Pubudu Saneth Samarakoon, Ghislain Fournous, Lars T Hansen, Ashen Wijesiri, Sen Zhao, Rodriguez Alex A, Tarak Nath Nandi, Ravi Madduri, Alexander D Rowe, Gard Thomassen, Eivind Hovig, Sabry Razick
{"title":"对标加速下一代测序分析管道。","authors":"Pubudu Saneth Samarakoon, Ghislain Fournous, Lars T Hansen, Ashen Wijesiri, Sen Zhao, Rodriguez Alex A, Tarak Nath Nandi, Ravi Madduri, Alexander D Rowe, Gard Thomassen, Eivind Hovig, Sabry Razick","doi":"10.1093/bioadv/vbaf085","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Industry-standard central processing unit (CPU)-based next-generation sequencing (NGS) analysis tools have led to longer runtimes, affecting their utility in time-sensitive clinical practices and population-scale research studies. To address this, researchers have developed accelerated NGS platforms like DRAGEN and Parabricks, which have significantly reduced runtimes-from days to hours. However, these studies have evaluated accelerated platforms independently without sufficiently assessing computational resource usage or thoroughly investigating speedup scalability, a gap our study is designed to address.</p><p><strong>Results: </strong>Corroborating previous studies, accelerated pipelines demonstrated shorter runtimes than CPU-only approaches, with Parabricks-H100 demonstrating the highest speedups, followed by DRAGEN. In mapping, DRAGEN outperformed Parabricks (L4 and A100) and matched H100 speedups. Parabricks (A100 and H100) variant calling demonstrated higher speedups than DRAGEN. Moreover, DRAGEN and Parabricks-H100 mapping showed positive trends in the coverage-based scalability analysis, while other configurations failed to scale effectively. Our profiler analysis provided new insights into the relationships between Parabricks' performances and resource usage patterns, revealing its potential for further improvements. Our findings and cost comparison help researchers select accelerated platforms based on coverage needs, timeframes, and budget, while suggesting optimization strategies.</p><p><strong>Availability and implementation: </strong>Datasets are described in the 'Data availability' section. Our NGS pipelines are available at https://github.com/NAICNO/accelerated_genomics.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf085"},"PeriodicalIF":2.8000,"publicationDate":"2025-05-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12092081/pdf/","citationCount":"0","resultStr":"{\"title\":\"Benchmarking accelerated next-generation sequencing analysis pipelines.\",\"authors\":\"Pubudu Saneth Samarakoon, Ghislain Fournous, Lars T Hansen, Ashen Wijesiri, Sen Zhao, Rodriguez Alex A, Tarak Nath Nandi, Ravi Madduri, Alexander D Rowe, Gard Thomassen, Eivind Hovig, Sabry Razick\",\"doi\":\"10.1093/bioadv/vbaf085\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>Industry-standard central processing unit (CPU)-based next-generation sequencing (NGS) analysis tools have led to longer runtimes, affecting their utility in time-sensitive clinical practices and population-scale research studies. To address this, researchers have developed accelerated NGS platforms like DRAGEN and Parabricks, which have significantly reduced runtimes-from days to hours. However, these studies have evaluated accelerated platforms independently without sufficiently assessing computational resource usage or thoroughly investigating speedup scalability, a gap our study is designed to address.</p><p><strong>Results: </strong>Corroborating previous studies, accelerated pipelines demonstrated shorter runtimes than CPU-only approaches, with Parabricks-H100 demonstrating the highest speedups, followed by DRAGEN. In mapping, DRAGEN outperformed Parabricks (L4 and A100) and matched H100 speedups. Parabricks (A100 and H100) variant calling demonstrated higher speedups than DRAGEN. Moreover, DRAGEN and Parabricks-H100 mapping showed positive trends in the coverage-based scalability analysis, while other configurations failed to scale effectively. Our profiler analysis provided new insights into the relationships between Parabricks' performances and resource usage patterns, revealing its potential for further improvements. Our findings and cost comparison help researchers select accelerated platforms based on coverage needs, timeframes, and budget, while suggesting optimization strategies.</p><p><strong>Availability and implementation: </strong>Datasets are described in the 'Data availability' section. Our NGS pipelines are available at https://github.com/NAICNO/accelerated_genomics.</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"5 1\",\"pages\":\"vbaf085\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2025-05-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12092081/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbaf085\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf085","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
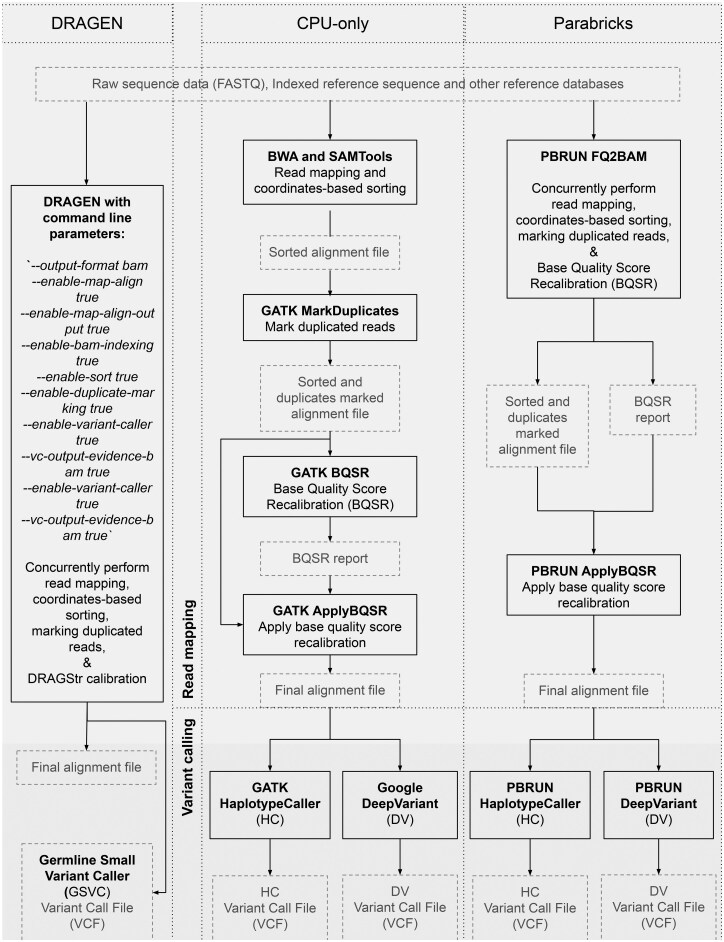
Motivation: Industry-standard central processing unit (CPU)-based next-generation sequencing (NGS) analysis tools have led to longer runtimes, affecting their utility in time-sensitive clinical practices and population-scale research studies. To address this, researchers have developed accelerated NGS platforms like DRAGEN and Parabricks, which have significantly reduced runtimes-from days to hours. However, these studies have evaluated accelerated platforms independently without sufficiently assessing computational resource usage or thoroughly investigating speedup scalability, a gap our study is designed to address.
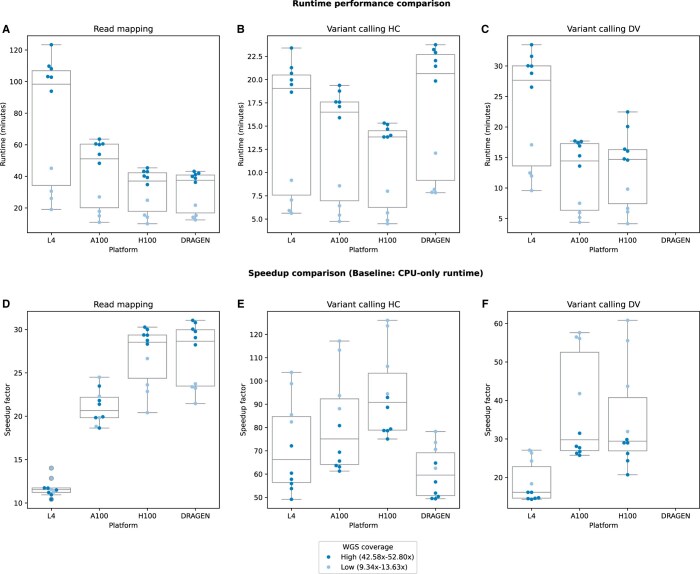
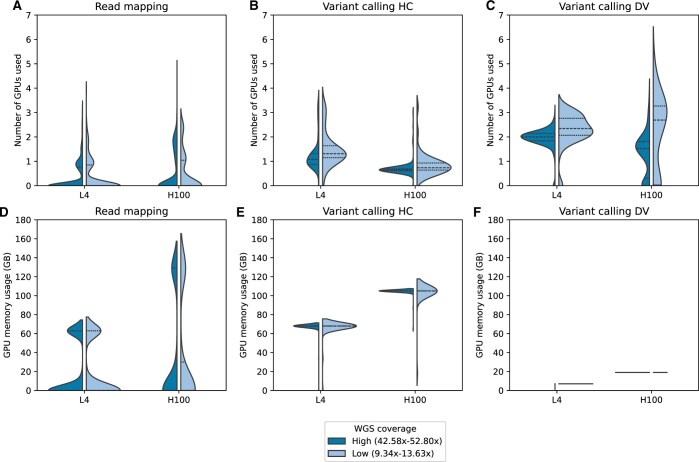
Results: Corroborating previous studies, accelerated pipelines demonstrated shorter runtimes than CPU-only approaches, with Parabricks-H100 demonstrating the highest speedups, followed by DRAGEN. In mapping, DRAGEN outperformed Parabricks (L4 and A100) and matched H100 speedups. Parabricks (A100 and H100) variant calling demonstrated higher speedups than DRAGEN. Moreover, DRAGEN and Parabricks-H100 mapping showed positive trends in the coverage-based scalability analysis, while other configurations failed to scale effectively. Our profiler analysis provided new insights into the relationships between Parabricks' performances and resource usage patterns, revealing its potential for further improvements. Our findings and cost comparison help researchers select accelerated platforms based on coverage needs, timeframes, and budget, while suggesting optimization strategies.
Availability and implementation: Datasets are described in the 'Data availability' section. Our NGS pipelines are available at https://github.com/NAICNO/accelerated_genomics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


