Diego A Forero, Sandra E Abreu, Blanca E Tovar, Marilyn H Oermann
{"title":"大型语言模型和系统评论和评论概述(PRISMA 2020和PRIOR)中遵守报告指南的分析。","authors":"Diego A Forero, Sandra E Abreu, Blanca E Tovar, Marilyn H Oermann","doi":"10.1007/s10916-025-02212-0","DOIUrl":null,"url":null,"abstract":"<p><p>In the context of Evidence-Based Practice (EBP), Systematic Reviews (SRs), Meta-Analyses (MAs) and overview of reviews have become cornerstones for the synthesis of research findings. The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 and Preferred Reporting Items for Overviews of Reviews (PRIOR) statements have become major reporting guidelines for SRs/MAs and for overviews of reviews, respectively. In recent years, advances in Generative Artificial Intelligence (genAI) have been proposed as a potential major paradigm shift in scientific research. The main aim of this research was to examine the performance of four LLMs for the analysis of adherence to PRISMA 2020 and PRIOR, in a sample of 20 SRs and 20 overviews of reviews. We tested the free versions of four commonly used LLMs: ChatGPT (GPT-4o), DeepSeek (V3), Gemini (2.0 Flash) and Qwen (2.5 Max). Adherence to PRISMA 2020 and PRIOR was compared with scores defined previously by human experts, using several statistical tests. In our results, all the four LLMs showed a low performance for the analysis of adherence to PRISMA 2020, overestimating the percentage of adherence (from 23 to 30%). For PRIOR, the LLMs presented lower differences in the estimation of adherence (from 6 to 14%) and ChatGPT showed a performance similar to human experts. This is the first report of the performance of four commonly used LLMs for the analysis of adherence to PRISMA 2020 and PRIOR. Future studies of adherence to other reporting guidelines will be helpful in health sciences research.</p>","PeriodicalId":16338,"journal":{"name":"Journal of Medical Systems","volume":"49 1","pages":"80"},"PeriodicalIF":5.7000,"publicationDate":"2025-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12162794/pdf/","citationCount":"0","resultStr":"{\"title\":\"Large Language Models and the Analyses of Adherence to Reporting Guidelines in Systematic Reviews and Overviews of Reviews (PRISMA 2020 and PRIOR).\",\"authors\":\"Diego A Forero, Sandra E Abreu, Blanca E Tovar, Marilyn H Oermann\",\"doi\":\"10.1007/s10916-025-02212-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In the context of Evidence-Based Practice (EBP), Systematic Reviews (SRs), Meta-Analyses (MAs) and overview of reviews have become cornerstones for the synthesis of research findings. The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 and Preferred Reporting Items for Overviews of Reviews (PRIOR) statements have become major reporting guidelines for SRs/MAs and for overviews of reviews, respectively. In recent years, advances in Generative Artificial Intelligence (genAI) have been proposed as a potential major paradigm shift in scientific research. The main aim of this research was to examine the performance of four LLMs for the analysis of adherence to PRISMA 2020 and PRIOR, in a sample of 20 SRs and 20 overviews of reviews. We tested the free versions of four commonly used LLMs: ChatGPT (GPT-4o), DeepSeek (V3), Gemini (2.0 Flash) and Qwen (2.5 Max). Adherence to PRISMA 2020 and PRIOR was compared with scores defined previously by human experts, using several statistical tests. In our results, all the four LLMs showed a low performance for the analysis of adherence to PRISMA 2020, overestimating the percentage of adherence (from 23 to 30%). For PRIOR, the LLMs presented lower differences in the estimation of adherence (from 6 to 14%) and ChatGPT showed a performance similar to human experts. This is the first report of the performance of four commonly used LLMs for the analysis of adherence to PRISMA 2020 and PRIOR. Future studies of adherence to other reporting guidelines will be helpful in health sciences research.</p>\",\"PeriodicalId\":16338,\"journal\":{\"name\":\"Journal of Medical Systems\",\"volume\":\"49 1\",\"pages\":\"80\"},\"PeriodicalIF\":5.7000,\"publicationDate\":\"2025-06-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12162794/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Medical Systems\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1007/s10916-025-02212-0\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Systems","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s10916-025-02212-0","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Large Language Models and the Analyses of Adherence to Reporting Guidelines in Systematic Reviews and Overviews of Reviews (PRISMA 2020 and PRIOR).
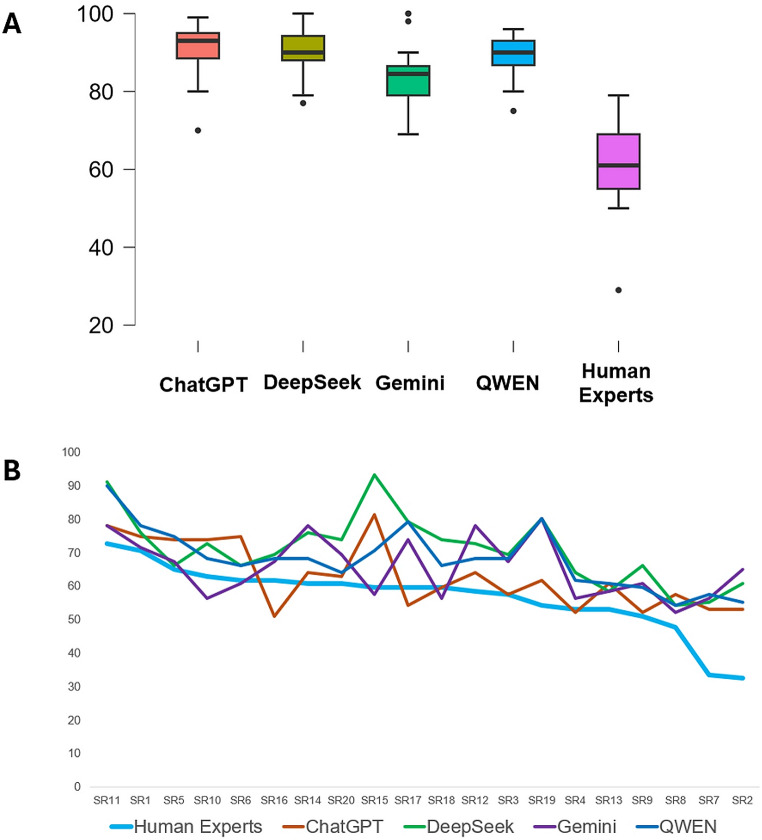
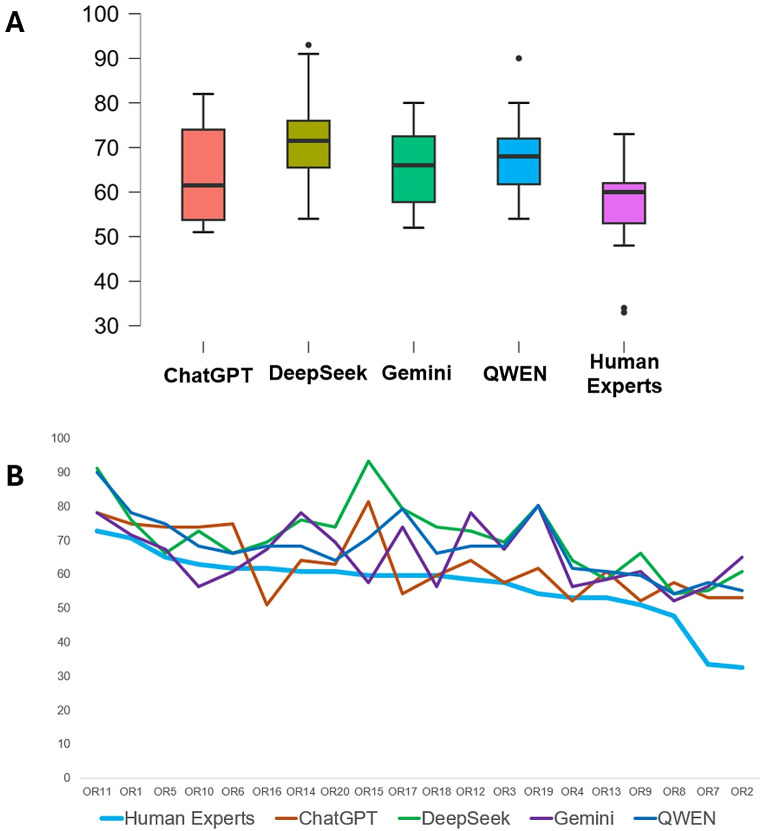
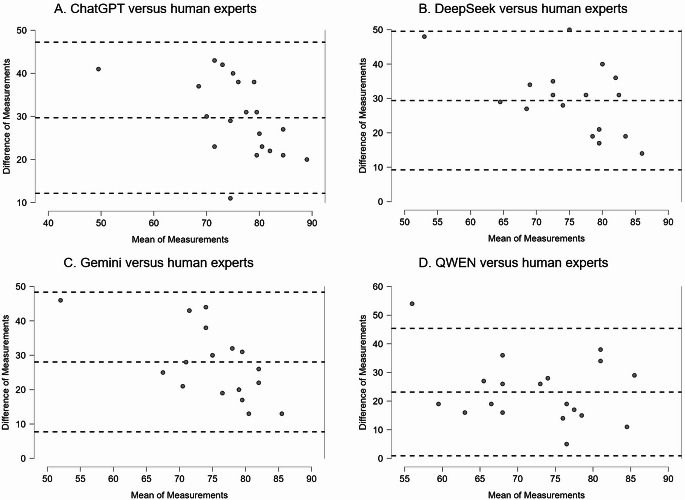
In the context of Evidence-Based Practice (EBP), Systematic Reviews (SRs), Meta-Analyses (MAs) and overview of reviews have become cornerstones for the synthesis of research findings. The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 and Preferred Reporting Items for Overviews of Reviews (PRIOR) statements have become major reporting guidelines for SRs/MAs and for overviews of reviews, respectively. In recent years, advances in Generative Artificial Intelligence (genAI) have been proposed as a potential major paradigm shift in scientific research. The main aim of this research was to examine the performance of four LLMs for the analysis of adherence to PRISMA 2020 and PRIOR, in a sample of 20 SRs and 20 overviews of reviews. We tested the free versions of four commonly used LLMs: ChatGPT (GPT-4o), DeepSeek (V3), Gemini (2.0 Flash) and Qwen (2.5 Max). Adherence to PRISMA 2020 and PRIOR was compared with scores defined previously by human experts, using several statistical tests. In our results, all the four LLMs showed a low performance for the analysis of adherence to PRISMA 2020, overestimating the percentage of adherence (from 23 to 30%). For PRIOR, the LLMs presented lower differences in the estimation of adherence (from 6 to 14%) and ChatGPT showed a performance similar to human experts. This is the first report of the performance of four commonly used LLMs for the analysis of adherence to PRISMA 2020 and PRIOR. Future studies of adherence to other reporting guidelines will be helpful in health sciences research.
期刊介绍:
Journal of Medical Systems provides a forum for the presentation and discussion of the increasingly extensive applications of new systems techniques and methods in hospital clinic and physician''s office administration; pathology radiology and pharmaceutical delivery systems; medical records storage and retrieval; and ancillary patient-support systems. The journal publishes informative articles essays and studies across the entire scale of medical systems from large hospital programs to novel small-scale medical services. Education is an integral part of this amalgamation of sciences and selected articles are published in this area. Since existing medical systems are constantly being modified to fit particular circumstances and to solve specific problems the journal includes a special section devoted to status reports on current installations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


