LARE:基于区域嵌入的视觉语言模型的潜在增强
IF 4.9
引用次数: 0
摘要
近年来,人们对同时处理图像和文本数据的视觉语言模型(VLMs)进行了大量的研究;这些模型被应用于不同的下游任务,例如“与图像相关的聊天”、“通过指令进行图像识别”和“回答视觉问题”。视觉语言模型,如对比语言图像预训练(CLIP),也是高性能的图像分类器,并且正在发展成可以利用语言信息扩展到未知领域的领域适应方法。然而,由于这些vlm将图像作为单个点嵌入到统一的嵌入空间中,因此它们不能充分利用大规模视觉语言模型的不同域性能。因此,在本研究中,我们提出了使用区域嵌入(LARE)的潜在增强方法,将图像作为一个区域嵌入到VLM学习到的统一嵌入空间中。通过从该潜在区域内对增强图像嵌入进行采样,LARE可以将数据增强到各种不可见域,而不仅仅是特定的不可见域。LARE通过增强图像嵌入来微调VLMs,实现了内外域的鲁棒图像分类。我们在三个基准上证明了LARE在图像分类精度方面优于以前的微调模型。我们还证明了LARE是一个更健壮和通用的模型,在多种条件下有效,例如不可见的域、少量数据和不平衡数据。本文章由计算机程序翻译,如有差异,请以英文原文为准。
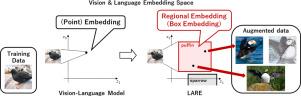
LARE: Latent augmentation using regional embedding with vision-language model
In recent years, considerable research has been conducted on vision-language models (VLMs) that handle both image and text data; these models are being applied to diverse downstream tasks, such as “image-related chat,” “image recognition by instruction,” and “answering visual questions.” Vision-language models, such as Contrastive Language–Image Pre-training (CLIP), are also high-performance image classifiers, and are being developed into domain adaptation methods that can utilize language information to extend into unseen domains. However, because these VLMs embed images as a single point in a unified embedding space, they do not fully exploit the diverse domain performance of large-scale vision-language models. Therefore, in this study, we proposed the Latent Augmentation using Regional Embedding (LARE), which embeds the image as a region in the unified embedding space learned by the VLM. By sampling the augmented image embeddings from within this latent region, LARE enables data augmentation to various unseen domains, not just to specific unseen domains. LARE achieves robust image classification for domains in and out using augmented image embeddings to fine-tune VLMs. We demonstrate that LARE outperforms previous fine-tuning models in terms of image classification accuracy on three benchmarks. We also demonstrate that LARE is a more robust and general model that is valid under multiple conditions, such as unseen domains, small amounts of data, and imbalanced data.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Machine learning with applications
Management Science and Operations Research, Artificial Intelligence, Computer Science Applications
自引率
0.00%
发文量
0
审稿时长
98 days
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


