Joe M Bridges, Xiaoqian Jiang, Michael Ige, Oluwatoniloba Toyobo
{"title":"计算机诊断决策支持系统- isabel Pro与ChatGPT-4第二部分。","authors":"Joe M Bridges, Xiaoqian Jiang, Michael Ige, Oluwatoniloba Toyobo","doi":"10.1093/jamiaopen/ooaf048","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Does a Tree-of-Thought prompt and reconsideration of Isabel Pro's differential improve ChatGPT-4's accuracy; does increasing expert panel size improve ChatGPT-4's accuracy; does ChatGPT-4 produce consistent outputs in sequential requests; what is the frequency of fabricated references?</p><p><strong>Materials and methods: </strong>Isabel Pro, a computerized diagnostic decision support system, and ChatGPT-4, a large language model. Using 201 cases from the New England Journal of Medicine, each system produced a differential diagnosis ranked by likelihood. Statistics were Mean Reciprocal Rank, Recall at Rank, Average Rank, Number of Correct Diagnoses, and Rank Improvement. For reproducibility, the study compared the initial expert panel run to each subsequent run, using the r-squared calculation from a scatter plot of each run.</p><p><strong>Results: </strong>ChatGPT-4 improved MRR and Recall at 10 to 0.72 but produced fewer correct diagnoses and lower average rank. Reconsideration of the Isabel Pro differential produced an improvement in Recall at 10 of 11%. The expert panel size of two produced the best result. The reproducibility runs were within 4% on average for Recall at 10, but the scatterplots showed an r-squared ranging from 0.44 to 034, suggesting poor reproducibility. Reference accuracy was 34.8% for citations and 37.8% for DOIs.</p><p><strong>Discussion: </strong>ChatGPT-4 performs well with images and electrocardiography and in administrative practice management, but diagnosis has not proven as promising.</p><p><strong>Conclusions: </strong>As noted above, the results demonstrate concerns for diagnostic accuracy, reproducibility, and reference citation accuracy. Until these issues are resolved, clinical usage for diagnosis will be minimal, if at all.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 3","pages":"ooaf048"},"PeriodicalIF":3.4000,"publicationDate":"2025-06-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12169417/pdf/","citationCount":"0","resultStr":"{\"title\":\"Computerized diagnostic decision support systems-Isabel Pro versus ChatGPT-4 part II.\",\"authors\":\"Joe M Bridges, Xiaoqian Jiang, Michael Ige, Oluwatoniloba Toyobo\",\"doi\":\"10.1093/jamiaopen/ooaf048\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Does a Tree-of-Thought prompt and reconsideration of Isabel Pro's differential improve ChatGPT-4's accuracy; does increasing expert panel size improve ChatGPT-4's accuracy; does ChatGPT-4 produce consistent outputs in sequential requests; what is the frequency of fabricated references?</p><p><strong>Materials and methods: </strong>Isabel Pro, a computerized diagnostic decision support system, and ChatGPT-4, a large language model. Using 201 cases from the New England Journal of Medicine, each system produced a differential diagnosis ranked by likelihood. Statistics were Mean Reciprocal Rank, Recall at Rank, Average Rank, Number of Correct Diagnoses, and Rank Improvement. For reproducibility, the study compared the initial expert panel run to each subsequent run, using the r-squared calculation from a scatter plot of each run.</p><p><strong>Results: </strong>ChatGPT-4 improved MRR and Recall at 10 to 0.72 but produced fewer correct diagnoses and lower average rank. Reconsideration of the Isabel Pro differential produced an improvement in Recall at 10 of 11%. The expert panel size of two produced the best result. The reproducibility runs were within 4% on average for Recall at 10, but the scatterplots showed an r-squared ranging from 0.44 to 034, suggesting poor reproducibility. Reference accuracy was 34.8% for citations and 37.8% for DOIs.</p><p><strong>Discussion: </strong>ChatGPT-4 performs well with images and electrocardiography and in administrative practice management, but diagnosis has not proven as promising.</p><p><strong>Conclusions: </strong>As noted above, the results demonstrate concerns for diagnostic accuracy, reproducibility, and reference citation accuracy. Until these issues are resolved, clinical usage for diagnosis will be minimal, if at all.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"8 3\",\"pages\":\"ooaf048\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2025-06-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12169417/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooaf048\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/6/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf048","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
摘要
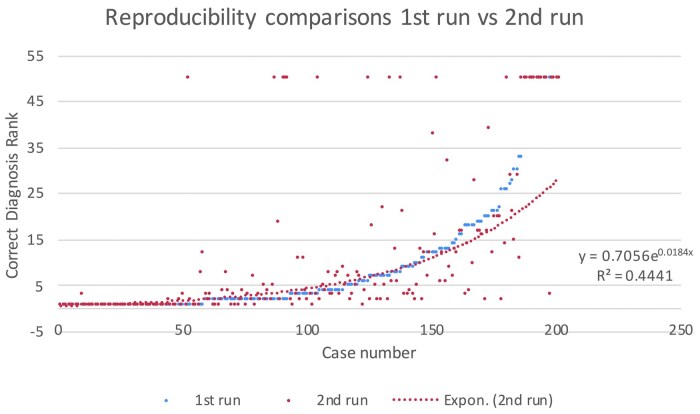
目的:思考树提示和重新考虑Isabel Pro的差异是否能提高ChatGPT-4的准确性;增加专家小组的规模是否能提高ChatGPT-4的准确性?ChatGPT-4是否在顺序请求中产生一致的输出;捏造参考文献的频率是多少?材料和方法:计算机诊断决策支持系统Isabel Pro和大型语言模型ChatGPT-4。使用来自《新英格兰医学杂志》(New England Journal of Medicine)的201例病例,每个系统都根据可能性进行了分类诊断。统计为平均互惠等级、等级召回率、平均等级、正确诊断数和等级改善。为了再现性,该研究比较了最初的专家小组运行和每次后续运行,使用从每次运行的散点图中计算的r平方。结果:ChatGPT-4提高了MRR和召回率在10到0.72之间,但产生的正确诊断较少,平均排名较低。重新考虑伊莎贝尔Pro的差异使召回率提高了10%(11%)。两个专家小组的规模产生了最好的结果。在召回率为10时,重复性运行平均在4%以内,但散点图显示r平方范围为0.44 ~ 034,表明重复性较差。引文的参考文献准确率为34.8%,doi的参考文献准确率为37.8%。讨论:ChatGPT-4在图像和心电图以及行政实践管理方面表现良好,但诊断尚未被证明有希望。结论:如上所述,结果表明了对诊断准确性、可重复性和参考文献引用准确性的关注。在这些问题得到解决之前,临床诊断的使用将是最小的,如果有的话。
Computerized diagnostic decision support systems-Isabel Pro versus ChatGPT-4 part II.
Objective: Does a Tree-of-Thought prompt and reconsideration of Isabel Pro's differential improve ChatGPT-4's accuracy; does increasing expert panel size improve ChatGPT-4's accuracy; does ChatGPT-4 produce consistent outputs in sequential requests; what is the frequency of fabricated references?
Materials and methods: Isabel Pro, a computerized diagnostic decision support system, and ChatGPT-4, a large language model. Using 201 cases from the New England Journal of Medicine, each system produced a differential diagnosis ranked by likelihood. Statistics were Mean Reciprocal Rank, Recall at Rank, Average Rank, Number of Correct Diagnoses, and Rank Improvement. For reproducibility, the study compared the initial expert panel run to each subsequent run, using the r-squared calculation from a scatter plot of each run.
Results: ChatGPT-4 improved MRR and Recall at 10 to 0.72 but produced fewer correct diagnoses and lower average rank. Reconsideration of the Isabel Pro differential produced an improvement in Recall at 10 of 11%. The expert panel size of two produced the best result. The reproducibility runs were within 4% on average for Recall at 10, but the scatterplots showed an r-squared ranging from 0.44 to 034, suggesting poor reproducibility. Reference accuracy was 34.8% for citations and 37.8% for DOIs.
Discussion: ChatGPT-4 performs well with images and electrocardiography and in administrative practice management, but diagnosis has not proven as promising.
Conclusions: As noted above, the results demonstrate concerns for diagnostic accuracy, reproducibility, and reference citation accuracy. Until these issues are resolved, clinical usage for diagnosis will be minimal, if at all.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


