensive evaluation dimensions and structured scoring resolution methods. Key strengths included representative query sampling, standardized rating scales, and robust subject matter expert agreement protocols. Challenges emerged in managing subjective assessments of open-ended responses and achieving consensus on potential harm classification.</p><p><strong>Conclusion: </strong>This framework offers a reproducible methodology for evaluating health-care generative AI systems, establishing foundational processes that can inform future efforts while supporting the implementation of generative AI applications in clinical settings.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 3","pages":"ooaf054"},"PeriodicalIF":3.4000,"publicationDate":"2025-06-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12169418/pdf/","citationCount":"0","resultStr":"{\"title\":\"Reproducible generative artificial intelligence evaluation for health care: a clinician-in-the-loop approach.\",\"authors\":\"Leah Livingston, Amber Featherstone-Uwague, Amanda Barry, Kenneth Barretto, Tara Morey, Drahomira Herrmannova, Venkatesh Avula\",\"doi\":\"10.1093/jamiaopen/ooaf054\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>To develop and apply a reproducible methodology for evaluating generative artificial intelligence (AI) powered systems in health care, addressing the gap between theoretical evaluation frameworks and practical implementation guidance.</p><p><strong>Materials and methods: </strong>A 5-dimension evaluation framework was developed to assess query comprehension and response helpfulness, correctness, completeness, and potential clinical harm. The framework was applied to evaluate ClinicalKey AI using queries drawn from user logs, a benchmark dataset, and subject matter expert curated queries. Forty-one board-certified physicians and pharmacists were recruited to independently evaluate query-response pairs. An agreement protocol using the mode and modified Delphi method resolved disagreements in evaluation scores.</p><p><strong>Results: </strong>Of 633 queries, 614 (96.99%) produced evaluable responses, with subject matter experts completing evaluations of 426 query-response pairs. Results demonstrated high rates of response correctness (95.5%) and query comprehension (98.6%), with 94.4% of responses rated as helpful. Two responses (0.47%) received scores indicating potential clinical harm. Pairwise consensus occurred in 60.6% of evaluations, with remaining cases requiring third tie-breaker review.</p><p><strong>Discussion: </strong>The framework demonstrated effectiveness in quantifying performance through comprehensive evaluation dimensions and structured scoring resolution methods. Key strengths included representative query sampling, standardized rating scales, and robust subject matter expert agreement protocols. Challenges emerged in managing subjective assessments of open-ended responses and achieving consensus on potential harm classification.</p><p><strong>Conclusion: </strong>This framework offers a reproducible methodology for evaluating health-care generative AI systems, establishing foundational processes that can inform future efforts while supporting the implementation of generative AI applications in clinical settings.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"8 3\",\"pages\":\"ooaf054\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2025-06-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12169418/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooaf054\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/6/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf054","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Reproducible generative artificial intelligence evaluation for health care: a clinician-in-the-loop approach.
Objectives: To develop and apply a reproducible methodology for evaluating generative artificial intelligence (AI) powered systems in health care, addressing the gap between theoretical evaluation frameworks and practical implementation guidance.
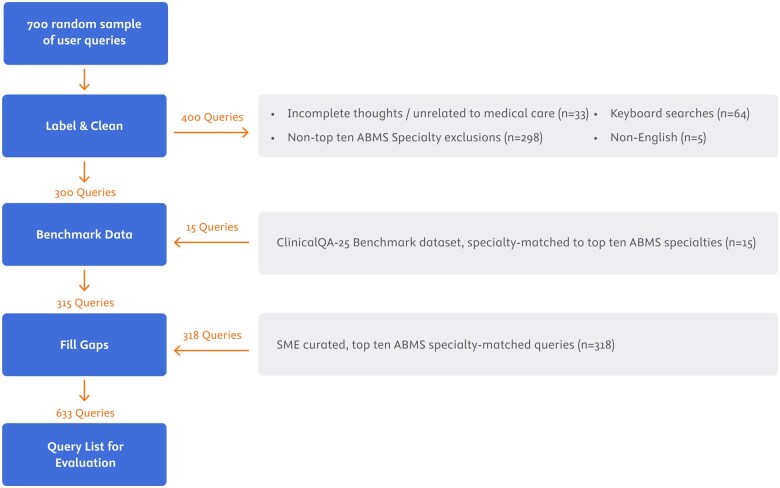
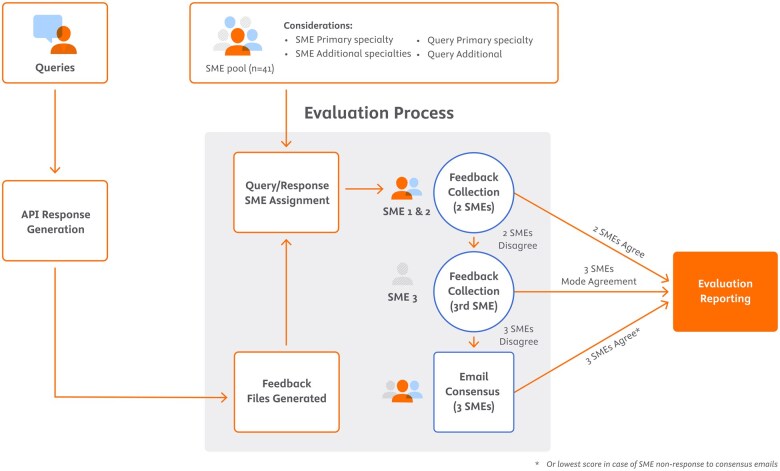
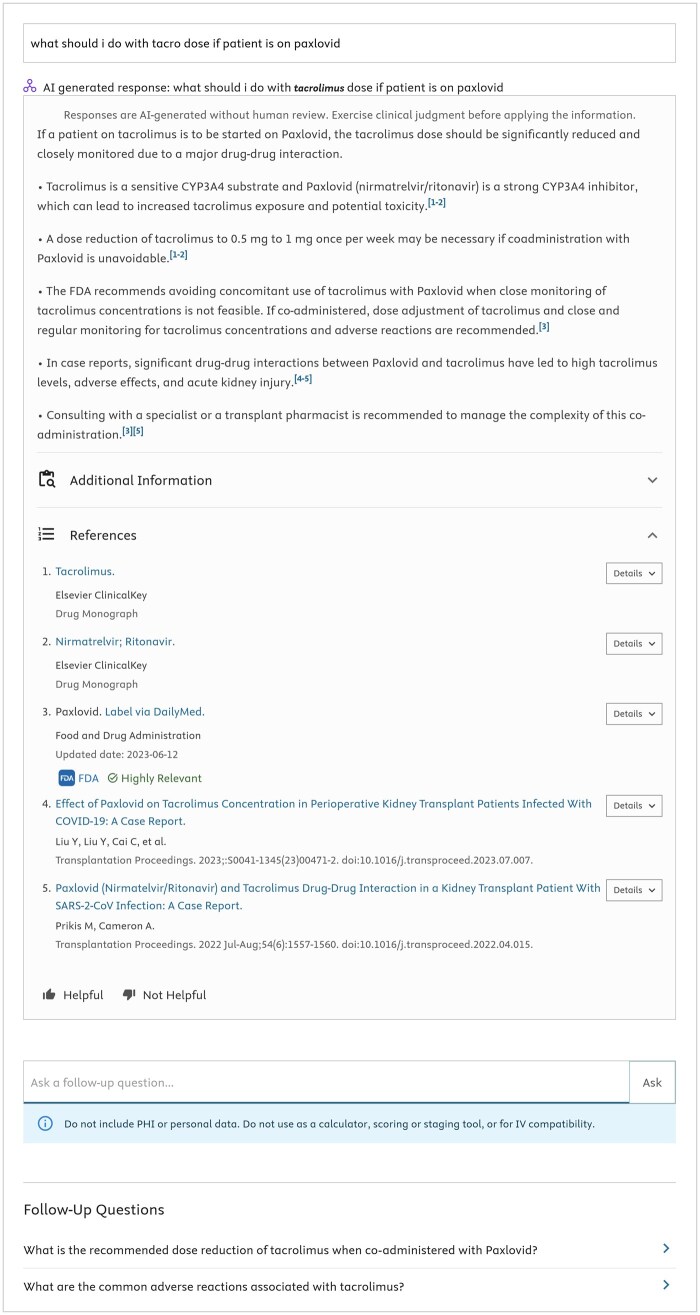
Materials and methods: A 5-dimension evaluation framework was developed to assess query comprehension and response helpfulness, correctness, completeness, and potential clinical harm. The framework was applied to evaluate ClinicalKey AI using queries drawn from user logs, a benchmark dataset, and subject matter expert curated queries. Forty-one board-certified physicians and pharmacists were recruited to independently evaluate query-response pairs. An agreement protocol using the mode and modified Delphi method resolved disagreements in evaluation scores.
Results: Of 633 queries, 614 (96.99%) produced evaluable responses, with subject matter experts completing evaluations of 426 query-response pairs. Results demonstrated high rates of response correctness (95.5%) and query comprehension (98.6%), with 94.4% of responses rated as helpful. Two responses (0.47%) received scores indicating potential clinical harm. Pairwise consensus occurred in 60.6% of evaluations, with remaining cases requiring third tie-breaker review.
Discussion: The framework demonstrated effectiveness in quantifying performance through comprehensive evaluation dimensions and structured scoring resolution methods. Key strengths included representative query sampling, standardized rating scales, and robust subject matter expert agreement protocols. Challenges emerged in managing subjective assessments of open-ended responses and achieving consensus on potential harm classification.
Conclusion: This framework offers a reproducible methodology for evaluating health-care generative AI systems, establishing foundational processes that can inform future efforts while supporting the implementation of generative AI applications in clinical settings.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


