Kingsley F Attai, Constance Amannah, Moses Ekpenyong, Daniel E Asuquo, Oryina K Akputu, Okure U Obot, Peterben C Ajuga, Jeremiah C Obi, Omosivie Maduka, Christie Akwaowo, Faith-Michael Uzoka
{"title":"利用随机森林、LIME和GPT开发可解释的温病移动诊断人工智能系统。","authors":"Kingsley F Attai, Constance Amannah, Moses Ekpenyong, Daniel E Asuquo, Oryina K Akputu, Okure U Obot, Peterben C Ajuga, Jeremiah C Obi, Omosivie Maduka, Christie Akwaowo, Faith-Michael Uzoka","doi":"10.4258/hir.2025.31.2.125","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>This study proposes a mobile-based explainable artificial intelligence (XAI) platform designed for diagnosing febrile illnesses.</p><p><strong>Methods: </strong>We integrated the interpretability offered by local interpretable model-agnostic explanations (LIME) and the explainability provided by generative pre-trained transformers (GPT) to bridge the gap in understanding and trust often created by machine learning models in critical healthcare decision-making. The developed system employed random forest for disease diagnosis, LIME for interpretation of the results, and GPT-3.5 for generating explanations in easy-to-understand language.</p><p><strong>Results: </strong>Our model demonstrated robust performance in detecting malaria, achieving precision, recall, and F1-scores of 85%, 91%, and 88%, respectively. It performed moderately well in detecting urinary tract and respiratory tract infections, with precision, recall, and F1-scores of 80%, 65%, and 72%, and 77%, 68%, and 72%, respectively, maintaining an effective balance between sensitivity and specificity. However, the model exhibited limitations in detecting typhoid fever and human immunodeficiency virus/acquired immune deficiency syndrome, achieving lower precision, recall, and F1-scores of 69%, 53%, and 60%, and 75%, 39%, and 51%, respectively. These results indicate missed true-positive cases, necessitating further model fine-tuning. LIME and GPT-3.5 were integrated to enhance transparency and provide natural language explanations, thereby aiding decision-making and improving user comprehension of the diagnoses.</p><p><strong>Conclusions: </strong>The LIME plots revealed key symptoms influencing the diagnoses, with bitter taste in the mouth and fever showing the highest negative influence on predictions, and GPT-3.5 provided natural language explanations that increased the reliability and trustworthiness of the system, promoting improved patient outcomes and reducing the healthcare burden.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":"31 2","pages":"125-135"},"PeriodicalIF":2.1000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12086442/pdf/","citationCount":"0","resultStr":"{\"title\":\"Developing an Explainable Artificial Intelligence System for the Mobile-Based Diagnosis of Febrile Diseases Using Random Forest, LIME, and GPT.\",\"authors\":\"Kingsley F Attai, Constance Amannah, Moses Ekpenyong, Daniel E Asuquo, Oryina K Akputu, Okure U Obot, Peterben C Ajuga, Jeremiah C Obi, Omosivie Maduka, Christie Akwaowo, Faith-Michael Uzoka\",\"doi\":\"10.4258/hir.2025.31.2.125\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>This study proposes a mobile-based explainable artificial intelligence (XAI) platform designed for diagnosing febrile illnesses.</p><p><strong>Methods: </strong>We integrated the interpretability offered by local interpretable model-agnostic explanations (LIME) and the explainability provided by generative pre-trained transformers (GPT) to bridge the gap in understanding and trust often created by machine learning models in critical healthcare decision-making. The developed system employed random forest for disease diagnosis, LIME for interpretation of the results, and GPT-3.5 for generating explanations in easy-to-understand language.</p><p><strong>Results: </strong>Our model demonstrated robust performance in detecting malaria, achieving precision, recall, and F1-scores of 85%, 91%, and 88%, respectively. It performed moderately well in detecting urinary tract and respiratory tract infections, with precision, recall, and F1-scores of 80%, 65%, and 72%, and 77%, 68%, and 72%, respectively, maintaining an effective balance between sensitivity and specificity. However, the model exhibited limitations in detecting typhoid fever and human immunodeficiency virus/acquired immune deficiency syndrome, achieving lower precision, recall, and F1-scores of 69%, 53%, and 60%, and 75%, 39%, and 51%, respectively. These results indicate missed true-positive cases, necessitating further model fine-tuning. LIME and GPT-3.5 were integrated to enhance transparency and provide natural language explanations, thereby aiding decision-making and improving user comprehension of the diagnoses.</p><p><strong>Conclusions: </strong>The LIME plots revealed key symptoms influencing the diagnoses, with bitter taste in the mouth and fever showing the highest negative influence on predictions, and GPT-3.5 provided natural language explanations that increased the reliability and trustworthiness of the system, promoting improved patient outcomes and reducing the healthcare burden.</p>\",\"PeriodicalId\":12947,\"journal\":{\"name\":\"Healthcare Informatics Research\",\"volume\":\"31 2\",\"pages\":\"125-135\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12086442/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Healthcare Informatics Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4258/hir.2025.31.2.125\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/4/30 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2025.31.2.125","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/30 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Developing an Explainable Artificial Intelligence System for the Mobile-Based Diagnosis of Febrile Diseases Using Random Forest, LIME, and GPT.
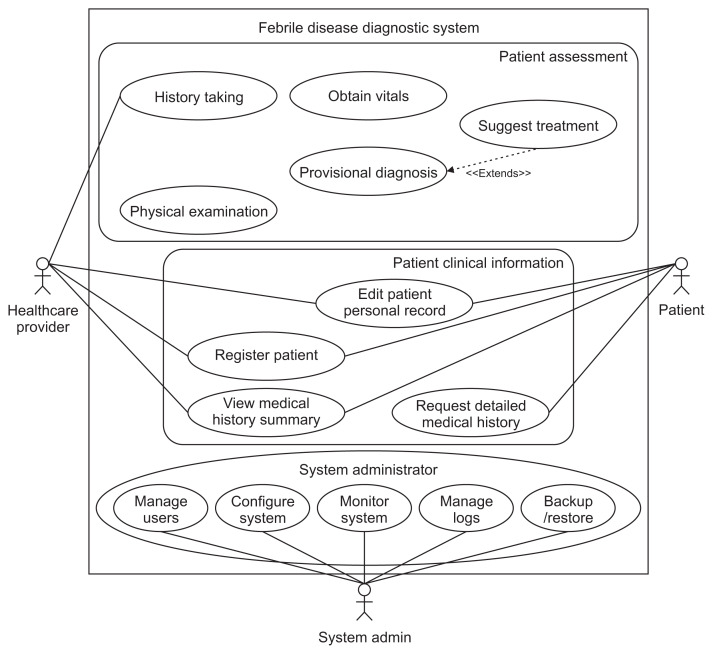
Objectives: This study proposes a mobile-based explainable artificial intelligence (XAI) platform designed for diagnosing febrile illnesses.
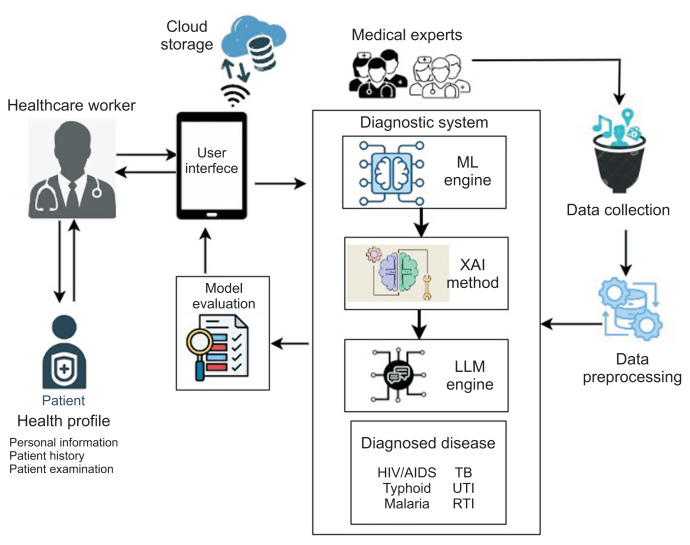
Methods: We integrated the interpretability offered by local interpretable model-agnostic explanations (LIME) and the explainability provided by generative pre-trained transformers (GPT) to bridge the gap in understanding and trust often created by machine learning models in critical healthcare decision-making. The developed system employed random forest for disease diagnosis, LIME for interpretation of the results, and GPT-3.5 for generating explanations in easy-to-understand language.
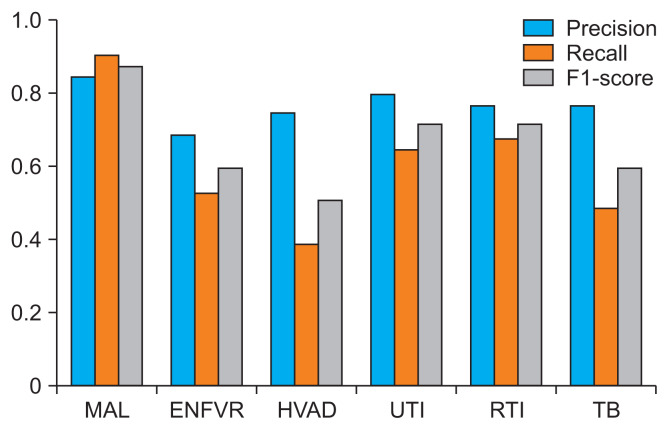
Results: Our model demonstrated robust performance in detecting malaria, achieving precision, recall, and F1-scores of 85%, 91%, and 88%, respectively. It performed moderately well in detecting urinary tract and respiratory tract infections, with precision, recall, and F1-scores of 80%, 65%, and 72%, and 77%, 68%, and 72%, respectively, maintaining an effective balance between sensitivity and specificity. However, the model exhibited limitations in detecting typhoid fever and human immunodeficiency virus/acquired immune deficiency syndrome, achieving lower precision, recall, and F1-scores of 69%, 53%, and 60%, and 75%, 39%, and 51%, respectively. These results indicate missed true-positive cases, necessitating further model fine-tuning. LIME and GPT-3.5 were integrated to enhance transparency and provide natural language explanations, thereby aiding decision-making and improving user comprehension of the diagnoses.
Conclusions: The LIME plots revealed key symptoms influencing the diagnoses, with bitter taste in the mouth and fever showing the highest negative influence on predictions, and GPT-3.5 provided natural language explanations that increased the reliability and trustworthiness of the system, promoting improved patient outcomes and reducing the healthcare burden.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


