John D Milner, Matthew S Quinn, Phillip Schmitt, Ashley Knebel, Jeffrey Henstenburg, Adam Nasreddine, Alexandre R Boulos, Jonathan R Schiller, Craig P Eberson, Aristides I Cruz
{"title":"人工智能在解决儿童肱骨髁上骨折治疗问题中的应用。","authors":"John D Milner, Matthew S Quinn, Phillip Schmitt, Ashley Knebel, Jeffrey Henstenburg, Adam Nasreddine, Alexandre R Boulos, Jonathan R Schiller, Craig P Eberson, Aristides I Cruz","doi":"10.1016/j.jposna.2025.100164","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The vast accessibility of artificial intelligence (AI) has enabled its utilization in medicine to improve patient education, augment patient-physician communications, support research efforts, and enhance medical student education. However, there is significant concern that these models may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making. Currently, there is a paucity of literature comparing the quality and reliability of AI-generated responses. The purpose of this study was to assess the ability of ChatGPT and Gemini to generate reponses to the 2022 American Academy of Orthopaedic Surgeons' (AAOS) current practice guidlines on pediatric supracondylar humerus fractures. We hypothesized that both ChatGPT and Gemini would demonstrate high-quality, evidence-based responses with no significant difference between the models across evaluation criteria.</p><p><strong>Methods: </strong>The responses from ChatGPT and Gemini to responses based on the 14 AAOS guidelines were evaluated by seven fellowship-trained pediatric orthopaedic surgeons using a questionnaire to assess five key characteristics on a scale from 1 to 5. The prompts were categorized into nonoperative or preoperative management and diagnosis, surgical timing and technique, and rehabilitation and prevention. Statistical analysis included mean scoring, standard deviation, and two-sided t-tests to compare the performance between ChatGPT and Gemini. Scores were then evaluated for inter-rater reliability.</p><p><strong>Results: </strong>ChatGPT and Gemini demonstrated consistent performance across the criteria, with high mean scores across all criteria except for evidence-based responses. Mean scores were highest for clarity (ChatGPT: 3.745 ± 0.237, Gemini 4.388 ± 0.154) and lowest for evidence-based responses (ChatGPT: 1.816 ± 0.181, Gemini: 3.765 ± 0.229). There were notable statistically significant differences across all criteria, with Gemini having higher mean scores in each criterion (<i>P</i> < .001). Gemini achieved statistically higher ratings in the relevance (<i>P</i> = .03) and evidence-based (<i>P</i> < .001) criteria. Both large language models (LLMs) performed comparably in the accuracy, clarity, and completeness criteria (<i>P</i> > .05).</p><p><strong>Conclusions: </strong>ChatGPT and Gemini produced responses aligned with the 2022 AAOS current guideline practices for pediatric supracondylar humerus fractures. Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category. This study emphasizes the potential for LLMs, particularly Gemini, to provide pertinent clinical information for managing pediatric supracondylar humerus fractures.</p><p><strong>Key concepts: </strong>(1)The accessibility of artificial intelligence has enabled its utilization in medicine to improve patient education, support research efforts, enhance medical student education, and augment patient-physician communications.(2)There is a significant concern that artificial intelligence may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making.(3)There is a paucity of literature comparing the quality and reliability of AI-generated responses regarding management of pediatric supracondylar humerus fractures.(4)In our study, both ChatGPT and Gemini produced responses that were well aligned with the AAOS current guideline practices for pediatric supracondylar humerus fractures; however, Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category.</p><p><strong>Level of evidence: </strong>Level II.</p>","PeriodicalId":520850,"journal":{"name":"Journal of the Pediatric Orthopaedic Society of North America","volume":"11 ","pages":"100164"},"PeriodicalIF":0.0000,"publicationDate":"2025-03-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12088213/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of Artificial Intelligence in Addressing Questions Regarding the Management of Pediatric Supracondylar Humerus Fractures.\",\"authors\":\"John D Milner, Matthew S Quinn, Phillip Schmitt, Ashley Knebel, Jeffrey Henstenburg, Adam Nasreddine, Alexandre R Boulos, Jonathan R Schiller, Craig P Eberson, Aristides I Cruz\",\"doi\":\"10.1016/j.jposna.2025.100164\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The vast accessibility of artificial intelligence (AI) has enabled its utilization in medicine to improve patient education, augment patient-physician communications, support research efforts, and enhance medical student education. However, there is significant concern that these models may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making. Currently, there is a paucity of literature comparing the quality and reliability of AI-generated responses. The purpose of this study was to assess the ability of ChatGPT and Gemini to generate reponses to the 2022 American Academy of Orthopaedic Surgeons' (AAOS) current practice guidlines on pediatric supracondylar humerus fractures. We hypothesized that both ChatGPT and Gemini would demonstrate high-quality, evidence-based responses with no significant difference between the models across evaluation criteria.</p><p><strong>Methods: </strong>The responses from ChatGPT and Gemini to responses based on the 14 AAOS guidelines were evaluated by seven fellowship-trained pediatric orthopaedic surgeons using a questionnaire to assess five key characteristics on a scale from 1 to 5. The prompts were categorized into nonoperative or preoperative management and diagnosis, surgical timing and technique, and rehabilitation and prevention. Statistical analysis included mean scoring, standard deviation, and two-sided t-tests to compare the performance between ChatGPT and Gemini. Scores were then evaluated for inter-rater reliability.</p><p><strong>Results: </strong>ChatGPT and Gemini demonstrated consistent performance across the criteria, with high mean scores across all criteria except for evidence-based responses. Mean scores were highest for clarity (ChatGPT: 3.745 ± 0.237, Gemini 4.388 ± 0.154) and lowest for evidence-based responses (ChatGPT: 1.816 ± 0.181, Gemini: 3.765 ± 0.229). There were notable statistically significant differences across all criteria, with Gemini having higher mean scores in each criterion (<i>P</i> < .001). Gemini achieved statistically higher ratings in the relevance (<i>P</i> = .03) and evidence-based (<i>P</i> < .001) criteria. Both large language models (LLMs) performed comparably in the accuracy, clarity, and completeness criteria (<i>P</i> > .05).</p><p><strong>Conclusions: </strong>ChatGPT and Gemini produced responses aligned with the 2022 AAOS current guideline practices for pediatric supracondylar humerus fractures. Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category. This study emphasizes the potential for LLMs, particularly Gemini, to provide pertinent clinical information for managing pediatric supracondylar humerus fractures.</p><p><strong>Key concepts: </strong>(1)The accessibility of artificial intelligence has enabled its utilization in medicine to improve patient education, support research efforts, enhance medical student education, and augment patient-physician communications.(2)There is a significant concern that artificial intelligence may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making.(3)There is a paucity of literature comparing the quality and reliability of AI-generated responses regarding management of pediatric supracondylar humerus fractures.(4)In our study, both ChatGPT and Gemini produced responses that were well aligned with the AAOS current guideline practices for pediatric supracondylar humerus fractures; however, Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category.</p><p><strong>Level of evidence: </strong>Level II.</p>\",\"PeriodicalId\":520850,\"journal\":{\"name\":\"Journal of the Pediatric Orthopaedic Society of North America\",\"volume\":\"11 \",\"pages\":\"100164\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-03-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12088213/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of the Pediatric Orthopaedic Society of North America\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1016/j.jposna.2025.100164\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/5/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the Pediatric Orthopaedic Society of North America","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.jposna.2025.100164","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/5/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
背景:人工智能(AI)的广泛可及性使其在医学上的应用能够改善患者教育,增强患者与医生的沟通,支持研究工作,并加强医学生教育。然而,值得关注的是,这些模型可能会提供不正确、有偏见或缺乏最佳临床决策所需的细微差别和复杂性的反应。目前,比较人工智能生成的回答的质量和可靠性的文献很少。本研究的目的是评估ChatGPT和Gemini对2022年美国骨科学会(AAOS)现行儿童肱骨髁上骨折实践指南的反应能力。我们假设ChatGPT和Gemini都将表现出高质量的、基于证据的反应,在不同评估标准的模型之间没有显著差异。方法:ChatGPT和Gemini对基于14项AAOS指南的回复进行评估,由7名接受过奖学金培训的儿科骨科医生使用问卷对5个关键特征进行评估,评分范围从1到5。提示分为非手术或术前管理和诊断、手术时机和技术、康复和预防。统计分析包括平均评分、标准差和双侧t检验来比较ChatGPT和Gemini的性能。然后评估评分者之间的信度。结果:ChatGPT和Gemini在所有标准中表现一致,除了基于证据的反应外,在所有标准中都有很高的平均得分。平均得分最高的是清晰性(ChatGPT: 3.745±0.237,Gemini: 4.388±0.154),最低的是循证反应(ChatGPT: 1.816±0.181,Gemini: 3.765±0.229)。在所有标准上有显著的统计学差异,双子星在每个标准上的平均得分更高(P P = 0.03),循证(P P = 0.05)。结论:ChatGPT和Gemini的治疗效果与2022年AAOS关于儿童肱骨髁上骨折的现行指南一致。Gemini在所有标准上都优于ChatGPT,在基于证据的类别中得分差异最大。本研究强调llm的潜力,特别是双子座,为治疗儿童肱骨髁上骨折提供相关的临床信息。关键概念:(1)人工智能的可及性使其在医学上的应用能够改善患者教育,支持研究工作,加强医学生教育,并增加医患沟通。(2)人工智能可能提供不正确,有偏见,(3)比较人工智能生成的儿童肱骨髁上骨折治疗响应的质量和可靠性的文献很少。(4)在我们的研究中,ChatGPT和Gemini生成的响应都与AAOS目前的儿童肱骨髁上骨折指南实践非常一致;然而,Gemini在所有标准上都优于ChatGPT,在基于证据的类别中得分差异最大。证据等级:二级。
Performance of Artificial Intelligence in Addressing Questions Regarding the Management of Pediatric Supracondylar Humerus Fractures.
Background: The vast accessibility of artificial intelligence (AI) has enabled its utilization in medicine to improve patient education, augment patient-physician communications, support research efforts, and enhance medical student education. However, there is significant concern that these models may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making. Currently, there is a paucity of literature comparing the quality and reliability of AI-generated responses. The purpose of this study was to assess the ability of ChatGPT and Gemini to generate reponses to the 2022 American Academy of Orthopaedic Surgeons' (AAOS) current practice guidlines on pediatric supracondylar humerus fractures. We hypothesized that both ChatGPT and Gemini would demonstrate high-quality, evidence-based responses with no significant difference between the models across evaluation criteria.
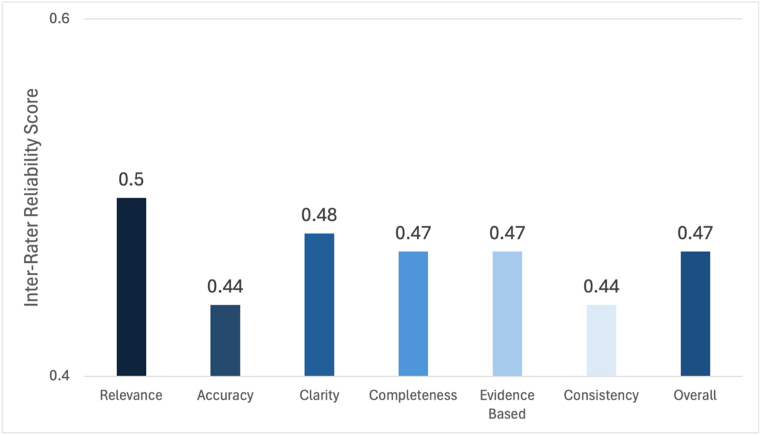
Methods: The responses from ChatGPT and Gemini to responses based on the 14 AAOS guidelines were evaluated by seven fellowship-trained pediatric orthopaedic surgeons using a questionnaire to assess five key characteristics on a scale from 1 to 5. The prompts were categorized into nonoperative or preoperative management and diagnosis, surgical timing and technique, and rehabilitation and prevention. Statistical analysis included mean scoring, standard deviation, and two-sided t-tests to compare the performance between ChatGPT and Gemini. Scores were then evaluated for inter-rater reliability.
Results: ChatGPT and Gemini demonstrated consistent performance across the criteria, with high mean scores across all criteria except for evidence-based responses. Mean scores were highest for clarity (ChatGPT: 3.745 ± 0.237, Gemini 4.388 ± 0.154) and lowest for evidence-based responses (ChatGPT: 1.816 ± 0.181, Gemini: 3.765 ± 0.229). There were notable statistically significant differences across all criteria, with Gemini having higher mean scores in each criterion (P < .001). Gemini achieved statistically higher ratings in the relevance (P = .03) and evidence-based (P < .001) criteria. Both large language models (LLMs) performed comparably in the accuracy, clarity, and completeness criteria (P > .05).
Conclusions: ChatGPT and Gemini produced responses aligned with the 2022 AAOS current guideline practices for pediatric supracondylar humerus fractures. Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category. This study emphasizes the potential for LLMs, particularly Gemini, to provide pertinent clinical information for managing pediatric supracondylar humerus fractures.
Key concepts: (1)The accessibility of artificial intelligence has enabled its utilization in medicine to improve patient education, support research efforts, enhance medical student education, and augment patient-physician communications.(2)There is a significant concern that artificial intelligence may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making.(3)There is a paucity of literature comparing the quality and reliability of AI-generated responses regarding management of pediatric supracondylar humerus fractures.(4)In our study, both ChatGPT and Gemini produced responses that were well aligned with the AAOS current guideline practices for pediatric supracondylar humerus fractures; however, Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


