在电子健康记录中建立疾病表型的概率方法。
IF 6.1
3区 生物学
Q1 MATHEMATICAL & COMPUTATIONAL BIOLOGY
引用次数: 0
摘要
本文章由计算机程序翻译,如有差异,请以英文原文为准。
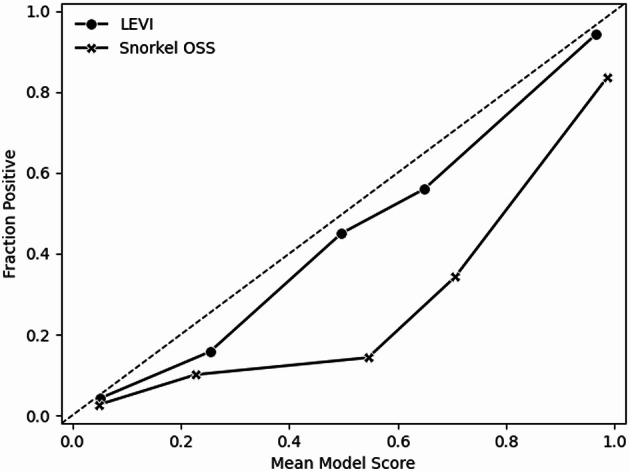
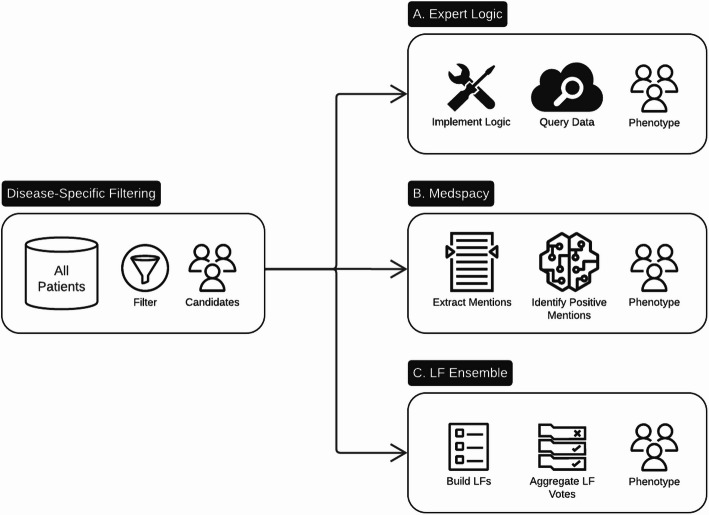
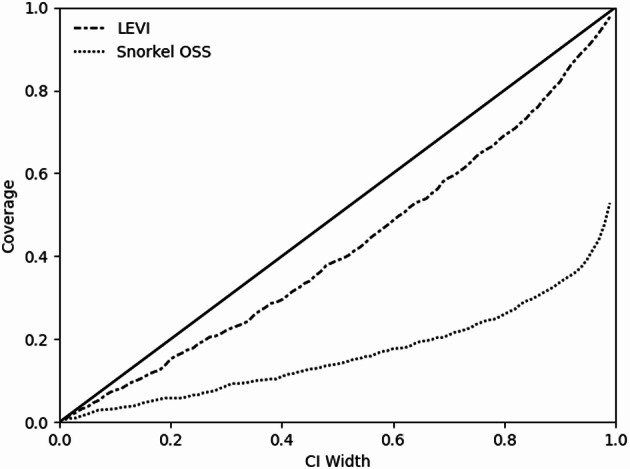
A probabilistic approach for building disease phenotypes across electronic health records.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Biodata Mining
MATHEMATICAL & COMPUTATIONAL BIOLOGY-
CiteScore
7.90
自引率
0.00%
发文量
28
审稿时长
23 weeks
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


